哎哟~404了~休息一下,下面的文章你可能很感兴趣:
美国时间2015年3月13日Apache Spark 1.3.0正式发布,Spark 1.3.0是1.X版本线上的第四个版本,这个版本引入了DataFrame API,并且Spark SQL已经从alpha工程毕业了。Spark core引擎可用性也有所提升,另外MLlib和Spark Stream也有所扩展。Spark 1.3有来自60个机构的174魏贡献者带来的1000多个patch。Spark Core Spark 1.3中的Core模块的可用性得到了提升。 w397090770 9年前 (2015-03-14) 4473℃ 1评论3喜欢
在 《Hadoop 2.2.0安装和配置lzo》 文章中介绍了如何基于 Hadoop 2.2.0安装lzo。里面简单介绍了如果在Hive里面使用lzo数据。今天主要来说说如何在Hadoop 2.2.0中使用lzo压缩文件当作的数据。 lzo压缩默认的是不支持切分的,也就是说,如果直接把lzo文件当作Mapreduce任务的输入,那么Mapreduce只会用一个Map来处理这个输入文件,这显然 w397090770 10年前 (2014-03-28) 20409℃ 7评论8喜欢
这里的方法貌似没有用,请参见本博客最新博文《CentOS 6.4安装谷歌浏览器(Chrome)》可以解决这个问题。 Google Chrome,又称Google浏览器,是一个由Google(谷歌)公司开发的开放原始码网页浏览器。如何在Cent OS里面安装Chrome呢?步骤如下: 第一步:打开终端,输入下面的命令[code lang="JAVA"]vim /etc/yum.repos.d/CentOS-Base.repo w397090770 11年前 (2013-08-07) 17585℃ 0评论5喜欢
火焰图(Flame Graphs)是一种可视化技术,用于展示软件程序的运行时性能。它们可以帮助开发者快速识别程序中的热点(即执行时间最长的部分)。本文将指导您如何在 Linux 和 Mac 平台上生成火焰图。火焰图简介火焰图是由 Brendan Gregg 创建的性能分析工具,它以一种直观的方式展示了程序的调用栈信息。火焰图的每一层代表函 w397090770 1周前 (04-10) 36℃ 0评论0喜欢
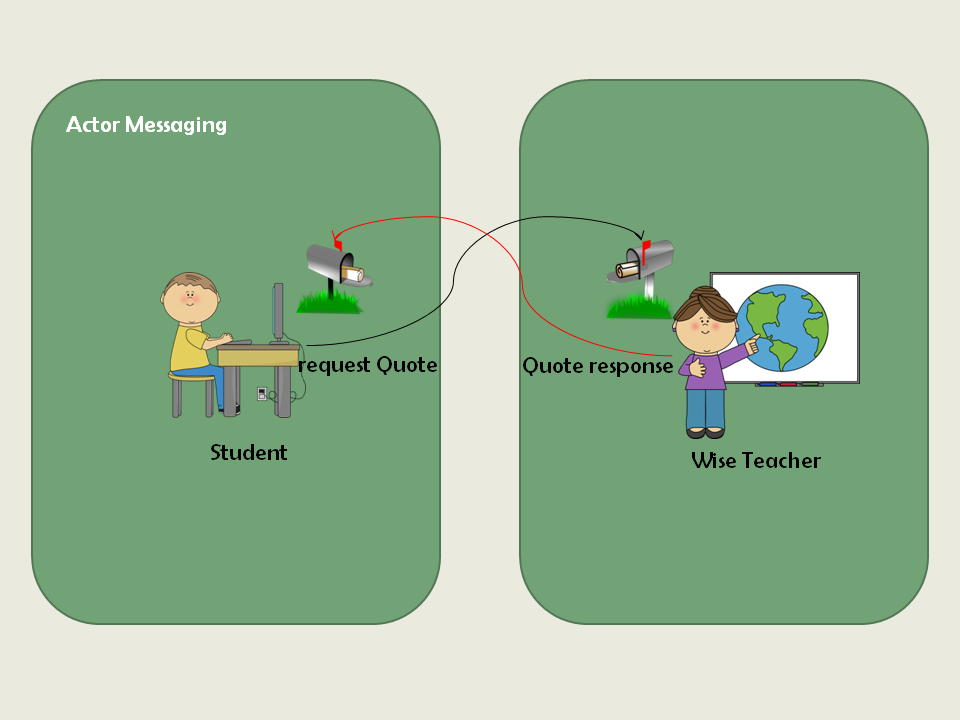
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-12) 28146℃ 4评论119喜欢
一. 问答题1. 简单说说map端和reduce端溢写的细节2. hive的物理模型跟传统数据库有什么不同3. 描述一下hadoop机架感知4. 对于mahout,如何进行推荐、分类、聚类的代码二次开发分别实现那些接口5. 直接将时间戳作为行健,在写入单个region 时候会发生热点问题,为什么呢?二. 计算题1. 比方:如今有10个文件夹, 每个 w397090770 8年前 (2016-08-26) 3125℃ 0评论1喜欢
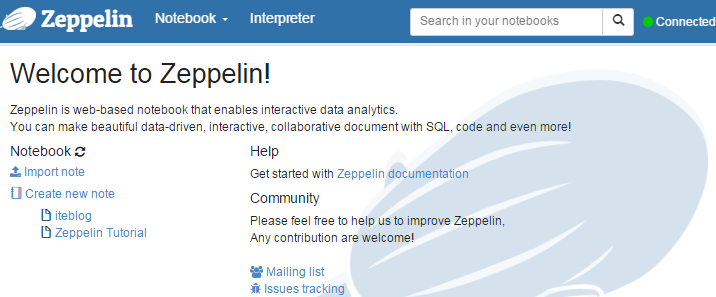
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析。原生就支持Spark、Scala、SQL 、shell, markdown等。而且它是完全开源的,目前还处于Apache孵化阶段。本文所有的操作都是基于Apache Zeppelin w397090770 8年前 (2016-02-02) 20494℃ 9评论20喜欢
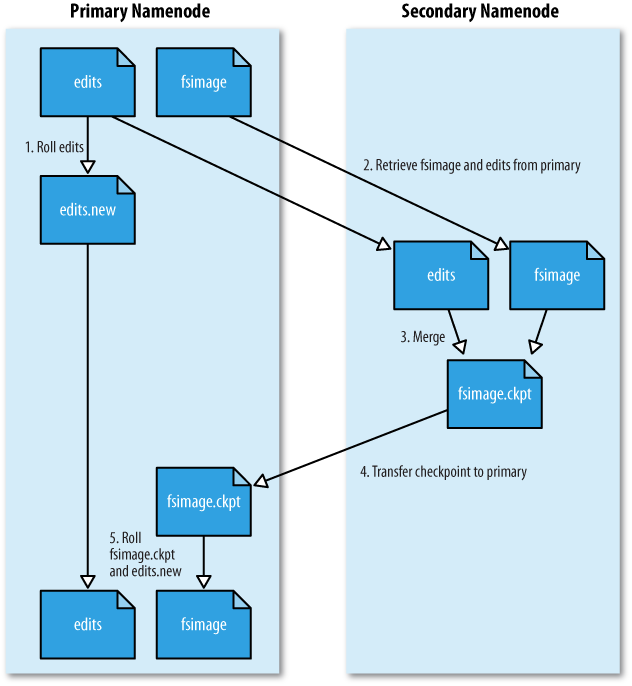
在《Hadoop文件系统元数据fsimage和编辑日志edits》文章中谈到了fsimage和edits的概念、作用等相关知识,正如前面说到,在NameNode运行期间,HDFS的所有更新操作都是直接写到edits中,久而久之edits文件将会变得很大;虽然这对NameNode运行时候是没有什么影响的,但是我们知道当NameNode重启的时候,NameNode先将fsimage里面的所有内容映像到 w397090770 10年前 (2014-03-10) 9717℃ 2评论18喜欢
下面是一系列对Scala中的Lists、Array进行排序的例子,数据结构的定义如下:[code lang="scala"]// data structures working withval s = List( "a", "d", "F", "B", "e")val n = List(3, 7, 2, 1, 5)val m = Map( -2 -> 5, 2 -> 6, 5 -> 9, 1 -> 2, 0 -> -16, -1 -> -4)[/code] 利用Scala内置的sorted w397090770 10年前 (2014-11-07) 25810℃ 0评论23喜欢
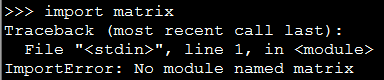
有时候我们会自己编写一些 Python 内置中没有的 module ,比如下面我自定义了一个名为 matrix 的 module ,然后直接在命令行中引入则会出现下面的错误:[code lang="python"][iteblog@www.iteblog.com ~]$ pythonPython 2.7.3 (default, Aug 4 2016, 21:49:57) [GCC 4.4.7 20120313 (Red Hat 4.4.7-16)] on linux2Type "help", "copyright", "credits" or "license& w397090770 7年前 (2017-06-25) 56631℃ 0评论14喜欢
如今,很多公司可能会在内部使用多种数据存储和处理系统。这些不同的系统解决了对应的使用案例。除了传统的 RDBMS (比如 Oracle DB,Teradata或PostgreSQL) 之外,我们还会使用 Apache Kafka 来获取流和事件数据。使用 Apache Druid 处理实时系列数据(real-time series data),使用 Apache Phoenix 进行快速索引查找。 此外,我们还可能使用云存储 w397090770 5年前 (2019-03-16) 4998℃ 1评论7喜欢
Finatra Finatra是一款基于TwitterServer和Finagle的快速、可测试的Scala异步框架。Finatra is a fast, testable, Scala services built on TwitterServer and Finagle.Play Play是一款轻量级、无状态的WEB友好框架。使用Java和Scala可以很方便地创建web应用程序。Play is based on a lightweight, stateless, web-friendly architecture.Play Framework makes it easy to build web application w397090770 8年前 (2015-12-25) 12462℃ 0评论15喜欢
2021年2月15日,Apache Flink 创建者、Ververica 公司(前身 DataArtisans)的联合创始人 Fabian Hueske 在 Twitter 宣布其已经从 Ververica 离职, 不过离职原因不得而知。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop另外,Ververica 公司原 COO Holger Temme 将接替 Kostas Tzoumas 成为新的 CEO。Kostas Tzoumas (原 CEO) w397090770 3年前 (2021-02-18) 991℃ 0评论3喜欢
ResourceManager 内维护了 NodeManager 的生命周期;对于每个 NodeManager 在 ResourceManager 中都有一个 RMNode 与其对应;除了 RMNode ,ResourceManager 中还定义了 NodeManager 的状态(states)以及触发状态转移的事件(event)。具体如下:org.apache.hadoop.yarn.server.resourcemanager.rmnode.RMNode:这是一个接口,每个 NodeManager 都与 RMNode 对应,这个接口主要维 w397090770 7年前 (2017-06-07) 3470℃ 0评论21喜欢
Presto 是一个用于分析的开源分布式 ANSI SQL 查询引擎,支持计算和存储的分离。性能对于一些分析查询尤其重要,因此 Presto 有许多设计特性来最大化 Presto 的速度,比如内存中的流水线执行(memory pipelined execution)、分布式的扩展架构和大规模并行处理(MPP)设计。Presto支持的具体性能特性:数据压缩(SNAPPY, LZ4, ZSTD 以及 GZIP) w397090770 2年前 (2022-03-02) 1381℃ 0评论2喜欢
Docker 为我们提供了大量的命令,直接在终端运行 docker --help 即可查看 Docker 支持的命令。如果需要查看具体命令的使用方式,可以使用 docker COMMAND --help。Docker 提供了 55 条命令,由于篇幅的原因,这里将介绍 Docker 常用的命令,其他的可以参见 Docker 官方文档。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号 w397090770 4年前 (2020-02-04) 312℃ 0评论3喜欢
我们在用Maven编译项目的时候有时老是出现无法下载某些jar依赖从而导致整个工程编译失败,这时候我们可以修改jar下载的源(也就是repositorie)即可,下面是Maven的用法,你可以在你项目的pom文件里面加入这些代码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop[code lang="JAVA"]<!-- **** w397090770 10年前 (2014-07-25) 12932℃ 1评论13喜欢
Shanghai Apache Spark Meetup第十一次聚会,将于12月10日,举办于上海大连路688号宝地广场22楼小沃科技活动场地。靠近地铁4号线和12号线的大连路站。本次会议得到中国联通小沃科技的大力支持。欢迎大家前来参加!会议主题1、演讲主题:《Spark Streaming构建实时系统介绍》 演讲嘉宾:程然,小沃科技高级架构师,开源爱好者 w397090770 7年前 (2016-12-01) 1824℃ 0评论5喜欢
auto_ptr是这样一种指针:它是“它所指向的对象”的拥有者。这种拥有具有唯一性,即一个对象只能有一个拥有者,严禁一物二主。当auto_ptr指针被摧毁时,它所指向的对象也将被隐式销毁,即使程序中有异常发生,auto_ptr所指向的对象也将被销毁。设计动机在函数中通常要获得一些资源,执行完动作后,然后释放所获得的资源 w397090770 11年前 (2013-03-30) 2694℃ 0评论2喜欢
和 MySQL 以及其他计算引擎类似,MongoDB 给我们提供了 explain 命令来查看某个查询的执行计划,其使用也比较简单,具体如下:[code lang="bash"]db.collection.explain().<method(...)>[/code]explain 命令默认是打印出查询的 queryPlanner,也就是什么参数都不传递。从 3.5.5 版本开始,explain 命名还支持 executionStats 和 allPlansExecution 两种运行模式 w397090770 3年前 (2021-06-21) 260℃ 0评论0喜欢
重庆博尼施科技有限公司是一家商用车全周期方案服务商,利用车联网、云计算、移动互联网技术,在物流领域 为商用车的生产、销售、使用、售后、回收各个环节提供一站式解决方案,其中的新能源车辆监控系统就是由该公司提供的,本文是阿里云客户重庆博尼施科技有限公司介绍如何使用阿里云 HBase 来实现新能源车辆监控系统 w397090770 5年前 (2018-11-29) 4217℃ 2评论16喜欢
Delta Lake 的 Delete 功能是由 0.3.0 版本引入的,参见这里,对应的 Patch 参见这里。在介绍 Apache Spark Delta Lake 实现逻辑之前,我们先来看看如何使用 delete 这个功能。Delta Lake 删除使用Delta Lake 的官方文档为我们提供如何使用 Delete 的几个例子,参见这里,如下:[code lang="scala"]import io.delta.tables._val iteblogDeltaTable = DeltaTable.forPath(spa w397090770 5年前 (2019-09-27) 1439℃ 0评论2喜欢
为了提高 HBase 存储的利用率,很多 HBase 使用者会对 HBase 表中的数据进行压缩。目前 HBase 可以支持的压缩方式有 GZ(GZIP)、LZO、LZ4 以及 Snappy。它们之间的区别如下:GZ:用于冷数据压缩,与 Snappy 和 LZO 相比,GZIP 的压缩率更高,但是更消耗 CPU,解压/压缩速度更慢。Snappy 和 LZO:用于热数据压缩,占用 CPU 少,解压/压缩速度比 w397090770 7年前 (2017-02-09) 1882℃ 0评论1喜欢
Apache软件基金会在2017年01月10正式宣布Apache Beam从孵化项目毕业,成为Apache的顶级项目。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领 w397090770 7年前 (2017-01-12) 3143℃ 0评论7喜欢
ZooKeeper使用ACL来控制访问其znode(ZooKeeper的数据树的数据节点)。ACL的实现方式非常类似于UNIX文件的访问权限:它采用访问权限位 允许/禁止 对节点的各种操作以及能进行操作的范围。不同于UNIX权限的是,ZooKeeper的节点不局限于 用户(文件的拥有者),组和其他人(其它)这三个标准范围。ZooKeeper不具有znode的拥有者的概念。 w397090770 9年前 (2015-12-02) 7209℃ 1评论4喜欢
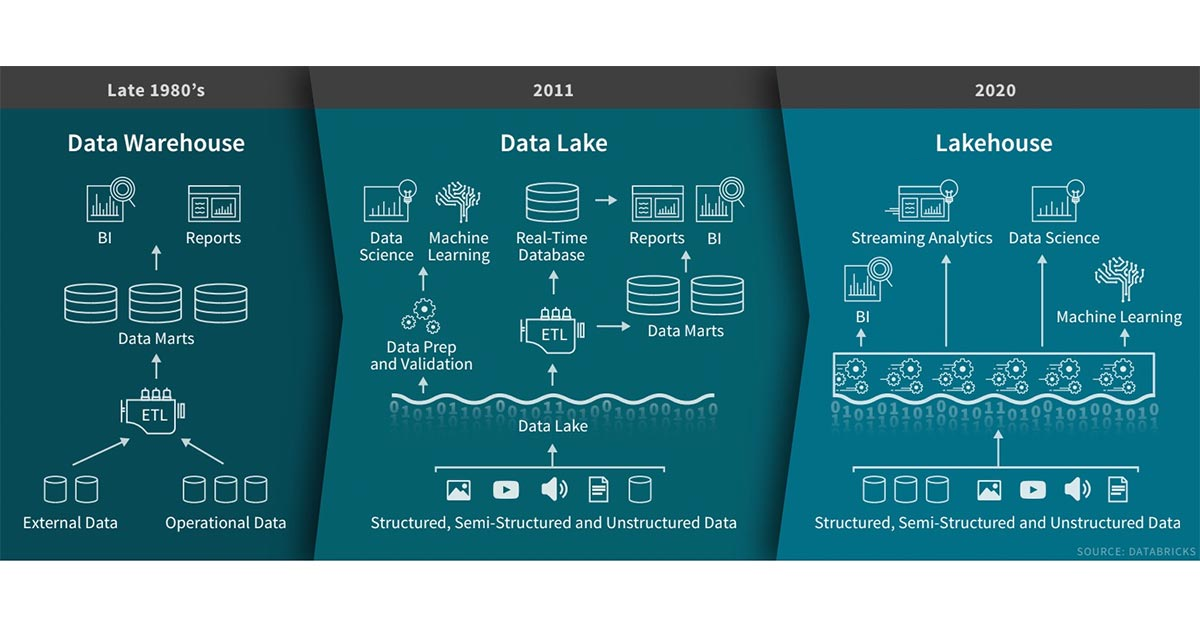
引入在Databricks的过去几年中,我们看到了一种新的数据管理范式,该范式出现在许多客户和案例中:LakeHouse。在这篇文章中,我们将描述这种新范式及其相对于先前方案的优势。数据仓库技术自1980诞生以来一直在发展,其在决策支持和商业智能应用方面拥有悠久的历史,而MPP体系结构使得系统能够处理更大数据量。但是,虽 w397090770 4年前 (2020-02-03) 2976℃ 0评论6喜欢
CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号。在本文中的CSV格式的数据就不是简单的逗号分割的),其文件以纯文本形式存储表格数据(数字和文本)。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字 w397090770 9年前 (2015-01-26) 9529℃ 0评论12喜欢
2021年01月21日,Apache 官方博客宣布 Apache® Superset™ 成为顶级项目。Apache® Superset™ 是一个现代化的大数据探索和可视化平台,它允许用户使用简单的无代码可视化构建器和最先进的 SQL 编辑器轻松快速地构建仪表盘(dashboards)。该项目于2015年在 Airbnb 启动,并于2017年5月进入 Apache 孵化器。说白了,其实 Apache Superset 算是一个大数据 w397090770 3年前 (2021-01-22) 702℃ 0评论1喜欢
在本文中,我将分享一些关于如何编写可伸缩的 Apache Spark 代码的技巧。本文提供的示例代码实际上是基于我在现实世界中遇到的。因此,通过分享这些技巧,我希望能够帮助新手在不增加集群资源的情况下编写高性能 Spark 代码。背景我最近接手了一个 notebook ,它主要用来跟踪我们的 AB 测试结果,以评估我们的推荐引擎的性能 w397090770 4年前 (2019-11-26) 1560℃ 0评论4喜欢
有时候我们想对来自不同平台对同一页面的访问进行处理。比如访问 https://www.iteblog.com/test.html 页面,如果是电脑的浏览器访问,直接不处理;但是如果是手机的浏览器访问这个页面我们想跳转到其他页面去。这时候有几种方法可以实现:直接通过 JavaScript 进行处理;通过 Nginx 配置来处理如果想及时了解Spark、Hadoop或者Hbase w397090770 6年前 (2017-12-16) 1739℃ 0评论13喜欢