哎哟~404了~休息一下,下面的文章你可能很感兴趣:
到目前为止,我们在使用 CQL 建表的时候使用到了一些数据类型,比如 text、timeuuid等。本文将介绍 Apache Cassandra 内置及自定义数据类型。和其他语言一样,CQL 也支持一系列灵活的数据类型,包括基本的数据类型,集合类型以及用户自定义数据类(User-Defined Types,UDTs)。下面将介绍 CQL 支持的数据类型。如果想及时了解Spark、Hadoop或 w397090770 5年前 (2019-04-15) 2168℃ 0评论2喜欢
Programming Hive: Data Warehouse and Query Language for Hadoop 1st Edition 于2012年09月出版,全书共350页,是学习Hive经典的一本书。图书信息如下:Publisher : O'Reilly Media; 1st edition (October 16, 2012)Language : EnglishPaperback : 350 pagesISBN-10 : 1449319335ISBN-13 : 978-1449319335这本指南将向您介绍 Apache Hive, 它是 Hadoop 的数据仓库基础设施。通过这本书将快速 w397090770 9年前 (2015-08-25) 38289℃ 3评论21喜欢
本文来自本人于2018年12月25日在 HBase生态+Spark社区钉钉大群直播,本群每周二下午18点-19点之间进行 HBase+Spark技术分享。加群地址:https://dwz.cn/Fvqv066s。本文 PPT 下载:关注 iteblog_hadoop 微信公众号,并回复 HBase_Rowkey 关键字获取。为什么Rowkey这么重要RowKey 到底是什么如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微 w397090770 5年前 (2018-12-25) 7350℃ 0评论29喜欢
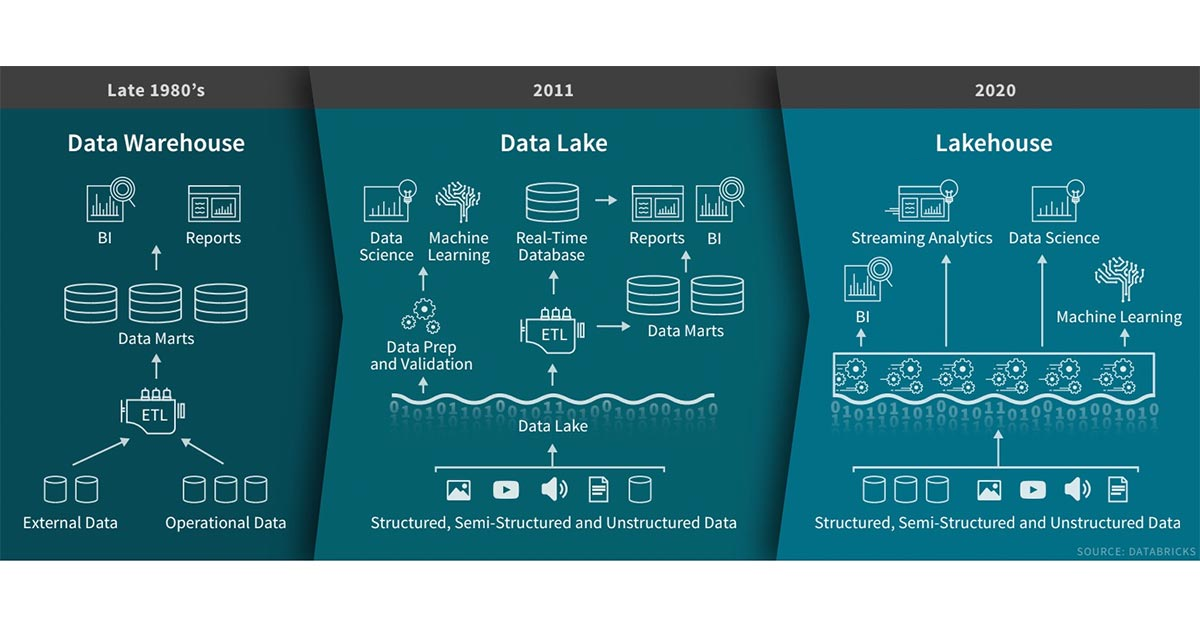
引入在Databricks的过去几年中,我们看到了一种新的数据管理范式,该范式出现在许多客户和案例中:LakeHouse。在这篇文章中,我们将描述这种新范式及其相对于先前方案的优势。数据仓库技术自1980诞生以来一直在发展,其在决策支持和商业智能应用方面拥有悠久的历史,而MPP体系结构使得系统能够处理更大数据量。但是,虽 w397090770 4年前 (2020-02-03) 2976℃ 0评论6喜欢
概论 SparkR是一个R语言包,它提供了轻量级的方式使得可以在R语言中使用Apache Spark。在Spark 1.4中,SparkR实现了分布式的data frame,支持类似查询、过滤以及聚合的操作(类似于R中的data frames:dplyr),但是这个可以操作大规模的数据集。SparkR DataFrames DataFrame是数据组织成一个带有列名称的分布式数据集。在概念上和关系 w397090770 9年前 (2015-06-09) 36536℃ 1评论50喜欢
闲来无事,于是把常用的排序算法自己写了一遍,也当做是复习一下。[code lang="CPP"]/*************************************************************** * * * * * Date : 2012. 05. 03 * * Author : 397090770 * * Email : wyphao.2007@163.com * * * * * *************************** w397090770 11年前 (2013-04-04) 3004℃ 0评论3喜欢
Apache Kafka 从 0.11.0.0 版本开始支持在消息中添加 header 信息,具体参见 KAFKA-4208。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本文将介绍如何使用 spring-kafka 在 Kafka Message 中添加或者读取自定义 headers。本文使用各个系统的版本为:Spring Kafka: 2.1.4.RELEASESpring Boot: 2.0.0.RELEASEApache Kafka: kafka w397090770 6年前 (2018-05-13) 4505℃ 0评论0喜欢
Spark目前被越来越多的企业使用,和Hadoop一样,Spark也是以作业的形式向集群提交任务,那么在内部实现Spark和Hadoop作业模型都一样吗?答案是不对的。 熟悉Hadoop的人应该都知道,用户先编写好一个程序,我们称为Mapreduce程序,一个Mapreduce程序就是一个Job,而一个Job里面可以有一个或多个Task,Task又可以区分为Map Task和Reduce T w397090770 10年前 (2014-11-11) 21075℃ 1评论34喜欢
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数# 查看物理CPU个数cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l# 查看每个物理CPU中core的个数(即核数)cat /proc/cpuinfo| grep "cpu cores"| uniq# 查看逻辑CPU的个数cat /proc/cpuinfo| grep "processor"| wc -l复制代码 查看CPU信息(型号)ca w397090770 2年前 (2021-11-01) 607℃ 0评论3喜欢
在本博客的《Spark快速入门指南(Quick Start Spark)》文章中简单地介绍了如何通过Spark shell来快速地运用API。本文将介绍如何快速地利用Spark提供的API开发Standalone模式的应用程序。Spark支持三种程序语言的开发:Scala (利用SBT进行编译), Java (利用Maven进行编译)以及Python。下面我将分别用Scala、Java和Python开发同样功能的程序:一、Scala w397090770 10年前 (2014-06-10) 16402℃ 2评论7喜欢
在Flink中我们可以很容易的使用内置的API来读取HDFS上的压缩文件,内置支持的压缩格式包括.deflate,.gz, .gzip,.bz2以及.xz等。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop但是如果我们想使用Flink内置sink API将数据以压缩的格式写入到HDFS上,好像并没有找到有API直接支持(如果不是这样的, w397090770 7年前 (2017-03-02) 10142℃ 0评论5喜欢
杭州第一次Flink Meetup会议将于2016年11月05日在杭州市滨江区江虹路410号进行,本次活动由华为杭研院承办。 Flink Meetup目前由德国柏林和英国伦敦这两个,这次活动是国内第一次Flink Meetup线下活动,开启第三个Flink Meeup活动大本营。 当下流计算系统可选的较多,Flink的性能和特性比较突出,其他流系统也各有特点。这 w397090770 8年前 (2016-10-18) 1657℃ 0评论1喜欢
过去十年,存储的速度从 50MB/s(HDD)提升到 16GB/s(NvMe);网络的速度从 1Gbps 提升到 100Gbps;但是 CPU 的主频从 2010 年的 3GHz 到现在基本不变,CPU 主频是目前数据分析的重要瓶颈。为了解决这个问题,越来越多的向量化执行引擎被开发出来。比如数砖的 Photon 、ClickHouse、Apache Doris、Intel 的 Gazelle 以及 Facebook 的 Velox(参见 《Velox 介绍 w397090770 2年前 (2022-09-29) 1618℃ 0评论2喜欢
在《在Kafka中使用Avro编码消息:Producter篇》 和 《在Kafka中使用Avro编码消息:Consumer篇》 两篇文章里面我介绍了直接使用原生的 Kafka API生成和消费 Avro 类型的编码消息,本文将继续介绍如何通过 Spark 从 Kafka 中读取这些 Avro 格式化的消息。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop其 zz~~ 7年前 (2017-09-26) 4727℃ 0评论19喜欢
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。 本文并不打算介绍ElasticSearch的概 w397090770 8年前 (2016-08-10) 36685℃ 2评论73喜欢
大家在使用Spark、MapReduce 或 Flink 的时候很可能遇到这样一种情况:Hadoop 集群使用的 JDK 版本为1.7.x,而我们自己编写的程序由于某些原因必须使用 1.7 以上版本的JDK,这时候如果我们直接使用 JDK 1.8、或 1.9 来编译我们写好的代码,然后直接提交到 YARN 上运行,这时候会遇到以下的异常:[code lang="java"]Exception in thread "main" jav w397090770 7年前 (2017-07-04) 5289℃ 1评论16喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-16) 8090℃ 2评论7喜欢
我们都知道,当我们的页面请求一个js文件、一个cs文件或者点击到其他页面,浏览器一般都会给这些请求头加上表示来源的 Referrer 字段。Referrer 在分析用户的来源时非常有用,比如大家熟悉的百度统计里面就利用到 Referrer 信息了。但是遗憾的是,目前百度统计仅仅支持来源于http页面的referrer头信息;也就是说,如果你网站是ht w397090770 7年前 (2017-01-10) 24299℃ 0评论19喜欢
在 Zookeeper 中限制 transaction log 总大小主要有两种方法。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop限制 Zookeeper Transaction Log 里面的事务条数默认情况下,在写入 snapCount(100000) 事务后,Zookeeper 事务日志将会切换。如果 Zookeeper 的数据目录的空间不足与存储三个版本的 Zookeeper Transaction Lo w397090770 4年前 (2020-10-28) 614℃ 0评论1喜欢
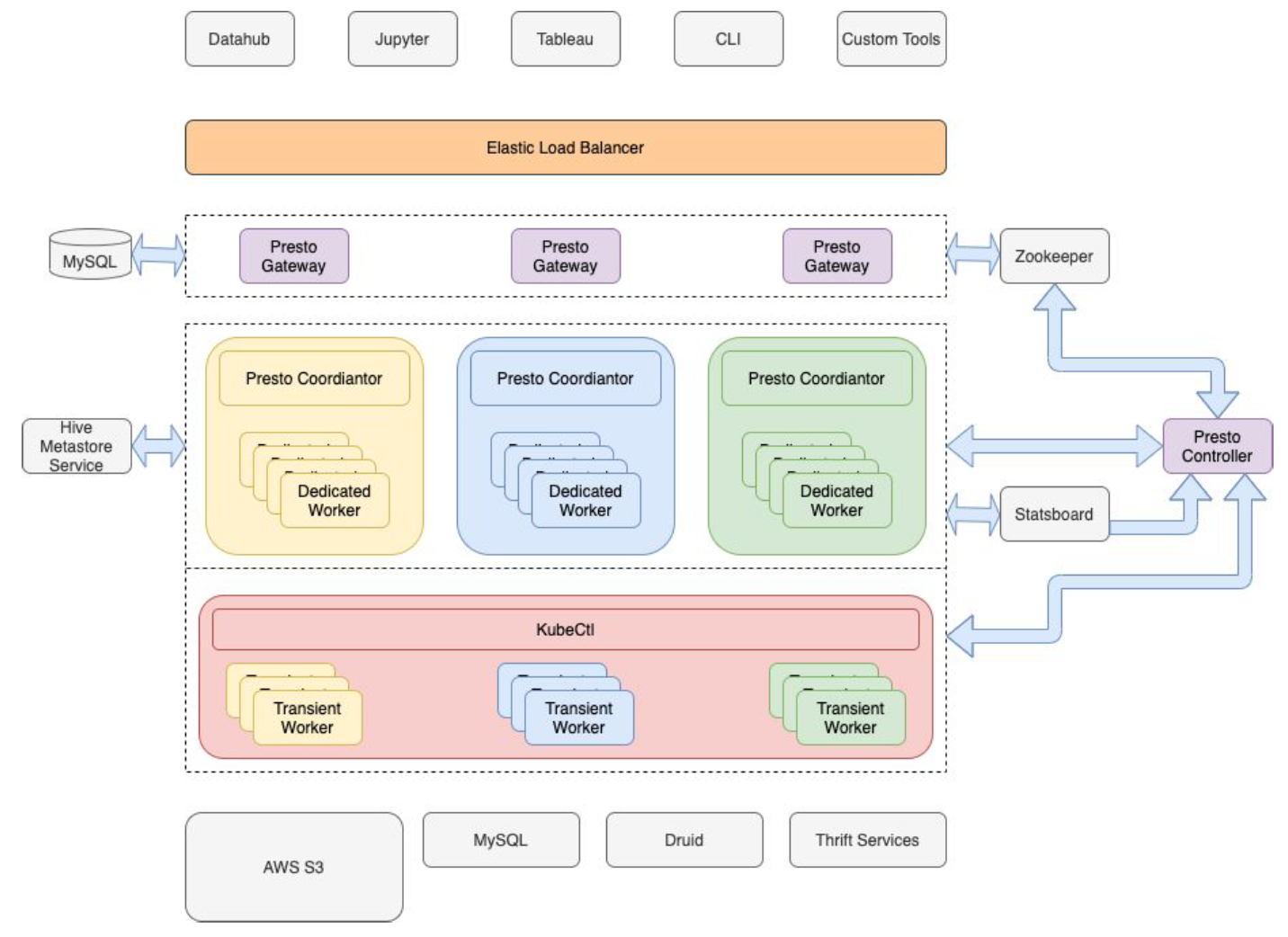
作为一家数据驱动型公司,Pinterest 的许多关键商业决策都是基于数据分析做出的。分析平台是由大数据平台团队提供的,它使公司内部的其他人能够处理 PB 级的数据,以得到他们需要的结果。数据分析是 Pinterest 的一个关键功能,不仅可以回答商业问题,还可以解决工程问题,对功能进行优先排序,识别用户面临的最常见问题, w397090770 3年前 (2021-06-20) 520℃ 0评论0喜欢
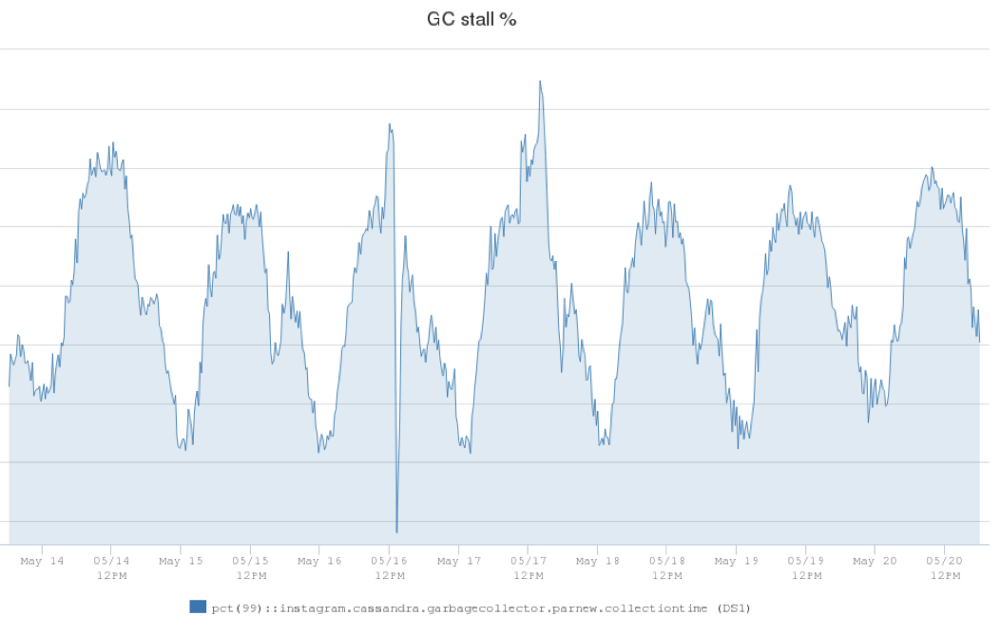
在 Instagram (Instagram 是 Facebook 公司旗下一款免费提供在线图片及视频分享的社交应用软件,于2010年10月发布。)上,我们拥有世界上最大的 Apache Cassandra 数据库部署。我们在 2012 年开始使用 Cassandra 取代 Redis ,在生产环境中支撑欺诈检测,Feed 和 Direct inbox 等产品。起初我们在 AWS 环境中运行了 Cassandra 集群,但是当 Instagram 架构发生 w397090770 5年前 (2019-05-08) 1131℃ 0评论0喜欢
前言 如果你尝试使用Apache Log4J中的DailyRollingFileAppender来打印每天的日志,你可能想对那些日志文件指定一个最大的保存数,就像RollingFileAppender支持maxBackupIndex参数一样。不过遗憾的是,目前版本的Log4j (Apache log4j 1.2.17)无法在使用DailyRollingFileAppender的时候指定保存文件的个数,本文将介绍如何修改DailyRollingFileAppender类,使得它 w397090770 8年前 (2016-04-12) 5525℃ 0评论3喜欢
导读:本文主要介绍Flink实时计算在bilibili的优化,将从以下四个方面展开: 1、Flink-connector稳定性优化 2、Flink sql优化 3、Flink-runtime优化 4、对未来的展望 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据 概述首先介绍下Flink实时计算在b站的应用场景。在b站,Flink on yarn w397090770 3年前 (2021-09-23) 780℃ 0评论2喜欢
一、活动时间 北京第九次Spark Meetup活动将于2015年08月22日进行;下午14:00-18:00。二、活动地点 北京市海淀区丹棱街5号 微软亚太研发集团总部大厦1号楼三、活动内容 1、《Keynote》 ,分享人:Sejun Ra ,CEO of NFLabs.com 2、《An introduction to Zeppelin with a demo》,分享人: Anthony Corbacho, Engineer from NFLabs and w397090770 9年前 (2015-08-07) 2808℃ 0评论1喜欢
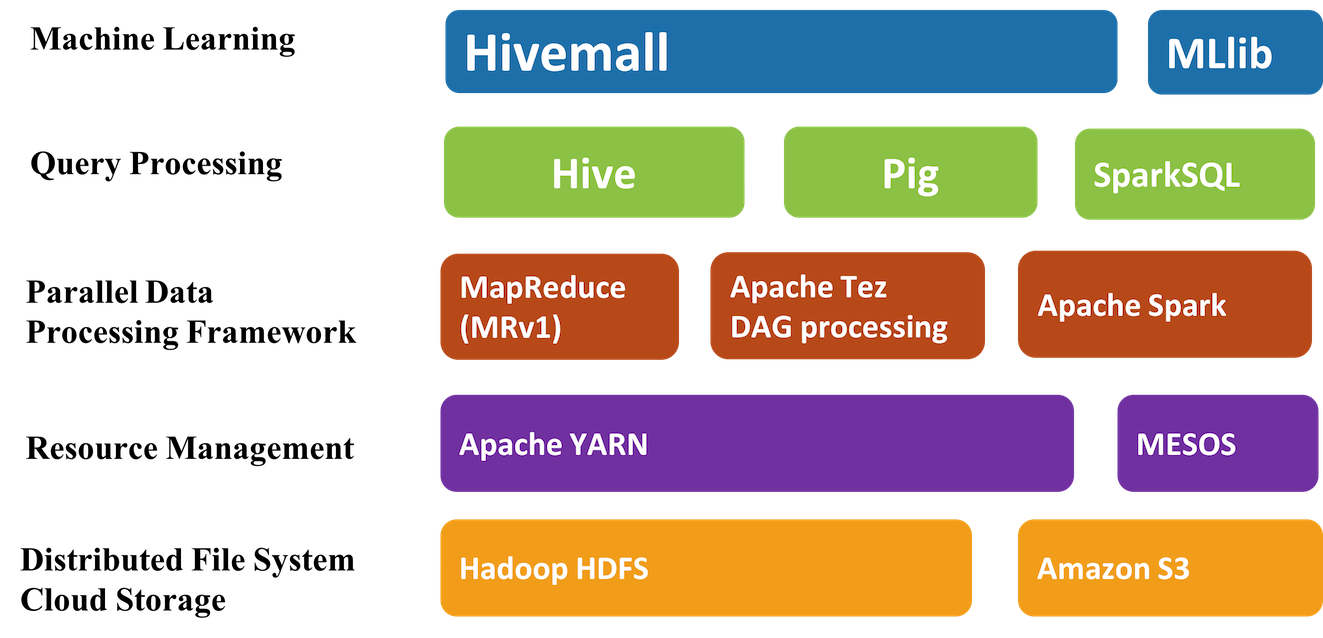
Apache Hivemall是机器学习算法(machine learning algorithms)和多功能数据分析函数(versatile data analytics functions)的集合,它通过Apache Hive UDF / UDAF / UDTF接口提供了一些易于使用的机器学习算法。Hivemall 最初由Treasure Data 开发的,并于2016年9月捐献给 Apache 软件基金会,进入了Apache 孵化器。 Apache Hivemall提供了各种功能包括:回归( w397090770 7年前 (2017-03-29) 3313℃ 1评论10喜欢
近几年来,人工智能逐渐火热起来,特别是和大数据一起结合使用。人工智能的主要场景又包括图像能力、语音能力、自然语言处理能力和用户画像能力等等。这些场景我们都需要处理海量的数据,处理完的数据一般都需要存储起来,这些数据的特点主要有如下几点:大:数据量越大,对我们后面建模越会有好处;稀疏:每行 w397090770 5年前 (2018-11-22) 3241℃ 1评论10喜欢
我在 这篇 文章中介绍了 Apache Spark 3.0 动态分区裁剪(Dynamic Partition Pruning),里面涉及到动态分区的优化思路等,但是并没有涉及到如何使用,本文将介绍在什么情况下会启用动态分区裁剪。并不是什么查询都会启用动态裁剪优化的,必须满足以下几个条件:spark.sql.optimizer.dynamicPartitionPruning.enabled 参数必须设置为 true,不过这 w397090770 5年前 (2019-11-08) 2120℃ 0评论3喜欢
Spark Streaming和Flink都能提供恰好一次的保证,即每条记录都仅处理一次。与其他处理系统(比如Storm)相比,它们都能提供一个非常高的吞吐量。它们的容错开销也都非常低。之前,Spark提供了可配置的内存管理,而Flink提供了自动内存管理,但从1.6版本开始,Spark也提供了自动内存管理。这两个流处理引擎确实有许多相似之处, w397090770 8年前 (2016-04-02) 4619℃ 0评论5喜欢
在Sortable公司,很多数据处理的工作都是使用Spark完成的。在使用Spark的过程中他们发现了一个能够提高Spark job性能的一个技巧,也就是修改数据的分区数,本文将举个例子并详细地介绍如何做到的。查找质数比如我们需要从2到2000000之间寻找所有的质数。我们很自然地会想到先找到所有的非质数,剩下的所有数字就是我们要找 w397090770 8年前 (2016-06-24) 23365℃ 2评论45喜欢
该函数和aggregate类似,但操作的RDD是Pair类型的。Spark 1.1.0版本才正式引入该函数。官方文档定义:Aggregate the values of each key, using given combine functions and a neutral "zero value". This function can return a different result type, U, than the type of the values in this RDD, V. Thus, we need one operation for merging a V into a U and one operation for merging two U's, as in scala.Traversabl w397090770 9年前 (2015-03-02) 39550℃ 2评论35喜欢