哎哟~404了~休息一下,下面的文章你可能很感兴趣:
这个问题可能很多面试的人都遇到过,很多人可能想利用循环来判断,代码可能如下所示:[code lang="JAVA"] public static boolean isPowOfTwo(int n) { int temp = 0; for (int i = 1; ; i++) { temp = (int) Math.pow(2, i); if (temp >= n) break; } if (temp == n) return true; else return false; }[/code] w397090770 11年前 (2013-09-17) 11493℃ 6评论14喜欢
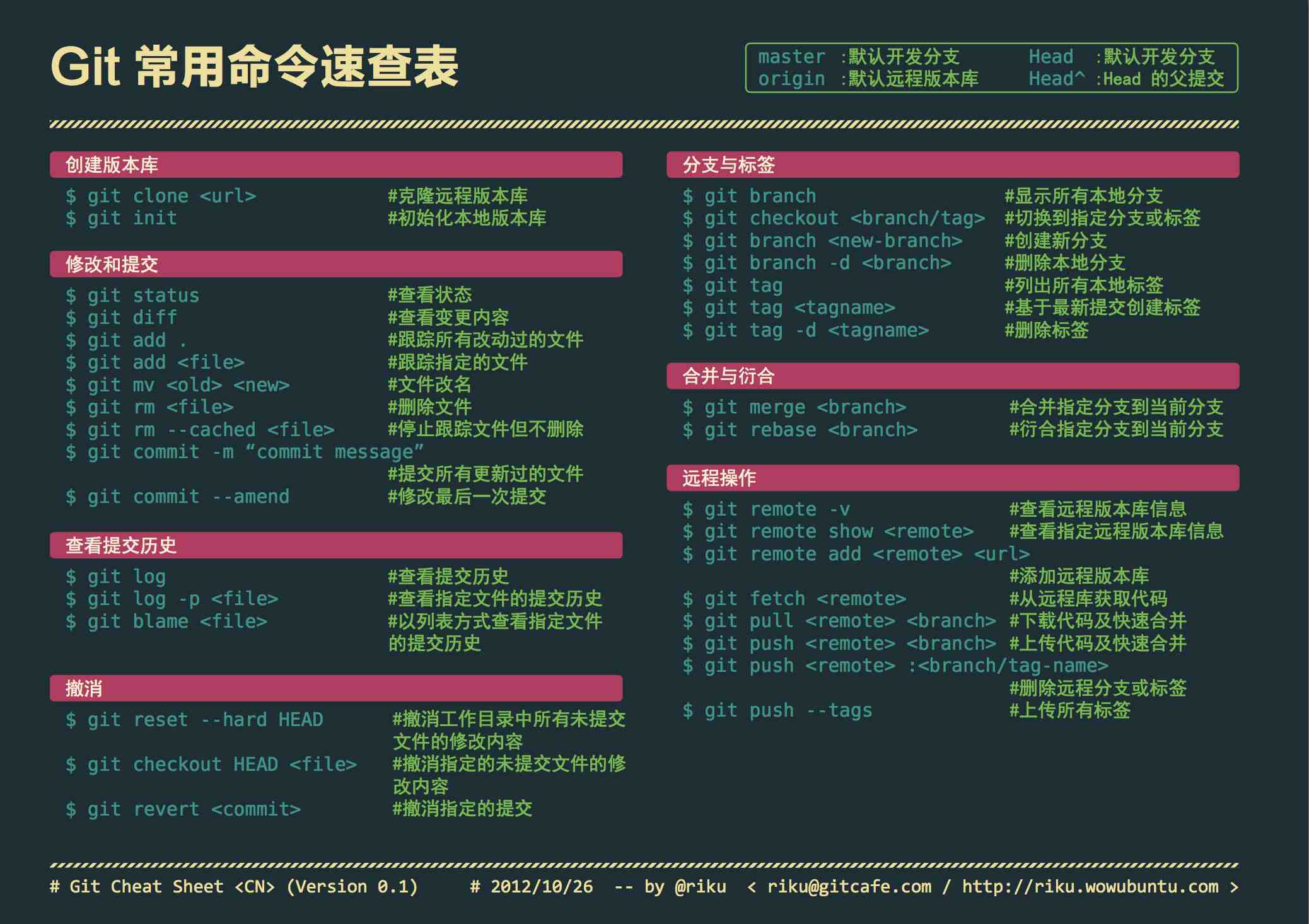
本文列出Git常用命令,点击下图查看大图如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop入门[code lang="bash"]git initorgit clone url[/code]配置[code lang="bash"]git config --global color.ui truegit config --global push.default currentgit config --global core.editor vimgit config --global user.name "John Doe" w397090770 7年前 (2016-12-16) 2359℃ 0评论2喜欢
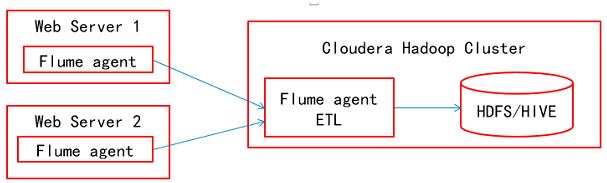
本文来自徐宇辉(微信号:xuyuhui263)的投稿,目前在中国移动从事数字营销的业务支撑工作,感谢他的文章。Apache Flume简介Apache Flume是一个Apache的开源项目,是一个分布的、可靠的软件系统,主要目的是从大量的分散的数据源中收集、汇聚以及迁移大规模的日志数据,最后存储到一个集中式的数据系统中。Apache Flume是由 zz~~ 7年前 (2017-03-08) 7178℃ 0评论17喜欢
一. 问答题1) datanode在什么情况下不会备份?2) hdfs的体系结构?3) sqoop在导入数据到mysql时,如何让数据不重复导入?如果存在数据问题sqoop如何处理?4) 请列举曾经修改过的/etc下的配置文件,并说明修改要解决的问题?5) 描述一下hadoop中,有哪些地方使用了缓存机制,作用分别是什么?二. 计算题1、使用Hive或 w397090770 8年前 (2016-08-26) 4248℃ 1评论4喜欢
数据分析中将两个数据集进行 Join 操作是很常见的场景。我在 这篇 文章中介绍了 Spark 支持的五种 Join 策略,本文我将给大家介绍一下 Apache Spark 中支持的 Join 类型(Join Type)。目前 Apache Spark 3.0 版本中,一共支持以下七种 Join 类型:INNER JOINCROSS JOINLEFT OUTER JOINRIGHT OUTER JOINFULL OUTER JOINLEFT SEMI JOINLEFT ANTI JOIN在实现上 w397090770 4年前 (2020-10-25) 1409℃ 0评论6喜欢
ZooKeeper使用ACL来控制访问其znode(ZooKeeper的数据树的数据节点)。ACL的实现方式非常类似于UNIX文件的访问权限:它采用访问权限位 允许/禁止 对节点的各种操作以及能进行操作的范围。不同于UNIX权限的是,ZooKeeper的节点不局限于 用户(文件的拥有者),组和其他人(其它)这三个标准范围。ZooKeeper不具有znode的拥有者的概念。 w397090770 9年前 (2015-12-02) 7209℃ 1评论4喜欢
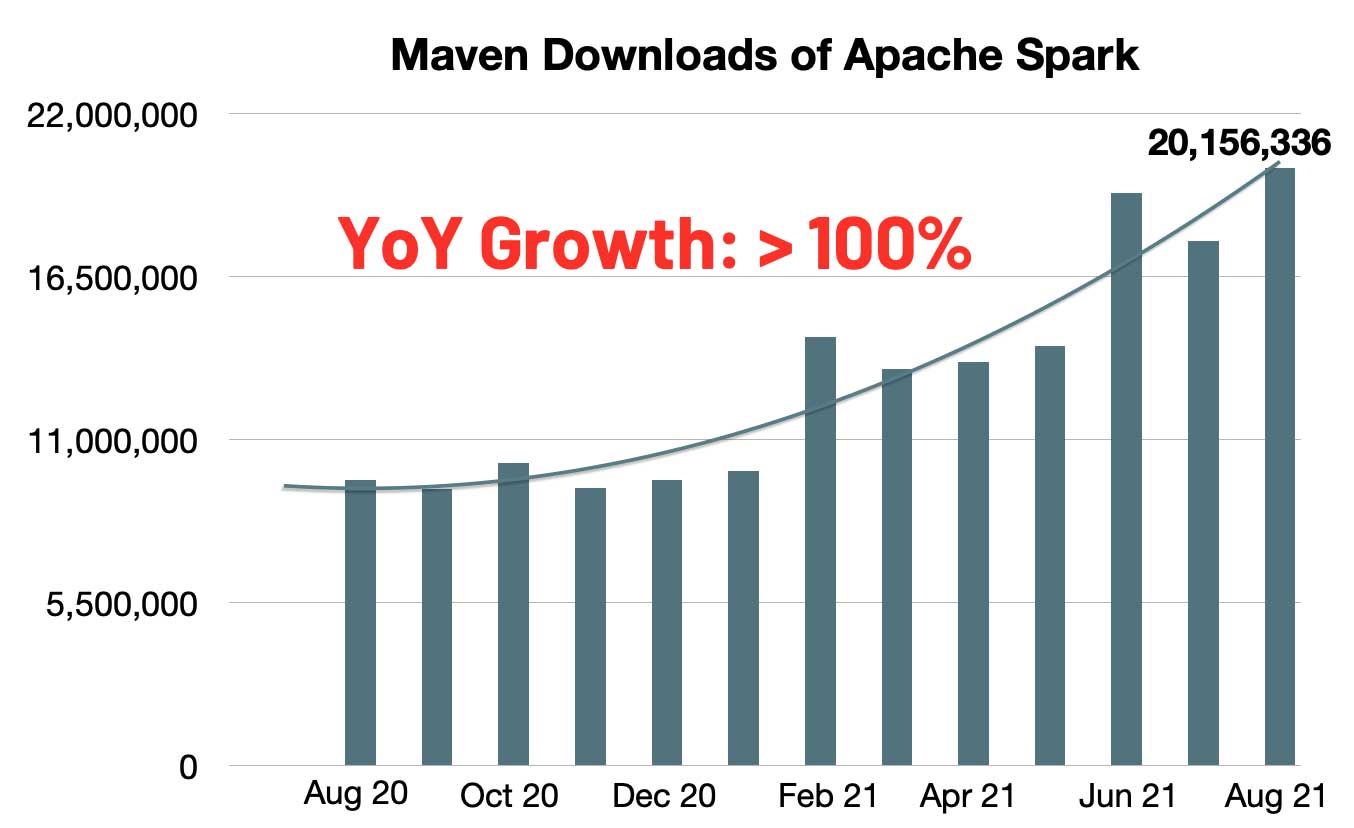
经过七轮投票, Apache Spark™ 3.2 终于在昨天正式发布了。Apache Spark™ 3.2 已经是 Databricks Runtime 10.0 的一部分,感兴趣的同学可以去试用一下。按照惯例,这个版本应该不是稳定版,所以建议大家不要在生产环境中使用。Spark 的每月 Maven 下载数量迅速增长到 2000 万,与去年同期相比,Spark 的月下载量翻了一番。Spark 已成为在单节 w397090770 3年前 (2021-10-20) 1183℃ 0评论3喜欢
本文来自 IBM 东京研究院的高级技术人员 Kazuaki Ishizaki 博士在 Spark Summit North America 2020 的 《SQL Performance Improvements at a Glance in Apache Spark 3.0》议题的分享,本文视频参见今天的推文第三条。PPT 请关注过往记忆大数据并后台回复 sparksql3 获取。Spark 3.0 正式版在上个月已经发布了,其中更新了很多功能,参见过往记忆大数据的 Ap w397090770 4年前 (2020-07-08) 2416℃ 0评论3喜欢
在默认情况下,Wordpress是不带有博客访问或者是博文的访问次数的,这对于某些人(比如我)来说是很不喜欢的,我想统计一下我博客或者博文到底被人家看了多少次。如下图所示: 在前面的两篇博文中(为WordPress的suffusion主题添加文章浏览次数,怎么给wordPress3.5.1添加文章统计)谈到了如何给博文添加访客浏览记录。 w397090770 11年前 (2013-04-30) 7781℃ 2评论8喜欢
在开发Wordpress的时候,我们可能需要获取到设备的类型,比如手机、电脑或者iPad等,然后做出不同的决定,这就要求我们精确地判断出当前设备的类型。熟悉Wordpress的同学会知道,Wordpress中安装目录下的wp-includes/vars.php文件里面有个名为wp_is_mobile的函数,其代码如下:[code lang="php"]function wp_is_mobile() { static $is_mobile = null; w397090770 8年前 (2016-03-01) 2067℃ 0评论1喜欢
在这篇文章里,我将和大家分享一下我用Scala、Akka、Play、Kafka和ElasticSearch等构建大型分布式、容错、可扩展的分析引擎的经验。第一代架构 我的分析引擎主要是用于文本分析的。输入有结构化的、非结构化的和半结构化的数据,我们会用分析引擎对数据进行大量处理。如下图(点击查看大图)所示为第一代架构,分析引 w397090770 8年前 (2016-08-08) 4898℃ 0评论13喜欢
Learning Apache Kafka, 2nd Edition于2015年02月出版,全书共112页。 w397090770 9年前 (2015-08-25) 5477℃ 2评论10喜欢
本文来自车好多大数据离线存储团队相关同事的投稿,本文作者: 车好多大数据离线存储团队:冯武、王安迪。升级的背景HDFS 集群作为大数据最核心的组件,在公司承载了DW、AI、Growth 等重要业务数据的存储重任。随着业务的高速发展,数据的成倍增加,HDFS 集群出现了爆炸式的增长,使用率一直处于很高的水位。同时 HDFS文件 w397090770 3年前 (2020-11-24) 1250℃ 0评论2喜欢
随着我们使用 Docker 的次数越来越多,我们电脑里面可能已经存在很多 Docker 镜像,大量的镜像会占据大量的存储空间,所有很有必要清理一些不需要的镜像。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop镜像的删除在删除镜像之前,我们可以看下系统里面都有哪些镜像:[code lang="bash"][ite w397090770 4年前 (2020-04-14) 464℃ 0评论1喜欢
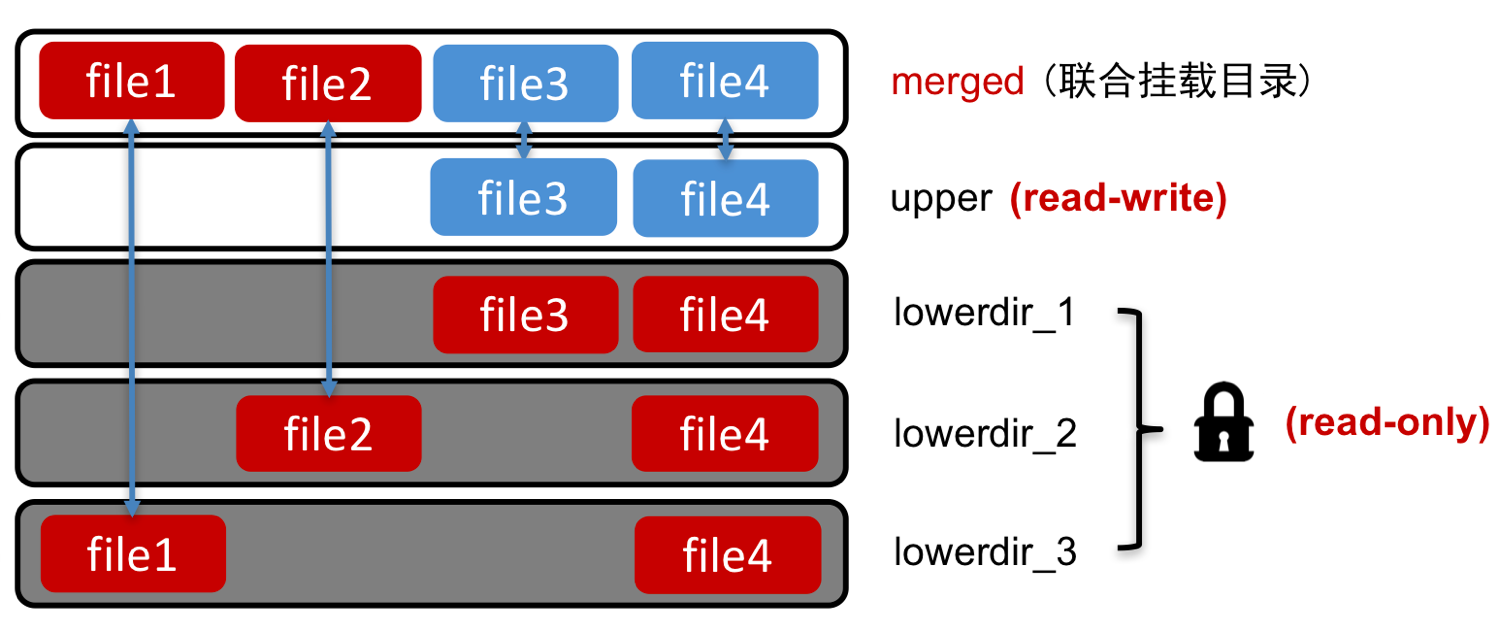
我们在前面 《Docker 入门教程:镜像分层》 文章中介绍了 Docker 为什么构建速度非常快,其原因就是采用了镜像分层,镜像分层底层采用的技术就是本文要介绍的 Union File System。Linux 支持多种 Union File System,比如 aufs、OverlayFS、ZFS 等。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众帐号:iteblog_hadoopaufs & OverlayF w397090770 4年前 (2020-02-09) 1131℃ 0评论4喜欢
本资料来自2021年12月09日举办的 PrestoCon 2021,标题为《Presto at Bytedance》Presto 在字节跳动中得到了广泛的应用,如数据仓库、BI工具、广告等。与此同时,字节跳动的 presto 团队也提供了许多重要的特性和优化,如 Hive UDF Wrapper、多个协调器、运行时过滤器等,扩展了 presto 的用法,增强了 presto 的稳定性。下面是字节跳动目前 Presto w397090770 2年前 (2021-12-08) 362℃ 0评论0喜欢
为了方便集群的部署,一般我们都会构建出一个 dokcer 镜像,然后部署到 k8s 里面。Presto、Prestissimo 以及 Velox 也不例外,本文将介绍如果构建 presto 以及 Prestissimo 的镜像。构建 Presto 镜像Presto 官方代码里面其实已经包含了构建 Presto 镜像的相关文件,具体参见 $PRESTO_HOME/docker 目录:[code lang="bash"]➜ target git:(velox_docker) ✗ ll ~/ w397090770 10个月前 (06-21) 266℃ 0评论7喜欢
在本博客的《Spark 0.9.1源码编译》和《Spark源码编译遇到的问题解决》两篇文章中,分别讲解了如何编译Spark源码以及在编译源码过程中遇到的一些问题及其解决方法。今天来说说如何部署分布式的Spark集群,在本篇文章中,我主要是介绍如何部署Standalone模式。 一、修改配置文件 1、将$SPARK_HOME/conf/spark-env.sh.template文件 w397090770 10年前 (2014-04-21) 9450℃ 1评论5喜欢
Git 的代码回滚主要有 reset 和 revert,本文介绍其用法如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopreset一般用法是 [code lang="bash"]git reset --hard commit_id[/code]其中 commit_id 是使用 git log 查看的 id,如下:[code lang="bash"]$ git logcommit 26721c73c6bb82c8a49aa94ce06024f592032d0cAuthor: iteblog <iteblog@iteb w397090770 4年前 (2020-10-12) 1246℃ 0评论0喜欢
我们往Kafka发送消息时一般都是将消息封装到KeyedMessage类中:[code lang="scala"]val message = new KeyedMessage[String, String](topic, key, content)producer.send(message)[/code]Kafka会根据传进来的key计算其分区ID。但是这个Key可以不传,根据Kafka的官方文档描述:如果key为null,那么Producer将会把这条消息发送给随机的一个Partition。If the key is null, the w397090770 8年前 (2016-03-30) 16107℃ 0评论10喜欢
Hadoop Streaming 是 Hadoop 提供的一个 MapReduce 编程工具,它允许用户使用任何可执行文件、脚本语言或其他编程语言来实现 Mapper 和 Reducer 作业。比如下面的例子[code lang="bash"]mapred streaming \ -input myInputDirs \ -output myOutputDir \ -mapper /bin/cat \ -reducer /usr/bin/wc[/code]Hadoop Streaming程序是如何工作的Hadoop Streaming 使用了 Unix 的标准 w397090770 7年前 (2017-03-21) 9888℃ 0评论15喜欢
为期三天的 SPARK + AI SUMMIT Europe 2019 于 2019年10月15日-17日荷兰首都阿姆斯特丹举行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。Spark+AI Summit Europe 2019 是欧洲最大的数据和机器学习会议,大约有1700多名数据科学家、工程师和分析师参加此次会议。本次会议的提议包括了A w397090770 5年前 (2019-11-01) 996℃ 0评论1喜欢
Protobuf (全称 Protocol Buffers)是 Google 开发的一种数据描述语言,能够将结构化数据序列化,可用于数据存储、通信协议等方面。在 HBase 里面用使用了 Protobuf 的类库,目前 Protobuf 最新版本是 3.6.1(参见这里),但是在目前最新的 HBase 3.0.0-SNAPSHOT 对 Protobuf 的依赖仍然是 2.5.0(参见 protobuf.version),但是这些版本的 Protobuf 是互补兼 w397090770 5年前 (2018-11-26) 5292℃ 0评论10喜欢
《Spark源码分析:多种部署方式之间的区别与联系(1)》 《Spark源码分析:多种部署方式之间的区别与联系(2)》 从官方的文档我们可以知道,Spark的部署方式有很多种:local、Standalone、Mesos、YARN.....不同部署方式的后台处理进程是不一样的,但是如果我们从代码的角度来看,其实流程都差不多。 从代码中,我们 w397090770 10年前 (2014-10-24) 7666℃ 2评论14喜欢
摘要:本文整理自快手实时计算团队技术专家张静、张芒在 Flink Forward Asia 2021 的分享。主要内容包括: Flink SQL 在快手功能扩展性能优化稳定性提升未来展望 一、Flink SQL 在快手 经过一年多的推广,快手内部用户对 Flink SQL 的认可度逐渐提高,今年新增的 Flink 作业中,SQL 作业达到了 60%,与去年相比有了一倍的提升,峰值吞吐 w397090770 2年前 (2022-02-18) 873℃ 0评论1喜欢
我们在用Maven编译项目的时候有时老是出现无法下载某些jar依赖从而导致整个工程编译失败,这时候我们可以修改jar下载的源(也就是repositorie)即可,下面是Maven的用法,你可以在你项目的pom文件里面加入这些代码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop[code lang="JAVA"]<!-- **** w397090770 10年前 (2014-07-25) 12932℃ 1评论13喜欢
这个文档只是简单的介绍如何快速地使用Spark。在下面的介绍中我将介绍如何通过Spark的交互式shell来使用API。Basics Spark shell提供一种简单的方式来学习它的API,同时也提供强大的方式来交互式地分析数据。Spark shell支持Scala和Python。可以通过以下方式进入到Spark shell中。[code lang="JAVA"]# 本文原文地址:https://www.iteblog.com/ar w397090770 10年前 (2014-06-10) 77031℃ 26评论156喜欢
R 是数据科学中最流行的计算机语言之一,专门用于统计分析和一些扩展,如用于数据处理和机器学习任务的 RStudio addins 和其他 R 包。此外,它使数据科学家能够轻松地可视化他们的数据集。通过在 Apache Spark 中使用 SparkR,可以很容易地扩展 R 代码。要交互式地运行作业,可以通过运行 R shell 轻松地在分布式集群中运行 R 的作业 w397090770 4年前 (2020-07-09) 737℃ 0评论2喜欢
今天凌晨(2016-10-05)Apache Spark 2.0.1稳定版正式发布。Apache Spark 2.0.1是一个维护版本,一共处理了300个Issues,推荐所有使用Spark 2.0.0的用户升级到此版本。Apache Spark 2.0为我们带来了许多新的功能: DataFrame和Dataset统一(可以参见《Spark 2.0技术预览:更容易、更快速、更智能》):https://www.iteblog.com/archives/1668.html SparkSession:一个 w397090770 8年前 (2016-10-05) 3139℃ 0评论7喜欢
目前Spark支持四种方式从数据库中读取数据,这里以Mysql为例进行介绍。一、不指定查询条件 这个方式链接MySql的函数原型是:[code lang="scala"]def jdbc(url: String, table: String, properties: Properties): DataFrame[/code] 我们只需要提供Driver的url,需要查询的表名,以及连接表相关属性properties。下面是具体例子:[code lang="scala" w397090770 8年前 (2015-12-28) 37612℃ 1评论61喜欢














![Spark+AI Summit Europe 2019 高清视频下载[共135个]](https://www.iteblog.com/pic/spark/spark+ai_summit_europe_2019-iteblog.jpg)