哎哟~404了~休息一下,下面的文章你可能很感兴趣:
基本格式f1 f2 f3 f4 f5 program分 时 日 月 周 命令 第1列表示分钟1~59每分钟用*或者 */1表示;第2列表示小时1~23(0表示0点);第3列表示日期1~31;第4列表示月份1~12;第5列标识号星期0~6(0表示星期天);第6列要运行的命令 当 f1 为 * 时表示每分钟都要执行 program,f2 为* 时表示每小时都要执行程序, w397090770 9年前 (2015-02-22) 3879℃ 0评论7喜欢
一、前言随着大数据技术的飞速发展,海量数据存储和计算的解决方案层出不穷,生产环境和大数据环境的交互日益密切。数据仓库作为海量数据落地和扭转的重要载体,承担着数据从生产环境到大数据环境、经由大数据环境计算处理回馈生产应用或支持决策的重要角色。数据仓库的主题覆盖度、性能、易用性、可扩展性及数 w397090770 4年前 (2020-03-01) 1960℃ 0评论7喜欢
在介绍 HBase 是不是列式存储数据库之前,我们先来了解一下什么是行式数据库和列式数据库。行式数据库和列式数据库在维基百科里面,对行式数据库和列式数据库的定义为:列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理(OLAP)和即时查询。相对应的是行式数据库,数据以行相关的存储体 w397090770 5年前 (2019-01-08) 6098℃ 0评论31喜欢
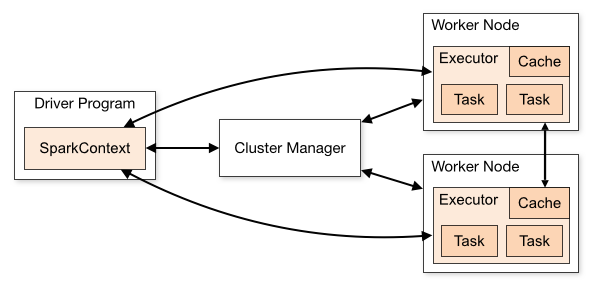
背景熟悉 Spark 的同学都知道,Spark 作业启动的时候我们需要指定 Exectuor 的个数以及内存、CPU 等信息。但是在 Spark 作业运行的时候,里面可能包含很多个 Stages,这些不同的 Stage 需要的资源可能不一样,由于目前 Spark 的设计,我们无法对每个 Stage 进行细粒度的资源设置。而且即使是一个资深的工程师也很难准确的预估一个比较 w397090770 4年前 (2020-01-10) 1394℃ 0评论2喜欢
数据库事业部承载着阿里巴巴及阿里云的数据库服务,为超过数万家中国企业提供专业的数据库服务。我们提供在线事务处理、缓存文档服务、BigData NoSQL服务 、在线分析处理的全栈数据库产品。本团队提供基于Apache HBase\Phoenix\Spark\Cassandra\Solr\ES等,结合自研技术,打造存储、检索、计算的一站式的BigData NoSQL自主可控的服务,满足客 w397090770 6年前 (2018-01-30) 6452℃ 1评论28喜欢
今天我想开通博客的二级域名(http://download.iteblog.com/),然后在nginx配置文件里面配置好了。那个域名可以正常访问,但是如果用户输入了http://bbs.iteblog.com/这个也当作一个二级页面进行处理,但是我博客没有bbs这个二级域名,所以会导致访问失败,我想把除了http://download.iteblog.com/二级之外的其他二级域名都重定向到/中去,于是 w397090770 9年前 (2015-01-01) 20872℃ 0评论2喜欢
SPARK SUMMIT 2015会议于美国时间2015年06月15日到2015年06月17日在San Francisco(旧金山)进行,目前PPT已经全部公布了,不过很遗憾的是这个网站被墙了,无法直接访问,本博客将这些PPT全部整理免费下载。由于源网站限制,一天只能只能下载20个PPT,所以我只能一天分享20篇。如果想获取全部的PPT,请关站本博客。会议主旨 T w397090770 9年前 (2015-07-09) 3370℃ 1评论3喜欢
建议用Spark 1.3.0提供的写关系型数据库的方法,参见《Spark RDD写入RMDB(Mysql)方法二》。 在《Spark与Mysql(JdbcRDD)整合开发》文章中我们介绍了如何通过Spark读取Mysql中的数据,当时写那篇文章的时候,Spark还未提供通过Java来使用JdbcRDD的API,不过目前的Spark提供了Java使用JdbcRDD的API。 今天主要来谈谈如果将Spark计算的结果 w397090770 9年前 (2015-03-10) 36811℃ 5评论33喜欢
CharSequenceReader类是以CharSequence的形式读取字符。CharSequenceReader类继承自Reader类,除了remaining()、hasRemaining()以及checkOpen()函数之后,其他的函数都是重写Reader类中的函数。CharSequenceReader类声明没有用public关键字,所以我们暂时还不能调用这个类CharSequenceReader类有下面三个成员变量[code lang="JAVA"] private CharSequence seq; //存放 w397090770 11年前 (2013-09-23) 2841℃ 1评论2喜欢
由于Hadoop自身的一些特点,它只适合用于将Linux作为操作系统的生产环境。在实际应用场景中,管理员适当对Linux内核参数进行调优,可在一定程度上提高作业的运行效率,比较有用的调整选项如下。一、增大同时打开的文件描述符和网络连接上限 在Hadoop集群中,由于涉及的作业和任务数目非常多,对于某个节点,由于 w397090770 10年前 (2014-04-02) 12898℃ 1评论7喜欢
2017年已然来临,大数据技术仍然保持着飞速发展。无论是物联网、云计算领域乃至企业技术都开始将其引入自身并作为新的变革方向。众多企业已经在积极接纳大数据技术,并作为提升自身市场竞争力的核心因素。在今天的文章中,我们将基于甲骨文给出的预测结论,总结2017年十项大数据变化趋势。如果想及时了解Spark、H w397090770 7年前 (2017-02-17) 1026℃ 0评论3喜欢
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming、Spark SQL、MLlib、GraphX,这些内建库都提供了高级抽象,可以用非常简洁的代码实现复杂的计算逻辑、这也得益于Scala编程语言的简洁性。这里,我们基于1.3.0版本的Spark搭建了计算平台,实现基于Spark Streaming的实时 w397090770 9年前 (2015-05-30) 37306℃ 2评论76喜欢
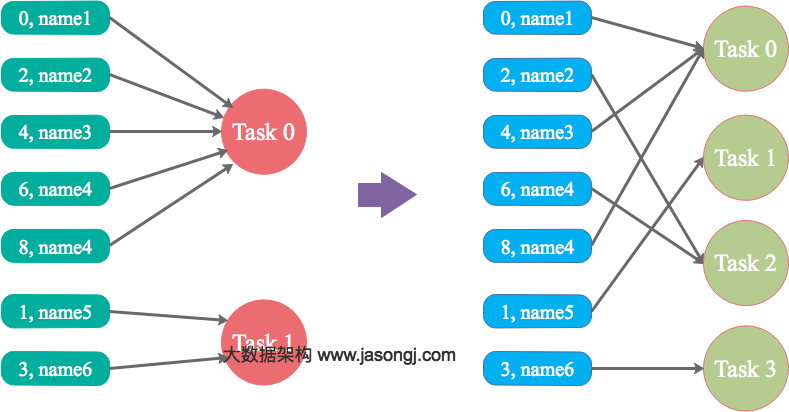
本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitioner,使用Map侧Join代替Reduce侧Join,给倾斜Key加上随机前缀等。为何要处理数据倾斜(Data Skew)什么是数据倾斜对Spark/Hadoop这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。何谓数据倾 w397090770 7年前 (2017-03-07) 13227℃ 2评论27喜欢
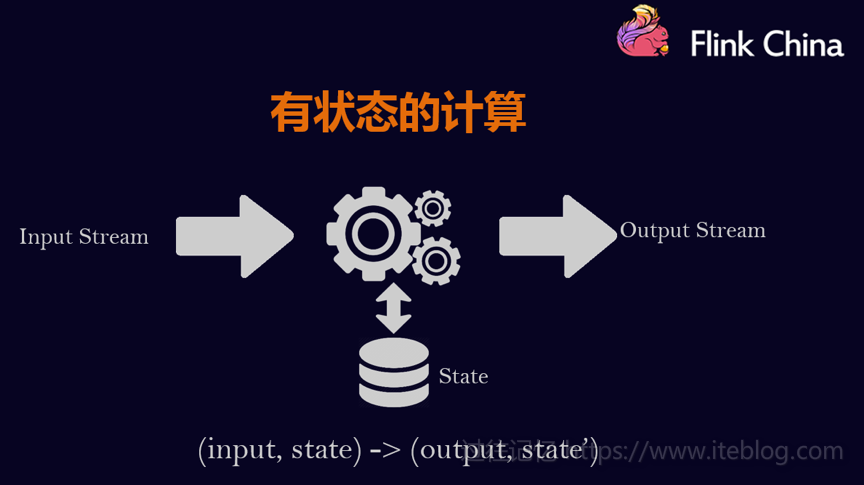
本文整理自8月11日在北京举行的 Flink Meetup 会议,分享嘉宾施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发。本文由韩非(Flink China社区志愿者)整理一、有状态的流数据处理1、什么是有状态的计算计算任务的结果不仅仅依赖于输入,还依赖于它的当前状态,其实大 w397090770 6年前 (2018-08-24) 9052℃ 0评论21喜欢
在《如何快速判断正整数是2的N次幂》文章中我们谈到如何快速的判断给定的正整数是否为2的N次幂,今天来谈谈如何快速地判断一个给定的正整数是否为4的N次幂。将4的幂次方写成二进制形式后,很容易就会发现有一个特点:二进制中只有一个1(1在奇数位置),并且1后面跟了偶数个0; 因此问题可以转化为判断1后面是否跟了 w397090770 11年前 (2013-09-30) 5017℃ 0评论5喜欢
在《ElasticSearch系列文章:基本介绍》中主要介绍了ElasticSearch一些使用场景,本文将对Elasticsearch的核心概念进行介绍,这对后期使用ElasticSearch有着重要的影响。 1、NearRealtime(NRT):准实时Elasticsearch是一个准实时的搜索平台,这意味着当你索引一个文档(document )时,在细微的延迟(通常1s)之后,该文件才能被搜索到。 w397090770 8年前 (2016-08-09) 2401℃ 2评论3喜欢
Solr 介绍Apache Solr 是基于 Apache Lucene™ 构建的流行,快速,开源的企业搜索平台。Solr 具有高可靠性,可扩展性和容错性,可提供分布式索引,复制和负载均衡查询,自动故障转移和恢复以及集中配置等特性。 Solr 为世界上许多大型互联网站点提供搜索和导航功能。Solr 是用 Java 编写、运行在 Servlet 容器(如 Apache Tomcat 或Jetty) w397090770 6年前 (2018-07-24) 2803℃ 0评论3喜欢
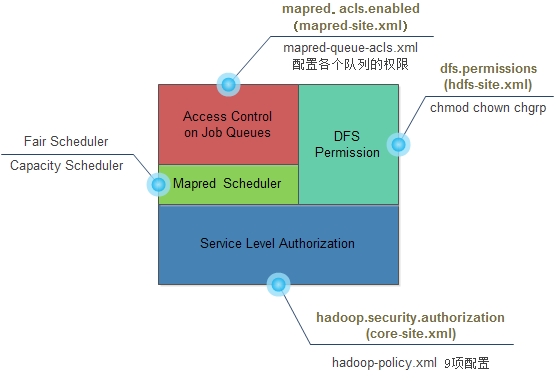
Hadoop在服务层进行了授权(Service Level Authorization)控制,这是一种机制可以保证客户和Hadoop特定的服务进行链接,比如说我们可以控制哪个用户/哪些组可以提交Mapreduce任务。所有的这些配置可以在$HADOOP_CONF_DIR/hadoop-policy.xml中进行配置。它是最基础的访问控制,优先于文件权限和mapred队列权限验证。可以看看下图[caption id="attach w397090770 10年前 (2014-03-20) 8990℃ 0评论8喜欢
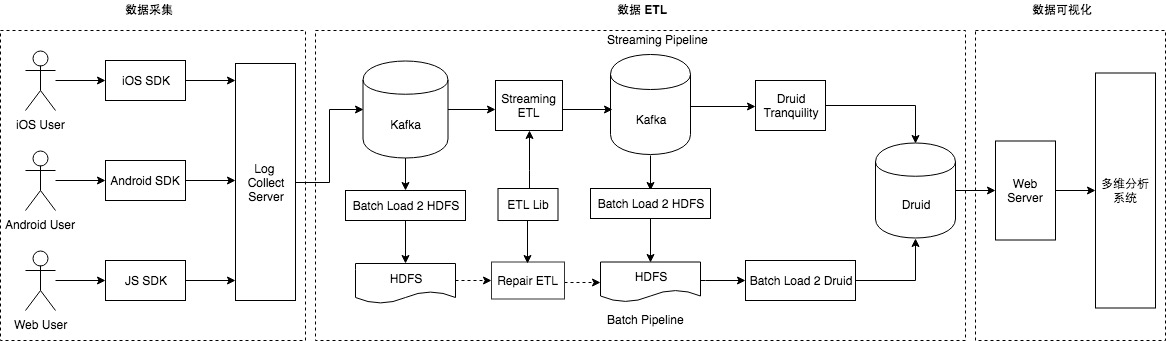
“数据智能” (Data Intelligence) 有一个必须且基础的环节,就是数据仓库的建设,同时,数据仓库也是公司数据发展到一定规模后必然会提供的一种基础服务。从智能商业的角度来讲,数据的结果代表了用户的反馈,获取结果的及时性就显得尤为重要,快速的获取数据反馈能够帮助公司更快的做出决策,更好的进行产品迭代,实时数 w397090770 5年前 (2019-02-16) 24105℃ 1评论46喜欢
在本博客的《Spark读取Hbase中的数据》文章中我谈到了如何用Spark和Hbase整合的过程以及代码的编写测试等。今天我们继续谈谈Spark如何和Flume-ng进行整合,也就是如何将Flune-ng里面的数据发送到Spark,利用Spark进行实时的分析计算。本文将通过Java和Scala版本的程序进行程序的测试。 Spark和Flume-ng的整合属于Spark的Streaming这块。在 w397090770 10年前 (2014-07-08) 23127℃ 4评论17喜欢
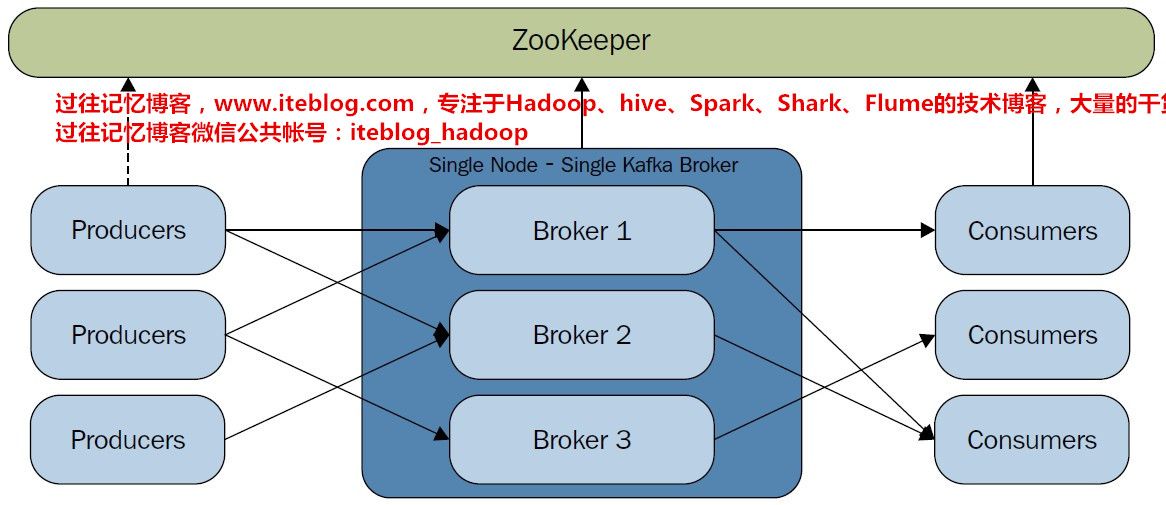
Kafka Cluster模式最大的优点:可扩展性和容错性,下图是关于Kafka集群的结构图:Kafka Broker个数决定因素 磁盘容量:首先考虑的是所需保存的消息所占用的总磁盘容量和每个broker所能提供的磁盘空间。如果Kafka集群需要保留 10 TB数据,单个broker能存储 2 TB,那么我们需要的最小Kafka集群大小 5 个broker。此外,如果启用副 w397090770 8年前 (2016-11-18) 13540℃ 0评论28喜欢
我们在开发网站的时候一般都会分header、main、side、footer。这些模块分别包含了各自公用的信息,比如header一般都是本网站所有页面需要引入的模块,里面一般都是放置菜单等信息;而footer一般是放在网站所有页面的底部。当网页的内容比较多的时候,我们可以看到footer一般都是在页面的底部。但是,当页面的内容不足以填满一 w397090770 9年前 (2015-10-28) 4451℃ 0评论8喜欢
通过使用易于理解的实例,本书将教你如何使用Spark Streaming构建实时应用程序。从安装和设置所需的环境开始,您将编写并执行第一个程序Spark Streaming。接下来将探讨Spark Streaming的架构和组件以及概述Spark公开的库/函数的。接下来,您将通过处理分布式日志文件的用例来了解有关Spark中的各种客户端API编码。然后,您将学习到各 w397090770 7年前 (2017-02-12) 3080℃ 0评论6喜欢
为期三天的 Spark Summit 在美国时间 2018-06-04 ~ 06-06 于旧金山的 Moscone Center 举行,不少人已经注意到,今年的会议已经更名为 Spark+AI, 去年 12 月份时,Databricks 在他们的博客中就已经提到过,2018 年的会议将包括更多人工智能的内容,某种意义上也代表着 Spark 未来的发展方向。作为大数据领域的顶级会议,Spark Summit 2018 吸引了全球近 200 w397090770 6年前 (2018-06-18) 3561℃ 0评论14喜欢
io.file.buffer.size hadoop访问文件的IO操作都需要通过代码库。因此,在很多情况下,io.file.buffer.size都被用来设置缓存的大小。不论是对硬盘或者是网络操作来讲,较大的缓存都可以提供更高的数据传输,但这也就意味着更大的内存消耗和延迟。这个参数要设置为系统页面大小的倍数,以byte为单位,默认值是4KB,一般情况下,可以 w397090770 10年前 (2014-04-01) 30122℃ 2评论14喜欢
我们在学习或者使用Spark的时候都会选择下载Spark的源码包来加强Spark的学习。但是在导入Spark代码的时候,我们会发现yarn模块的相关代码总是有相关类依赖找不到的错误(如下图),而且搜索(快捷键Ctrl+N)里面的类时会搜索不到!这给我们带来了很多不遍。。 本文就是来解决这个问题的。我使用的是Idea IDE工具阅读代 w397090770 9年前 (2015-11-07) 8951℃ 4评论11喜欢
《Learning Spark, 2nd Edition》这本书是由 O'Reilly Media 出版社于2020年7月出版的,作者包括 Jules S. Damji, Brooke Wenig, Tathagata Das, Denny Lee。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书介绍第二版已更新包含了 Spark 3.0 的一些东西,本书向数据工程师和数据科学家展示了 Spark 中结构化和统一 w397090770 4年前 (2020-09-03) 2420℃ 0评论9喜欢
如果你需要将RDD写入到Mysql等关系型数据库,请参见《Spark RDD写入RMDB(Mysql)方法二》和《Spark将计算结果写入到Mysql中》文章。 Spark的功能是非常强大,在本博客的文章中,我们讨论了《Spark和Hbase整合》、《Spark和Flume-ng整合》以及《和Hive的整合》。今天我们的主题是聊聊Spark和Mysql的组合开发。如果想及时了解Spark、Had w397090770 10年前 (2014-09-10) 38581℃ 7评论32喜欢
本资料来自2021年12月09日举办的 PrestoCon 2021,标题为《Presto at Bytedance》Presto 在字节跳动中得到了广泛的应用,如数据仓库、BI工具、广告等。与此同时,字节跳动的 presto 团队也提供了许多重要的特性和优化,如 Hive UDF Wrapper、多个协调器、运行时过滤器等,扩展了 presto 的用法,增强了 presto 的稳定性。下面是字节跳动目前 Presto w397090770 2年前 (2021-12-08) 362℃ 0评论0喜欢
Linux安装软件依赖问题解决办法[code lang="java"][wyp@localhost Downloads]$ rpm -i --aid AdobeReader_chs-8.1.7-1.i486.rpm error: Failed dependencies: libatk-1.0.so.0 is needed by AdobeReader_chs-8.1.7-1.i486 libc.so.6 is needed by AdobeReader_chs-8.1.7-1.i486 libc.so.6(GLIBC_2.0) is needed by AdobeReader_chs-8.1.7-1.i486 libc.so.6(GLIBC_2.1) is needed by AdobeReader_chs-8.1.7-1.i486 libc.so.6(GLIBC_2.1.3) is n w397090770 10年前 (2014-10-09) 7767℃ 0评论4喜欢













![[电子书]Learning Real-time Processing with Spark Streaming PDF下载](https://www.iteblog.com/pic/books/Learning_Real-time_Processing_with_Spark_Streaming-iteblog.jpg)
![Spark Summit North America 201806 全部PPT下载[共147个]](https://www.iteblog.com/pic/spark/spark-summit-north-america-2018-06_iteblog.png)