哎哟~404了~休息一下,下面的文章你可能很感兴趣:
从名字就可以看出这是笛卡儿的意思,就是对给的两个RDD进行笛卡儿计算。官方文档说明:Return the Cartesian product of this RDD and another one, that is, the RDD of all pairs of elements (a, b) where a is in `this` and b is in `other`.函数原型[code lang="scala"]def cartesian[U: ClassTag](other: RDD[U]): RDD[(T, U)][/code] 该函数返回的是Pair类型的RDD,计算结果 w397090770 9年前 (2015-03-07) 11176℃ 0评论5喜欢
2019年10月22日上午 Databricks 宣布,已经完成了由安德森-霍洛维茨基金(Andreessen Horowitz)牵头的4亿美元F轮融资,参与融资的有微软(Microsoft)、Alkeon Capital Management、贝莱德(BlackRock)、Coatue Management、Dragoneer Investment Group、Geodesic、Green Bay Ventures、New Enterprise Associates、T. Rowe Price和Tiger Global Management。经过这次融资,Databricks 的估值高达62亿美 w397090770 5年前 (2019-10-22) 1088℃ 0评论0喜欢
Raptor 是一个 Presto connector (presto-raptor),用于支持 Meta(以前的 Facebook)中的一些关键的交互式查询工作负载。尽管在 ICDE 2019 年的论文《Presto: SQL on Everything》中提到了这个特性,但对于许多 Presto 用户来说,它仍然有些神秘,因为没有关于这个特性的可用文档。本文将介绍 Raptor 的历史,以及为什么 Meta 最终取代了它,转而支持一种 w397090770 2年前 (2022-03-06) 321℃ 0评论0喜欢
大家肯定都知道要想在国内下载一个项目到本地速度太慢了。可以试试下面方案,把原地址:https://github.com/xxx.git 替换为:https://github.com.cnpmjs.org/xxx.git 即可。比如我们要克隆下面项目到本地,可以操作如下:[code lang="bash"][root@iteblog.com ~]$ git clone https://github.com.cnpmjs.org/397090770/web正克隆到 'web'...Username for 'https://github.com.cnpmjs.org w397090770 5年前 (2019-06-14) 841℃ 0评论1喜欢
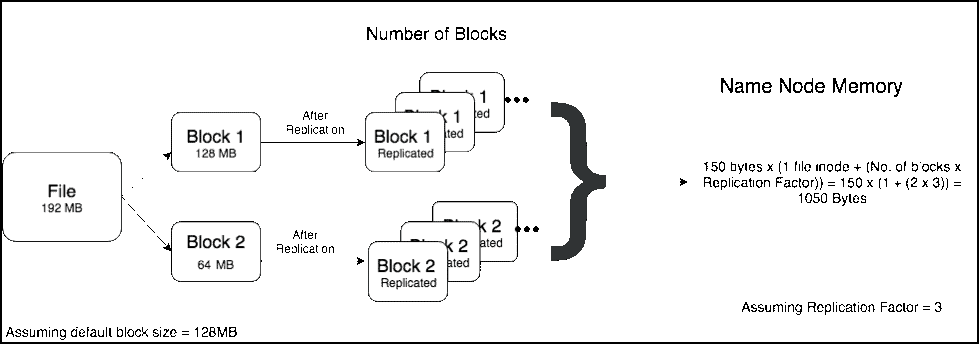
背景随着集群规模的不断扩张,文件数快速增长,目前集群的文件数已高达2.7亿,这带来了许多问题与挑战。首先是文件目录树的扩大导致的NameNode的堆内存持续上涨,其次是Full GC时间越来越长,导致NameNode宕机越发频繁。此外,受堆内存的影响,RPC延时也越来越高。针对上述问题,我们做了一些相关工作:控制文件数增长 w397090770 3年前 (2021-07-02) 1115℃ 0评论2喜欢
为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 5年前 (2019-09-23) 12317℃ 0评论31喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 北京第五次Spark meetup会议 w397090770 9年前 (2015-01-31) 3712℃ 0评论4喜欢
在使用Hadoop过程中,小文件是一种比较常见的挑战,如果不小心处理,可能会带来一系列的问题。HDFS是为了存储和处理大数据集(M以上)而开发的,大量小文件会导致Namenode内存利用率和RPC调用效率低下,block扫描吞吐量下降,应用层性能降低。通过本文,我们将定义小文件存储的问题,并探讨如何对小文件进行治理。什么是小 w397090770 3年前 (2021-02-24) 968℃ 0评论4喜欢
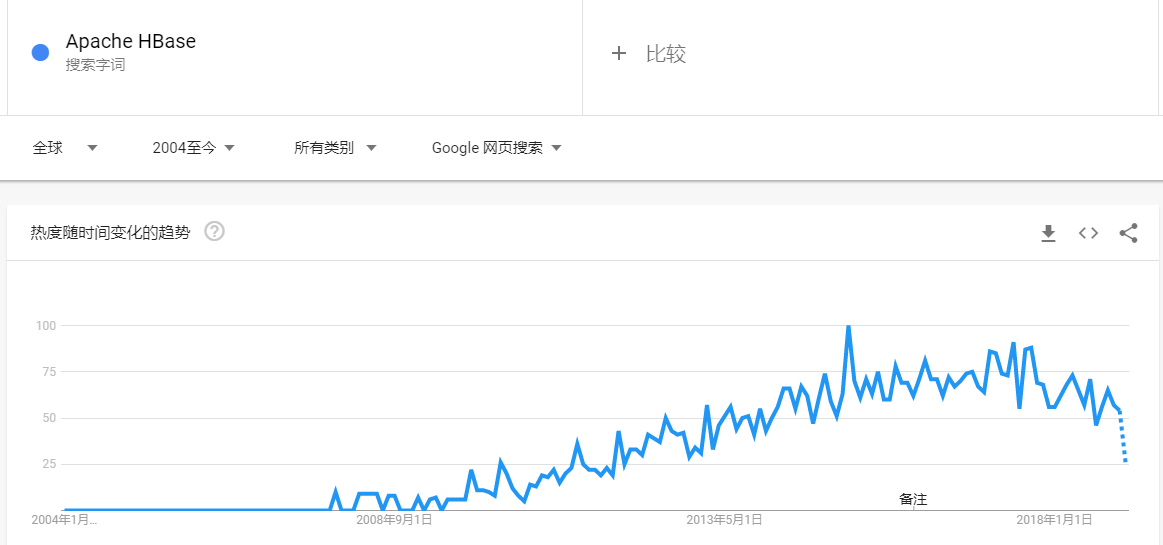
Apache HBase是基于Hadoop构建的一个分布式的、可伸缩的海量数据存储系统。随着时间的推移,HBase目前不管是在国内还是国外都受到了非常大的欢迎,以下分别是近几年 Google 和百度关于 HBase 的搜索趋势:Google如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop大家可以看到,整体趋势是越来越 w397090770 5年前 (2019-01-05) 3440℃ 4评论15喜欢
由CSDN主办OpenCloud 2015大会于4月16日-18日在国家会议中心成功举办。“2015 OpenStack技术大会”、“2015 Spark技术峰会”、“2015 Container技术峰会”三大峰会及三场深度行业实战培训赢得了讲师和听众们高度认可,40余位一线专家的深度主题演讲赢得阵阵掌声。 2015 spark技术峰会.pushed{color:#f60;}时间议题演讲者09: w397090770 9年前 (2015-04-28) 7525℃ 0评论2喜欢
本文是 Forest Rim Technology 数据团队撰写的,作者 Bill Inmon 和 Mary Levins,其中 Bill Inmon 被称为是数据仓库之父,最早的数据仓库概念提出者,被《计算机世界》评为计算机行业历史上最具影响力的十大人物之一。原始数据的挑战随着大量应用程序的出现,产生了相同的数据在不同地方出现不同值的情况。为了做出决定,用户必须找 w397090770 3年前 (2021-05-25) 553℃ 0评论0喜欢
本文转载至 http://www.ibm.com/developerworks/cn/java/j-dcl.html 单例创建模式是一个通用的编程习语。和多线程一起使用时,必需使用某种类型的同步。在努力创建更有效的代码时,Java 程序员们创建了双重检查锁定习语,将其和单例创建模式一起使用,从而限制同步代码量。然而,由于一些不太常见的 Java 内存模型细节的原因,并不能 w397090770 11年前 (2013-10-18) 4605℃ 4评论6喜欢
Spark 1.1.0马上就要发布了(估计就是明天),其中更新了很多功能。其中对Spark SQL进行了增强: 1、Spark 1.0是第一个预览版本( 1.0 was the first “preview” release); 2、Spark 1.1 将支持Shark更新(1.1 provides upgrade path for Shark), (1)、Replaced Shark in our benchmarks with 2-3X perfgains; (2)、Can perform optimizations with 10- w397090770 10年前 (2014-09-11) 7749℃ 2评论5喜欢
Apache Spark 2.4 是在11月08日正式发布的,其带来了很多新的特性具体可以参见这里,本文主要介绍这次为复杂数据类型新引入的内置函数和高阶函数。本次 Spark 发布共引入了29个新的内置函数来处理复杂类型(例如,数组类型),包括高阶函数。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop w397090770 5年前 (2018-11-21) 2444℃ 0评论2喜欢
《Spark Python API函数学习:pyspark API(1)》 《Spark Python API函数学习:pyspark API(2)》 《Spark Python API函数学习:pyspark API(3)》 《Spark Python API函数学习:pyspark API(4)》 Spark支持Scala、Java以及Python语言,本文将通过图片和简单例子来学习pyspark API。.wp-caption img{ max-width: 100%; height: auto;}如果想 w397090770 9年前 (2015-06-28) 36407℃ 0评论78喜欢
有多个地方需要使用Java client: 1、在存在的集群中执行标准的index, get, delete和search 2、在集群中执行管理任务 3、当你要运行嵌套在你的应用程序中的Elasticsearch的时候或者当你要运行单元测试或者集合测试的时候,启动所有节点获得一个Client是非常容易的,最通用的步骤如下所示: 1、创建一个嵌套的 zz~~ 8年前 (2016-10-02) 1113℃ 0评论7喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Best Practice in Accelerating Data Applications with Spark+Alluxio》的分享,作者来自 Alluxio 的 David Zhu。本次演讲将分享 Alluxio 和 Spark 集成解决方案的设计和用例,以及在设计和实现 Alluxio分 布式系统时的最佳实践以及不要做什么。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信 w397090770 3年前 (2021-10-28) 516℃ 0评论0喜欢
大年初二Apache CarbonData迎来了第四个稳定版本CarbonData 1.0.0。CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。CarbonData 1.0.0版本,一共带来了80+ 个新特性,并且有100+ 个bugfi w397090770 7年前 (2017-01-29) 2701℃ 0评论6喜欢
在开发Wordpress的时候,我们可能需要获取到设备的类型,比如手机、电脑或者iPad等,然后做出不同的决定,这就要求我们精确地判断出当前设备的类型。熟悉Wordpress的同学会知道,Wordpress中安装目录下的wp-includes/vars.php文件里面有个名为wp_is_mobile的函数,其代码如下:[code lang="php"]function wp_is_mobile() { static $is_mobile = null; w397090770 8年前 (2016-03-01) 2067℃ 0评论1喜欢
Spark 1.1.1于美国时间的2014年11月26日正式发布。基于branch-1.1分支,主要修复了一些bug。推荐所有的1.1.0用户更新到这个稳定版本。本次更新共有55位开发者参与。 spark.shuffle.manager仍然使用Hash作为默认值,说明了SORT的Shuffle还不怎么成熟。等待1.2版本吧。Fixes Spark 1.1.1修复了几个组件的bug。在下面将会列出一些代表性的b w397090770 10年前 (2014-11-28) 3237℃ 0评论5喜欢
一致性问题在介绍分布式系统一致性问题之前,我们先来了解一下副本概念。分布式系统会存在许多异常问题,比如机器宕机;为了提供高可用服务,一般会将数据或者服务部署到很多机器上,这些机器中的数据或服务可以称为副本。如果其中任何一台节点出现故障,用户可以访问其他机器上的数据或服务。由于副本的存在,如 w397090770 6年前 (2018-05-04) 4538℃ 0评论10喜欢
多年以来,社区一直在努力改进 Spark SQL 的查询优化器和规划器,以生成高质量的查询执行计划。最大的改进之一是基于成本的优化(CBO,cost-based optimization)框架,该框架收集并利用各种数据统计信息(如行数,不同值的数量,NULL 值,最大/最小值等)来帮助 Spark 选择更好的计划。这些基于成本的优化技术很好的例子就是选择正确 w397090770 4年前 (2020-05-30) 1590℃ 0评论4喜欢
本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Presto at Tencent at Scale Usability Extension Stability Improvement》,分享者Junyi Huang 和 Pan Liu,均为腾讯软件工程师。Presto 已被腾讯采用为不同业务部门提供临时查询和交互式查询场景。在这次演讲中,作者将分享腾讯在生产中关于 Presto 的实践。关注 过往记忆大数据公众 w397090770 2年前 (2021-12-19) 616℃ 0评论0喜欢
根据官方文档(Apache Hadoop MapReduce - Migrating from Apache Hadoop 1.x to Apache Hadoop 2.x:http://hadoop.apache.org/docs/r2.2.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduce_Compatibility_Hadoop1_Hadoop2.html)所述,Hadoop2.x是对Hadoop1.x程序兼容的,由于Hadoop2.x对Hadoop1.x做了重大的结构调整,很多程序依赖库被拆分了,所以以前(Hadoop1.x)的依赖库不再可 w397090770 11年前 (2013-11-26) 9544℃ 3评论2喜欢
在进程运行过程中,若其所要访问的页面不在内存而需把它们调入内存,但内存已无空闲空间时,为了保证该进程能正常运行,系统必须从内存中调出一页程序或数据送磁盘的对换区中。但应将哪个页面调出,须根据一定的算法来确定。通常,把选择换出页面的算法称为页面置换算法(Page-Replacement Algorithms)。置换算法的好坏,将直接 w397090770 11年前 (2013-04-11) 5337℃ 0评论2喜欢
最近由于项目需要把Flume收集到的日志信息插入到Hbase中,由于第一次接触这些,在整合的过程中,我遇到了许多问题,我相信很多人也应该会遇到这些问题的,于是我把整个整合的过程写出来,希望给那些同样遇到这样问题的朋友帮助。 在使用Flume的时候,请确保你电脑里面已经搭建好Hadoop、Hbase、Zookeeper以及Flume。本文 w397090770 10年前 (2014-01-21) 11269℃ 6评论1喜欢
Hive可以运行保存在文件里面的一条或多条的语句,只要用-f参数,一般情况下,保存这些Hive查询语句的文件通常用.q或者.hql后缀名,但是这不是必须的,你也可以保存你想要的后缀名。假设test文件里面有一下的Hive查询语句:[code lang="JAVA"]select * from p limit 10;select count(*) from p;[/code]那么我们可以用下面的命令来查询:[cod w397090770 11年前 (2013-11-06) 10033℃ 2评论5喜欢
这个问题可能很多面试的人都遇到过,很多人可能想利用循环来判断,代码可能如下所示:[code lang="JAVA"] public static boolean isPowOfTwo(int n) { int temp = 0; for (int i = 1; ; i++) { temp = (int) Math.pow(2, i); if (temp >= n) break; } if (temp == n) return true; else return false; }[/code] w397090770 11年前 (2013-09-17) 11493℃ 6评论14喜欢
数据库事业部承载着阿里巴巴及阿里云的数据库服务,为超过数万家中国企业提供专业的数据库服务。我们提供在线事务处理、缓存文档服务、BigData NoSQL服务 、在线分析处理的全栈数据库产品。本团队提供基于Apache HBase\Phoenix\Spark\Cassandra\Solr\ES等,结合自研技术,打造存储、检索、计算的一站式的BigData NoSQL自主可控的服务,满足客 w397090770 6年前 (2018-01-30) 6452℃ 1评论28喜欢
《Spark Streaming作业提交源码分析接收数据篇》、《Spark Streaming作业提交源码分析数据处理篇》 在昨天的文章中介绍了Spark Streaming作业提交的数据接收部分的源码(《Spark Streaming作业提交源码分析接收数据篇》),今天来介绍Spark Streaming中如何处理这些从外部接收到的数据。 在调用StreamingContext的start函数的时候, w397090770 9年前 (2015-04-29) 4324℃ 2评论9喜欢






![OpenCloud 2015大会PPT资料免费下载[Spark篇]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/2.jpg)