哎哟~404了~休息一下,下面的文章你可能很感兴趣:
Spark GraphX in Action开头介绍了GraphX库可以干什么,并通过例子介绍了如何以交互的方式使用GraphX 。阅读完本书,您将学习到很多实用的技术,用于增强应用程序和将机器学习算法应用于图形数据中。 本书包括了以下几个知识点: (1)、Understanding graph technology (2)、Using the GraphX API (3)、Developing algorithms w397090770 7年前 (2017-02-12) 4679℃ 0评论5喜欢
HDFS设计之处并不支持给文件追加内容,这样的设计是有其背景的(如果想了解更多关于HDFS的append的曲折实现,可以参考《File Appends in HDFS》:http://blog.cloudera.com/blog/2009/07/file-appends-in-hdfs/),但从HDFS2.x开始支持给文件追加内容,可以参见https://issues.apache.org/jira/browse/HADOOP-8230。可以再看看http://www.quora.com/HDFS/Is-HDFS-an-append-only-file- w397090770 10年前 (2014-01-03) 34212℃ 3评论20喜欢
2010年,Facebook 的工程师在 ICDC(IEEE International Conference on Data Engineering) 发表了一篇 《RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems》 的论文,介绍了其为基于 MapReduce 的数据仓库设计的高效存储结构,这就是我们熟知的 RCFile(Record Columnar File)。下面介绍 RCFile 的一些诞生背景和设计。背景早在2010 w397090770 4年前 (2020-06-16) 1221℃ 0评论7喜欢
在《从Hadoop1.x集群升级到Hadoop2.x步骤》文章中简单地介绍了如何从Hadoop1.x集群升级到Hadoop2.x,那里面只讨论了成功升级,那么如果集群升级失败了,我们该如何从失败中回滚呢?这正是本文所有讨论的。本文将以hadoop-0.20.2-cdh3u4升级到Hadoop-2.2.0升级失败后,如何回滚。 1、如果你将Hadoop1.x升级到Hadoop2.x的过程中失败了,当你 w397090770 11年前 (2013-12-05) 5797℃ 1评论7喜欢
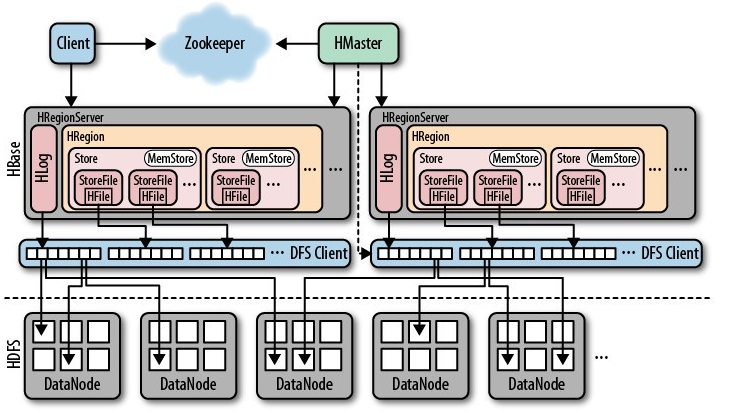
本文首先对 HBase 做简单的介绍,包括其整体架构、依赖组件、核心服务类的相关解析。再重点介绍 HBase 读取数据的流程分析,并根据此流程介绍如何在客户端以及服务端优化性能,同时结合有赞线上 HBase 集群的实际应用情况,将理论和实践结合,希望能给读者带来启发。如文章有纰漏请在下面留言,我们共同探讨共同学习。HBas w397090770 5年前 (2019-02-20) 5098℃ 0评论10喜欢
Apache Hive 1.2.0于美国时间2015年05月18日正式发布,其中修复了大量大Bug,完整邮件内容如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopThe Apache Hive team is proud to announce the the release of Apache Hive version 1.2.0.The Apache Hive (TM) data warehouse software facilitates querying and managing large datasets residin w397090770 9年前 (2015-05-19) 5389℃ 0评论4喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 117.162.225.199 8123 高匿名 HTTP 江西 w397090770 9年前 (2015-05-12) 34985℃ 0评论3喜欢
在本文中,我将介绍八个基本的 Docker 容器命令,这些命令对于在 Docker 容器上执行基本操作很有用,比如运行,列表,停止,查看日志,删除等等。如果你对 Docker 的概念不熟悉,推荐你推荐你到网上查看相关的入门介绍,这篇文章就不详细介绍了。 现在我们赶快进入要了解的命令中:如果想及时了解Spark、Hadoop或者HBase相关的 w397090770 6年前 (2018-06-27) 1746℃ 0评论6喜欢
Apache Spark 2.4 与昨天正式发布,Apache Spark 2.4 版本是 2.x 系列的第五个版本。 如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Spark 2.4 为我们带来了众多的主要功能和增强功能,主要如下:新的调度模型(Barrier Scheduling),使用户能够将分布式深度学习训练恰当地嵌入到 Spark 的 stage 中 w397090770 6年前 (2018-11-09) 3264℃ 0评论1喜欢
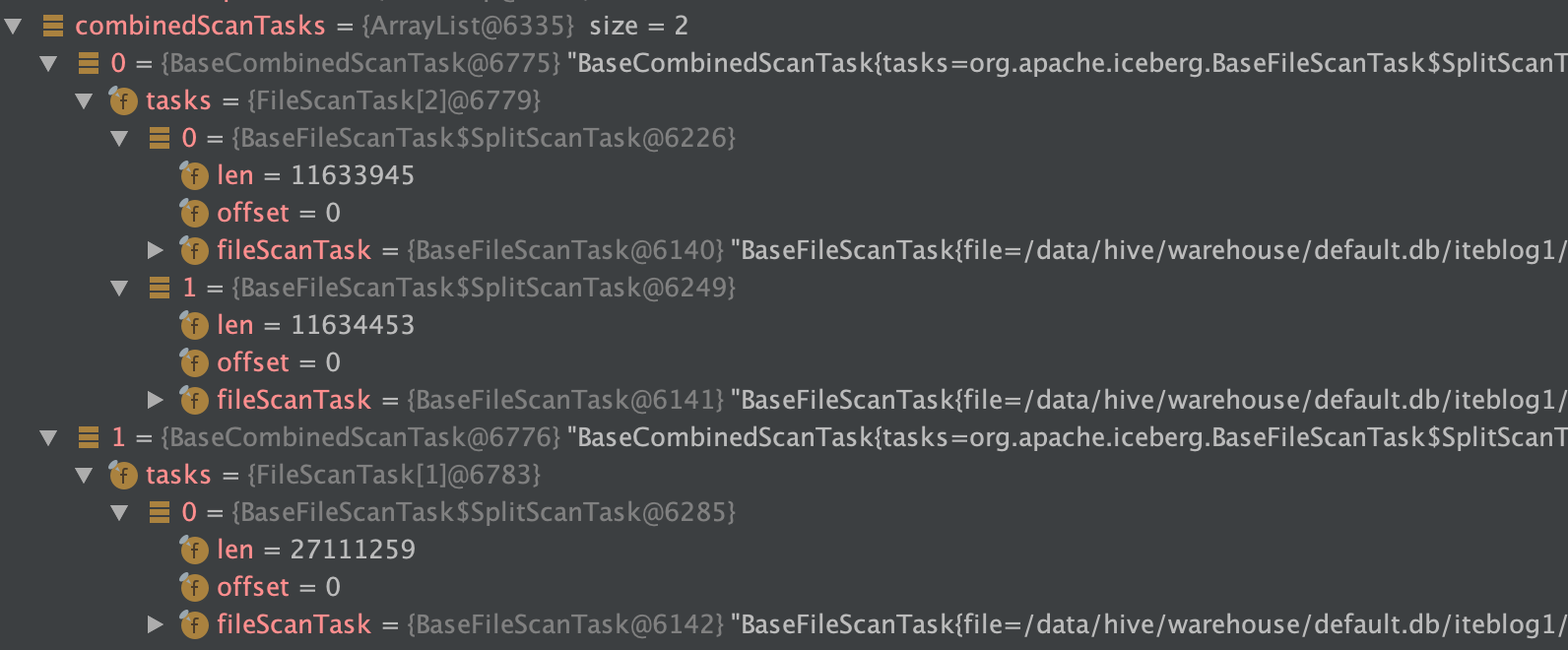
在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中我们分析了 Apache Iceberg 写数据的源码。如下是我们使用 Spark 写两次数据到 Iceberg 表的数据目录布局(测试代码在 这里):[code lang="bash"]/data/hive/warehouse/default.db/iteblog├── data│ └── ts_year=2020│ ├── id_bucket=0│ │ ├── 00000-0-19603f5a-d38a w397090770 3年前 (2020-11-20) 6153℃ 6评论8喜欢
为当前RDD设置检查点。该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用SparkContext.setCheckpointDir()设置的。在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移出。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。函数原型[code lang="scala"]def checkpoint()[/code]实例 w397090770 9年前 (2015-03-08) 60511℃ 0评论7喜欢
本书于2017-08由 Packt 出版,作者 Manish Kumar, Chanchal Singh,全书269页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Learn the basics of Apache Kafka from scratchUse the basic building blocks of a streaming applicationDesign effective streaming applications with Kafka using Spark, Storm &, and HeronUnderstand the i zz~~ 7年前 (2017-11-08) 6577℃ 0评论30喜欢
在2020年6月24日的 Spark AI summit Keynote 上,数砖的首席执行官 Ali Ghodsi 宣布其收购了 Redash 开源产品的背后公司 Redash!如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop通过这次收购,Redash 加入了 Apache Spark、Delta Lake 和 MLflow,创建了一个更大、更繁荣的开源系统,为数据团队提供了同类中最好的 w397090770 4年前 (2020-06-26) 840℃ 0评论3喜欢
为期三天的 SPARK + AI SUMMIT Europe 2019 于 2019年10月15日-17日荷兰首都阿姆斯特丹举行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。Spark+AI Summit Europe 2019 是欧洲最大的数据和机器学习会议,大约有1700多名数据科学家、工程师和分析师参加此次会议。本次会议的提议包括了A w397090770 5年前 (2019-11-01) 996℃ 0评论1喜欢
本 hosts 文件更新时间为 2018年07月22日。原作者为 Google Hosts 组织本页面长期更新最新 Google、谷歌学术、维基百科、ccFox.info、ProjectH、3DM、Battle.NET 、WordPress、Microsoft Live、GitHub、Box.com、SoundCloud、inoreader、Feedly、FlipBoard、Twitter、Facebook、Flickr、imgur、DuckDuckGo、Ixquick、Google Services、Google apis、Android、Youtube、Google Drive、UpLoad、Appspot、 w397090770 6年前 (2018-01-09) 15987℃ 1评论43喜欢
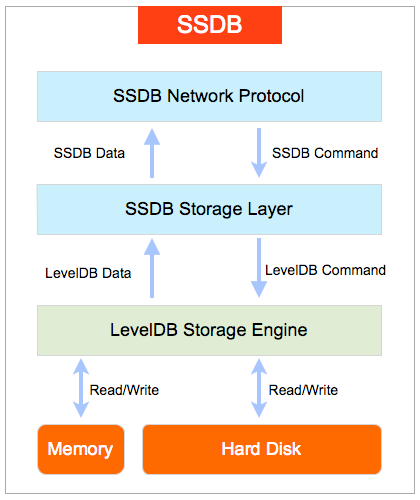
SSDB 是一个使用 C/C++ 语言开发的高性能 NoSQL 数据库, 支持 KV, list, map(hash), zset(sorted set) 等数据结构, 用来替代或者与 Redis 配合存储十亿级别列表的数据。实现上其使用了 Google 的 LevelDB作为存储引擎,SSDB 不会像 Redis 一样狂吃内存,而是将大部分数据存储到磁盘上。最重要的是,SSDB采用了New BSD License 开源协议进行了开源,目前已经 w397090770 7年前 (2017-05-27) 2838℃ 0评论7喜欢
Spark和Kafka都是比较常用的两个大数据框架,Spark里面提供了对Kafka读写的支持。默认情况下我们Kafka只能写Byte数组到Topic里面,如果我们想往Topic里面读写String类型的消息,可以分别使用Kafka里面内置的StringEncoder编码类和StringDecoder解码类。那如果我们想往Kafka里面写对象怎么办? 别担心,Kafka中的kafka.serializer里面有Decoder和En w397090770 9年前 (2015-03-26) 21291℃ 11评论16喜欢
4月6日,Apache Hadoop 3.1.0 正式发布了,Apache Hadoop 3.1.0 是2018年 Hadoop-3.x 系列的第一个小版本,并且带来了许多增强功能。不过需要注意的是,这个版本并不推荐在生产环境下使用,如果需要在正式环境下使用,请等待 3.1.1 或 3.1.2 版本。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop这个版 w397090770 6年前 (2018-04-08) 3468℃ 0评论15喜欢
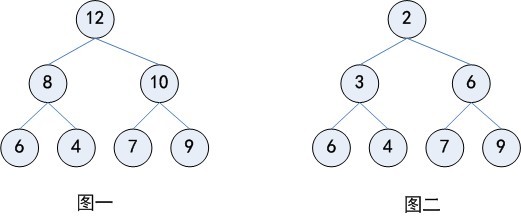
堆常用来实现优先队列,在这种队列中,待删除的元素为优先级最高(最低)的那个。在任何时候,任意优先元素都是可以插入到队列中去的,是计算机科学中一类特殊的数据结构的统称一、堆的定义最大(最小)堆是一棵每一个节点的键值都不小于(大于)其孩子(如果存在)的键值的树。大顶堆是一棵完全二叉树,同时也是 w397090770 11年前 (2013-04-01) 4770℃ 0评论3喜欢
VSFTP是一个基于GPL发布的类Unix系统上使用的FTP服务器软件,它的全称是Very Secure FTP 从此名称可以看出来,编制者的初衷是代码的安全。本文将介绍如何在CentOS系统上安装、部署和卸载vsftp。1. 安装VSFTP[code lang="bash"][iteblog@www.iteblog.com ~]# yum -y install vsftpd[/code]2. 配置vsftpd.conf文件[code lang="bash"][iteblog@www.iteblog.com ~]# v w397090770 8年前 (2016-04-16) 2035℃ 0评论3喜欢
概论 SparkR是一个R语言包,它提供了轻量级的方式使得可以在R语言中使用Apache Spark。在Spark 1.4中,SparkR实现了分布式的data frame,支持类似查询、过滤以及聚合的操作(类似于R中的data frames:dplyr),但是这个可以操作大规模的数据集。SparkR DataFrames DataFrame是数据组织成一个带有列名称的分布式数据集。在概念上和关系 w397090770 9年前 (2015-06-09) 36536℃ 1评论50喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章中简单地介绍了Spark 2.0带来的新技术等。Spark 2.0是Apache Spark的下一个主要版本。此版本在架构抽象、API以及平台的类库方面带来了很大的变化,为该框架明年的发展奠定了方向,所以了解Spark 2.0的一些特性对我们能够使用它有着非常重要的作用。本博客将对Spark 2.0进行一序列的介 w397090770 8年前 (2016-07-14) 7546℃ 2评论4喜欢
最近使用ElasticSearch的时候遇到以下的异常[code land="bash"]2017-07-27 16:06:48.482 MessageHandler - message process error: java.lang.NoClassDefFoundError: Could not initialize class org.elasticsearch.common.xcontent.smile.SmileXContent at org.elasticsearch.common.xcontent.XContentFactory.contentBuilder(XContentFactory.java:124) ~[elasticsearch-2.3.4.jar:2.3.4] at org.elasticsearch.action.support.ToX w397090770 7年前 (2017-07-27) 8536℃ 0评论13喜欢
一、定义位图法就是bitmap的缩写。所谓bitmap,就是用每一位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况。通常是用来判断某个数据存不存在的。在STL中有一个bitset容器,其实就是位图法,引用bitset介绍:A bitset is a special container class that is designed to store bits (elements with only two possible values: 0 or 1,true or false, . w397090770 11年前 (2013-04-03) 8592℃ 0评论8喜欢
Programming Hive: Data Warehouse and Query Language for Hadoop 1st Edition 于2012年09月出版,全书共350页,是学习Hive经典的一本书。图书信息如下:Publisher : O'Reilly Media; 1st edition (October 16, 2012)Language : EnglishPaperback : 350 pagesISBN-10 : 1449319335ISBN-13 : 978-1449319335这本指南将向您介绍 Apache Hive, 它是 Hadoop 的数据仓库基础设施。通过这本书将快速 w397090770 9年前 (2015-08-25) 38289℃ 3评论21喜欢
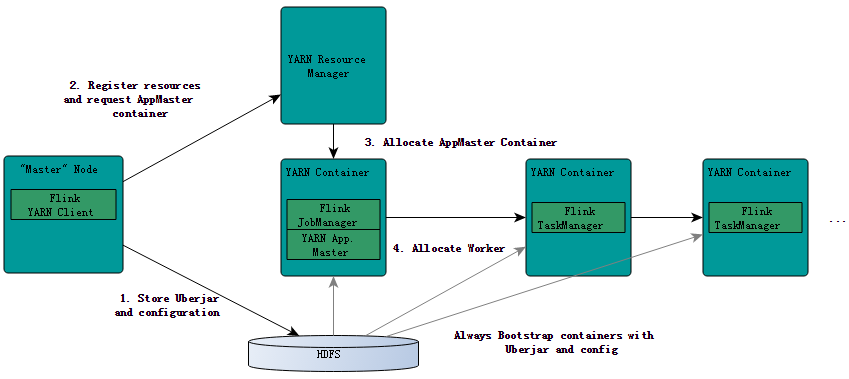
在前面(《Flink on YARN部署快速入门指南》的文章中我们简单地介绍了如何在YARN上提交和运行Flink作业,本文将简要地介绍Flink是如何与YARN进行交互的。 YRAN客户端需要访问Hadoop的相关配置文件,从而可以连接YARN资源管理器和HDFS。它使用下面的规则来决定Hadoop配置: 1、判断YARN_CONF_DIR,HADOOP_CONF_DIR或HADOOP_CONF_PATH等环境 w397090770 8年前 (2016-04-04) 5991℃ 0评论8喜欢
在编写程序的时候,很多时候都需要检查输入的参数是否符合我们的需要,比如人的年龄需要大于0,名字不能为空;如果不符合这两个要求,我们将认为这个对象是不合法的,这时候我们需要编写判断这些参数是否合法的函数,我们可能这样写:[code lang="JAVA"]package com.wyp;import java.util.ArrayList;import java.util.List;/** * Crea w397090770 11年前 (2013-07-24) 6004℃ 4评论2喜欢
我们在用Maven编译项目的时候有时老是出现无法下载某些jar依赖从而导致整个工程编译失败,这时候我们可以修改jar下载的源(也就是repositorie)即可,下面是Maven的用法,你可以在你项目的pom文件里面加入这些代码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop[code lang="JAVA"]<!-- **** w397090770 10年前 (2014-07-25) 12932℃ 1评论13喜欢
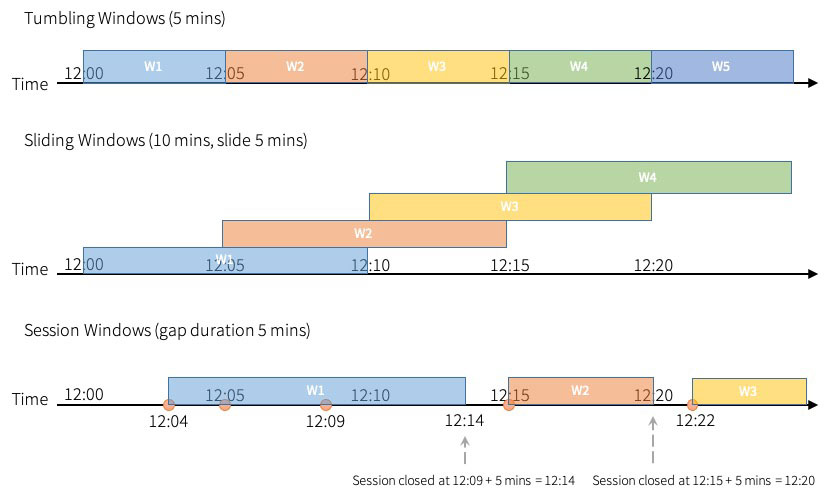
Apache Spark™ Structured Streaming 允许用户在事件时间的窗口上进行聚合。 在 Apache Spark 3.2™ 之前,Spark 支持滚动窗口(tumbling windows)和滑动窗口( sliding windows)。在已经发布的 Apache Spark 3.2 中,社区添加了“会话窗口(session windows)”作为新支持的窗口类型,它适用于流查询和批处理查询什么是会话窗口如果想及时了解Spark、Had w397090770 3年前 (2021-10-21) 638℃ 0评论0喜欢
题目要求:实现一个加法器,使其能够输出a+b的值。输入:输入包括两个数a和b,其中a和b的位数不超过1000位。输出:可能有多组测试数据,对于每组数据,输出a+b的值。样例输入:2 610000000000000000000 10000000000000000000000000000000样例输出:810000000000010000000000000000000我的实现:[code lang="CPP"]#include <iostream>#inclu w397090770 11年前 (2013-03-31) 3226℃ 0评论3喜欢

![[电子书]Spark GraphX in Action PDF下载](https://www.iteblog.com/pic/books/Spark_Graphx_in_Action_iteblog.png)






![[电子书]Building Data Streaming Applications with Apache Kafka PDF下载](https://www.iteblog.com/pic/books/building-data-streaming-applications-apache-kafka-iteblog.png)

![Spark+AI Summit Europe 2019 高清视频下载[共135个]](https://www.iteblog.com/pic/spark/spark+ai_summit_europe_2019-iteblog.jpg)