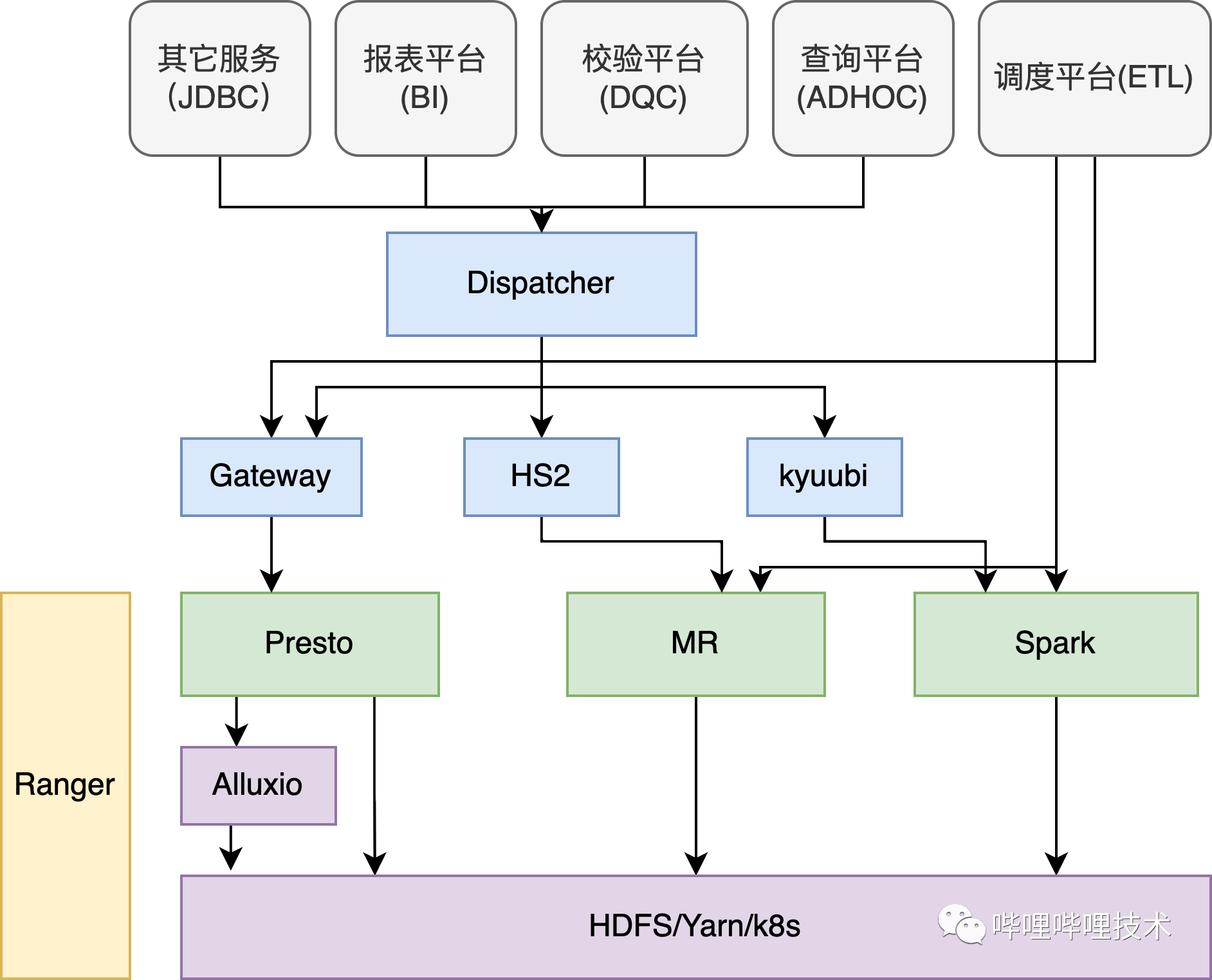
架构B站SQL On Hadoop 整体架构在介绍Presto在B站的实践之前,先从整体来看看SQL在B站的使用情况,在B站的离线平台,核心由三大计算引擎Presto、Spark、Hive以及分布式存储系统HDFS和调度系统Yarn组成。如下架构图所示,我们的ADHOC、BI、DQC以及数据探查等服务都是通过自研的Dispatcher路由服务来进行统一SQL调度,Dispatcher会结合查询 w397090770 2年前 (2022-04-14) 1727℃ 0评论3喜欢
Trino Summit 2021 由 Starburst 于 2021年10月21日-22日通过线上的方式进行。主要分享嘉宾有 Trino 的几个创始人、Apache Iceberg 的创建者 Ryan Blue 以及来自 DoorDash 的 Akshat Nair 和 Satya Boora 等。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop主要分享议题State of TrinoFast results using Iceberg and TrinoThe Future of w397090770 2年前 (2022-04-12) 449℃ 0评论0喜欢
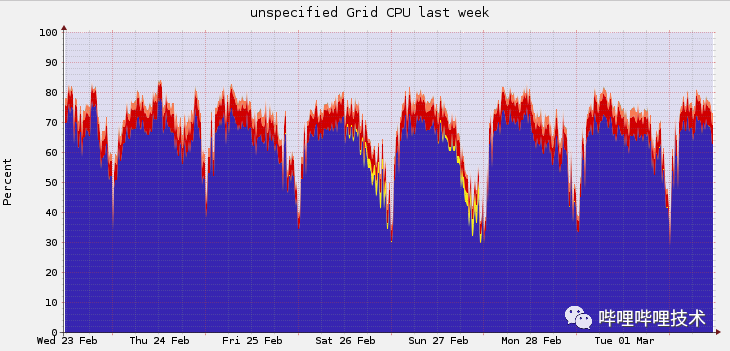
背景 B站的YARN以社区的2.8.4分支构建,采用CapacityScheduler作为调度器, 期间进行过多次核心功能改造,目前支撑了B站的离线业务、实时业务以及部分AI训练任务。2020年以来,随着B站业务规模的迅速增长,集群总规模达到8k左右,其中单集群规模已经达到4k+ ,日均Application(下文简称App)数量在20w到30w左右。当前最大单集群整体cpu w397090770 2年前 (2022-04-11) 672℃ 0评论1喜欢
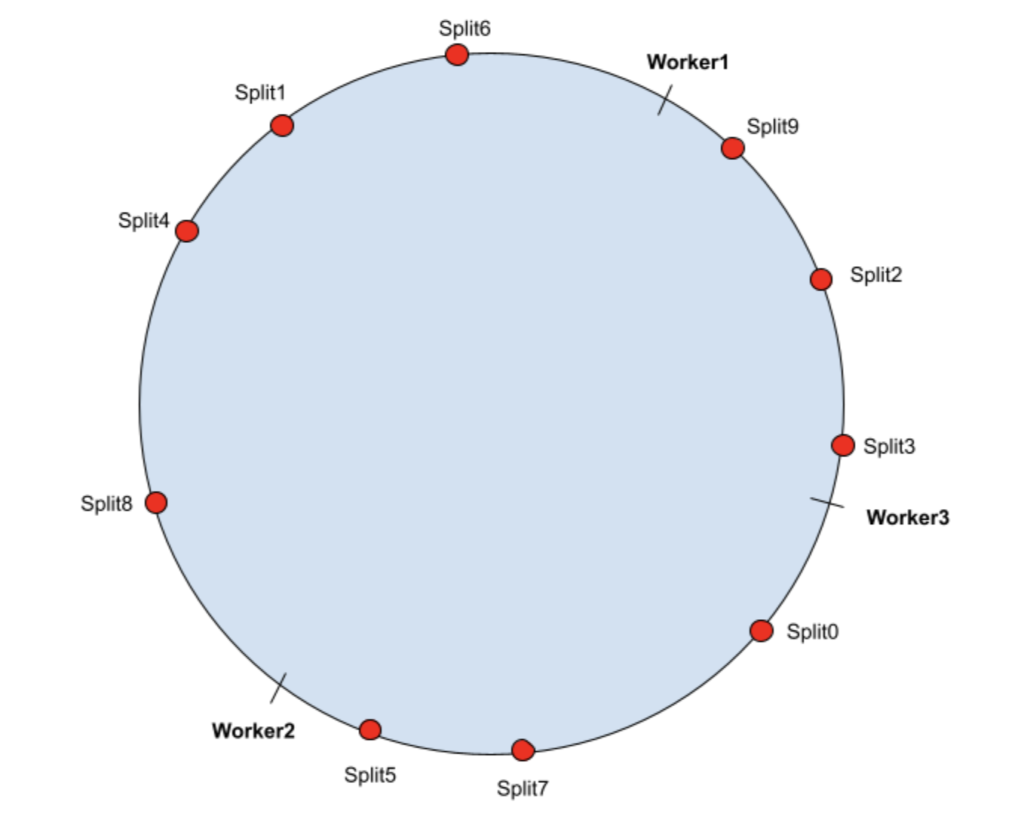
R目前,越来越多的用户开始在 Presto 里面使用 Alluxio,它通过利用 SSD 或内存在 Presto workers 上缓存热数据集,避免从远程存储读取数据。 Presto 支持基于哈希的软亲和调度(hash-based soft affinity scheduling),强制在整个集群中只缓存一到两份相同的数据,通过允许本地缓存更多的热数据来提高缓存效率。 但是,当前使用的哈希算法在集 w397090770 2年前 (2022-04-01) 361℃ 0评论0喜欢
HDFS 架构介绍 HDFS离线存储平台是Hadoop大数据计算的底层架构,在B站应用已经超过5年的时间。经过多年的发展,HDFS存储平台目前已经发展成为总存储数据量近EB级,元数据总量近百亿级,NameSpace 数量近20组,节点数量近万台,日均吞吐几十PB数据量的大型分布式文件存储系统。 首先我们来介绍一下B站的HDFS离线存储平台的总体架 w397090770 2年前 (2022-04-01) 949℃ 0评论3喜欢
本章节我们提供一些 Java 8 中的 IntStream、LongStream 和 DoubleStream 使用范例。IntStream、LongStream 和 DoubleStream 分别表示原始 int 流、 原始 long 流 和 原始 double 流。这三个原始流类提供了大量的方法用于操作流中的数据,同时提供了相应的静态方法来初始化它们自己。这三个原始流类都在 java.util.stream 命名空间下。java.util.stream.Int w397090770 2年前 (2022-03-31) 127℃ 0评论0喜欢
Java 8 流的新类 java.util.stream.Collectors 实现了 java.util.stream.Collector 接口,同时又提供了大量的方法对流 ( stream ) 的元素执行 map and reduce 操作,或者统计操作。本章节,我们就来看看那些常用的方法,顺便写几个示例练练手。Collectors.averagingDouble()Collectors.averagingDouble() 方法将流中的所有元素视为 double 类型并计算他们的平均值 w397090770 2年前 (2022-03-31) 137℃ 0评论0喜欢
金山云-企业云团队(赵侃、李金辉)在交互查询场景下对Presto与Alluxio相结合进行了一系列测试,并总结了一些Presto搭配Alluxio使用的建议。本次测试未使用对象存储,计算引擎与存储间的网络延时也比较低。如果存储IO耗时和网络耗时较大时,Alluxio加速收益应会更明显。测试目的验证影响Alluxio加速收益的各种因素记录Alluxio w397090770 2年前 (2022-03-29) 678℃ 0评论1喜欢
Thrift 最初由Facebook开发,目前已经开源到Apache,已广泛应用于业界。Thrift 正如其官方主页介绍的,“是一种可扩展、跨语言的服务开发框架”。简而言之,它主要用于各个服务之间的RPC通信,其服务端和客户端可以用不同的语言来开发。只需要依照IDL(Interface Description Language)定义一次接口,Thrift工具就能自动生成 C++, Java, Python, PH w397090770 2年前 (2022-03-29) 1604℃ 0评论0喜欢
《Kafka: The Definitive Guide, 2nd Edition》于 2021年11月由 O'Reilly Media 出版, ISBN 为 9781492043089 ,全书 486 页。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop图书介绍Every enterprise application creates data, whether it consists of log messages, metrics, user activity, or outgoing messages. Moving all this data is just as important as the w397090770 2年前 (2022-03-22) 982℃ 0评论3喜欢