哎哟~404了~休息一下,下面的文章你可能很感兴趣:
每个 NodeManager 节点内置提供了检测自身健康状态的机制(详情参见 NodeHealthCheckerService);通过这种机制,NodeManager 会将诊断出来的监控状态通过心跳机制汇报给 ResourceManager,然后ResourceManager 端会通过 RMNodeEventType.STATUS_UPDATE 更新 NodeManager 的状态;如果此时的 NodeManager 节点不健康,那么 ResourceManager 将会把 NodeManager 状态变为 NodeState w397090770 7年前 (2017-06-08) 4081℃ 0评论18喜欢
Shanghai Apache Spark Meetup第十次聚会活动将于2016年09月10日12:30 至 17:20在四星级的上海通茂大酒店 (浦东新区陆家嘴金融区松林路357号)。分享主题1、中国电信在大数据领域上的创新与探索2、函数式编程与RDD3、社交网络中的信息传播4、大数据分析和机器学习5、分布式流式数据处理框架:功能对比以及性能评估详细主 zz~~ 8年前 (2016-09-20) 1780℃ 0评论2喜欢
临时文件是一个暂时用来存储数据的文件。如果使用建立普通文件的方法来创建文件,则可能遇到文件是否存在,是否有文件读写权限的问题。Linux系统下提供的建立唯一的临时文件的方法如下:[code lang="CPP"]#include<stdio.h>char *tmpnam(char *s);FILE *tmpfile();[/code]函数tmpnam()产生一个唯一i的文件名。如果参量为NULL,则在一个内 w397090770 11年前 (2013-04-03) 5288℃ 0评论0喜欢
今天我有一个网站空间到期了,如果去续费空间是可以的,但是那空间是国内的,一般国内的空间都是比较贵,所以我突然想到为什么不一个网站空间配置两个独立的网站呢?虽然网站空间是一样的,但是结果配置可以使得两个不同域名访问的网站不一样,也就是说互不干扰。当然这个前提是你空间所在的服务器支持我们把一 w397090770 11年前 (2013-04-26) 4736℃ 1评论4喜欢
我们在 《一文了解什么是 Docker》 文章中已经介绍了 Docker 是什么,以及为什么需要 Docker 技术。本文将快速介绍一下如何使用 Docker。安装 DockerDocker 是一个开源的商业产品,支持几乎所有的 Linux 发行版,也支持 Mac 以及 Windows 平台。在各平台上又分为两个版本:免费的社区版(Community Edition,缩写为 CE)和收费的企业版(Enterpri w397090770 4年前 (2020-02-02) 804℃ 0评论3喜欢
ResourceManager 内维护了 NodeManager 的生命周期;对于每个 NodeManager 在 ResourceManager 中都有一个 RMNode 与其对应;除了 RMNode ,ResourceManager 中还定义了 NodeManager 的状态(states)以及触发状态转移的事件(event)。具体如下:org.apache.hadoop.yarn.server.resourcemanager.rmnode.RMNode:这是一个接口,每个 NodeManager 都与 RMNode 对应,这个接口主要维 w397090770 7年前 (2017-06-07) 3470℃ 0评论21喜欢
Vim是一个高级文本编辑器,它提供了Unix下编辑器 'Vi' 的功能并对其进行了完善。Vim经常被认为是 "程序员的编辑器",它在程序编写时非常有用,很多人认为它是一个完整的集成开发环境(IDE)。仅管如此,Vim并不只是程序员使用的。Vim可以用于多种文档编辑,从email排版到配置文件编写。 在Ubuntu下安装一个Vim编辑器可以用下面 w397090770 11年前 (2013-07-19) 4965℃ 2评论2喜欢
重庆博尼施科技有限公司是一家商用车全周期方案服务商,利用车联网、云计算、移动互联网技术,在物流领域 为商用车的生产、销售、使用、售后、回收各个环节提供一站式解决方案,其中的新能源车辆监控系统就是由该公司提供的,本文是阿里云客户重庆博尼施科技有限公司介绍如何使用阿里云 HBase 来实现新能源车辆监控系统 w397090770 5年前 (2018-11-29) 4217℃ 2评论16喜欢
在《如何快速判断正整数是2的N次幂》文章中我们谈到如何快速的判断给定的正整数是否为2的N次幂,今天来谈谈如何快速地判断一个给定的正整数是否为4的N次幂。将4的幂次方写成二进制形式后,很容易就会发现有一个特点:二进制中只有一个1(1在奇数位置),并且1后面跟了偶数个0; 因此问题可以转化为判断1后面是否跟了 w397090770 11年前 (2013-09-30) 5017℃ 0评论5喜欢
《Spark on YARN集群模式作业运行全过程分析》《Spark on YARN客户端模式作业运行全过程分析》《Spark:Yarn-cluster和Yarn-client区别与联系》《Spark和Hadoop作业之间的区别》《Spark Standalone模式作业运行全过程分析》(未发布) 在前篇文章中我介绍了Spark on YARN集群模式(yarn-cluster)作业从提交到运行整个过程的情况(详情见《Spar w397090770 10年前 (2014-11-04) 19473℃ 5评论12喜欢
上海Spark Meetup第六次聚会将于2015年08月08日下午1:30 PM to 5:00 PM在上海市杨浦云计算创新基地发展有限公司举办,详细地址上海市杨浦区伟德路6号云海大厦13楼。本次聚会由Intel举办。大会主题主讲题目:Tachyon: 内存为中心可容错的分布式存储系统 摘要:在越来越多的大数据应用场景诸如机器学习,数据分析等, 内存成 w397090770 9年前 (2015-08-28) 4442℃ 0评论1喜欢
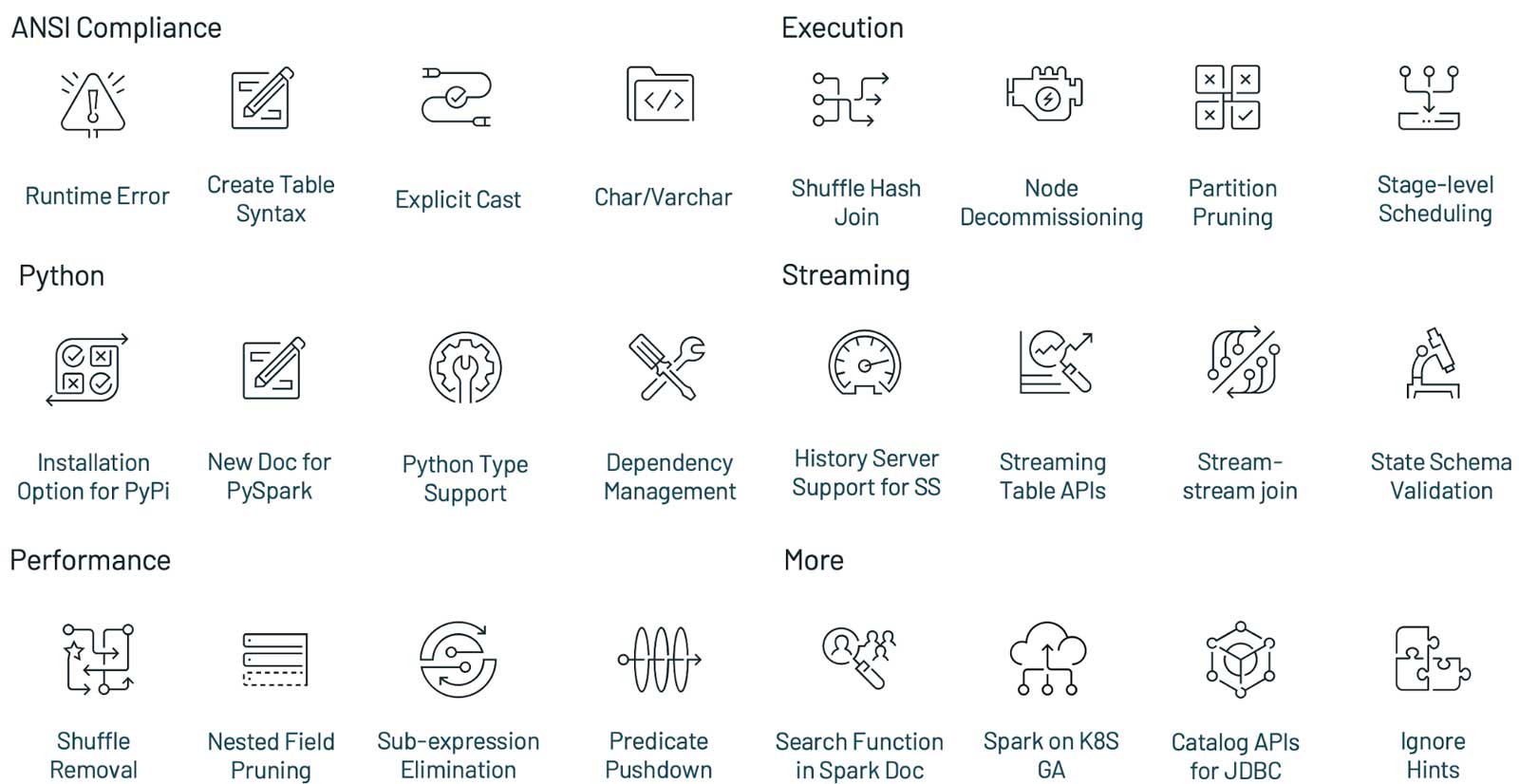
Apache Spark 3.1.1 版本于美国当地时间2021年3月2日正式发布,这个版本继续保持使得 Spark 更快,更容易和更智能的目标,Spark 3.1 的主要目标如下:提升了 Python 的可用性;加强了 ANSI SQL 兼容性;加强了查询优化;Shuffle hash join 性能提升;History Server 支持 structured streaming注意,由于技术上的原因,Apache Spark 没有发布 3.1.0 版 w397090770 3年前 (2021-03-03) 2167℃ 0评论9喜欢
Job execution logs and profiles are important when troubleshooting Hadoop errors, tuning job performance, and planning cluster capacity. In the past, the Job History Server has been the primary source for this information, providing logs of important events in MapReduce job execution and associated profiling metrics. With the advent of YARN, which enables execution frameworks beyond MapReduce, the responsibilities of the Job History Ser w397090770 7年前 (2017-06-02) 172℃ 0评论0喜欢
对RDD中的分区重新进行合并。函数原型[code lang="scala"]def coalesce(numPartitions: Int, shuffle: Boolean = false) (implicit ord: Ordering[T] = null): RDD[T][/code] 返回一个新的RDD,且该RDD的分区个数等于numPartitions个数。如果shuffle设置为true,则会进行shuffle。实例[code lang="scala"]/** * User: 过往记忆 * Date: 15-03-09 * Time: 上午0 w397090770 9年前 (2015-03-09) 14120℃ 1评论5喜欢
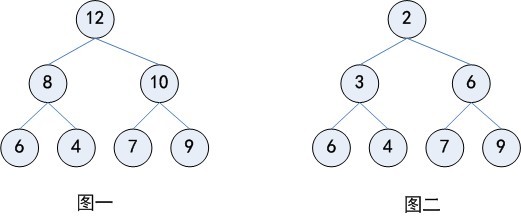
堆常用来实现优先队列,在这种队列中,待删除的元素为优先级最高(最低)的那个。在任何时候,任意优先元素都是可以插入到队列中去的,是计算机科学中一类特殊的数据结构的统称一、堆的定义最大(最小)堆是一棵每一个节点的键值都不小于(大于)其孩子(如果存在)的键值的树。大顶堆是一棵完全二叉树,同时也是 w397090770 11年前 (2013-04-01) 4770℃ 0评论3喜欢
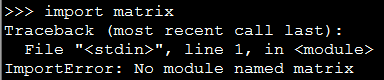
有时候我们会自己编写一些 Python 内置中没有的 module ,比如下面我自定义了一个名为 matrix 的 module ,然后直接在命令行中引入则会出现下面的错误:[code lang="python"][iteblog@www.iteblog.com ~]$ pythonPython 2.7.3 (default, Aug 4 2016, 21:49:57) [GCC 4.4.7 20120313 (Red Hat 4.4.7-16)] on linux2Type "help", "copyright", "credits" or "license& w397090770 7年前 (2017-06-25) 56631℃ 0评论14喜欢
NVIDIA (辉达) 于2020年5月15日宣布将与开源社群携手合作,将端到端的 GPU 加速技术导入 Apache Spark 3.0。全球超过五十万名资料科学家使用 Apache Spark 3.0 分析引擎处理大数据资料。透过预计于今年春末正式发表的 Spark 3.0,资料科学家与机器学习工程师将能首次把革命性的 GPU 加速技术应用于 ETL (撷取、转换、载入) 资料处理作业负载 w397090770 4年前 (2020-05-15) 682℃ 0评论2喜欢
本文所列的 Hive 函数均为 Hive 内置的,共计294个,Hive 版本为 3.1.0。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop!! a - Logical not,和not逻辑操作符含义一致[code lang="sql"]hive> select !(true);OKfalse[/code]!=a != b - Returns TRUE if a is not equal to b,和操作符含义一致[code lang="sql"]hive> se w397090770 6年前 (2018-07-22) 9408℃ 0评论8喜欢
Facebook 经常使用分析来进行数据驱动的决策。在过去的几年里,用户和产品都得到了增长,使得我们分析引擎中单个查询的数据量达到了数十TB。我们的一些批处理分析都是基于 Hive 平台(Apache Hive 是 Facebook 在2009年贡献给社区的)和 Corona( Facebook 内部的 MapReduce 实现)进行的。Facebook 还针对包括 Hive 在内的多个内部数据存储,继续 w397090770 4年前 (2019-12-19) 1706℃ 0评论10喜欢
本书于2017-07由Packt Publishing出版,作者Giuseppe Bonaccorso,全书580页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Acquaint yourself with important elements of Machine LearningUnderstand the feature selection and feature engineering processAssess performance and error trade-offs for Linear RegressionBuild a data model zz~~ 7年前 (2017-08-27) 4585℃ 0评论14喜欢
下面文档是今天早上翻译的,因为要上班,时间比较仓促,有些部分没有翻译,请见谅。2017年06月01日儿童节 Apache Flink 社区正式发布了 1.3.0 版本。此版本经历了四个月的开发,共解决了680个issues。Apache Flink 1.3.0 是 1.x.y 版本线上的第四个主要版本,其 API 和其他 1.x.y 使用 @Public 注释的API是兼容的。此外,Apache Flink 社区目前制 w397090770 7年前 (2017-06-01) 2565℃ 1评论10喜欢
Carlos E. Perez对深度学习的2017年十大预测,让我们不妨看一看。有兴趣的话,可以在一年之后回顾这篇文章,看看这十大预测有多少准确命中硬件将加速一倍摩尔定律(即2017年2倍) 如果你跟踪Nvidia和Intel的发展,这当然是显而易见的。Nvidia将在整个2017年占据主导地位,只因为他们拥有最丰富的深度学习生态系统。没有头 w397090770 7年前 (2016-12-13) 2145℃ 0评论3喜欢
本文来自7月26日在上海举行的 Flink Meetup 会议,分享来自于刘康,目前在大数据平台部从事模型生命周期相关平台开发,现在主要负责基于flink开发实时模型特征计算平台。熟悉分布式计算,在模型部署及运维方面有丰富实战经验和深入的理解,对模型的算法及训练有一定的了解。本文主要内容如下:在公司实时特征开发的现 zz~~ 6年前 (2018-08-14) 7366℃ 0评论3喜欢
rest 接口 现在我们已经有一个正常运行的节点(和集群),下一步就是要去理解怎样与其通信。幸运的是,Elasticsearch提供了非常全面和强大的REST API,利用这个REST API你可以同你的集群交互。下面是利用这个API,可以做的几件事情: 1、查你的集群、节点和索引的健康状态和各种统计信息 2、管理你的集群、节点、 zz~~ 8年前 (2016-08-31) 1414℃ 0评论2喜欢
为期三天的 Spark Summit 在美国时间 2018-06-04 ~ 06-06 于旧金山的 Moscone Center 举行,不少人已经注意到,今年的会议已经更名为 Spark+AI, 去年 12 月份时,Databricks 在他们的博客中就已经提到过,2018 年的会议将包括更多人工智能的内容,某种意义上也代表着 Spark 未来的发展方向。作为大数据领域的顶级会议,Spark Summit 2018 吸引了全球近 200 w397090770 6年前 (2018-06-18) 3561℃ 0评论14喜欢
Balloon.css文件允许用户给元素添加提示,而这些在Balloon.css中完全是由CSS来实现,不需要使用JavaScript。 button { display: inline-block; min-width: 160px; text-align: center; color: #fff; background: #ff3d2e; padding: 0.8rem 2rem; font-size: 1.2rem; margin-top: 1rem; border: none; border-radius: 5px; transition: background 0.1s linear;}.butt w397090770 8年前 (2016-03-15) 2432℃ 3评论10喜欢
在 《使用Python编写Hive UDF》 文章中,我简单的谈到了如何使用 Python 编写 Hive UDF 解决实际的问题。我们那个例子里面仅仅是一个很简单的示例,里面仅仅引入了 Python 的 sys 包,而这个包是 Python 内置的,所有我们不需要担心 Hadoop 集群中的 Python 没有这个包;但是问题来了,如果我们现在需要使用到 numpy 中的一些函数呢?假设我们 w397090770 6年前 (2018-01-25) 6398℃ 3评论22喜欢
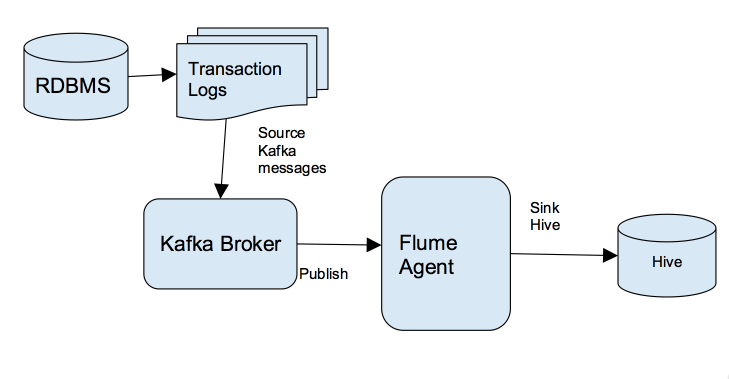
对那些想快速把数据传输到其Hadoop集群的企业来说,Kafka是一个非常合适的选择。关于什么是Kafka我就不介绍了,大家可以参见我之前的博客:《Apache kafka入门篇:工作原理简介》 本文是面向技术人员编写的。阅读本文你将了解到我是如何通过Kafka把关系数据库管理系统(RDBMS)中的数据实时写入到Hive中,这将使得实时分析的 w397090770 8年前 (2016-08-30) 11346℃ 6评论24喜欢
以较低的硬件成本扩展我们的数据基础设施,同时保持高性能和服务可靠性并非易事。 为了适应 Uber 数据存储和分析计算的指数级增长,数据基础设施团队通过结合硬件重新设计软件层,以扩展 Apache Hadoop® HDFS :HDFS Federation、Warm Storage、YARN 在 HDFS 数据节点上共存,以及 YARN 利用率的提高提高了系统的 CPU 和内存使用效率将多 w397090770 3年前 (2021-10-21) 376℃ 0评论1喜欢
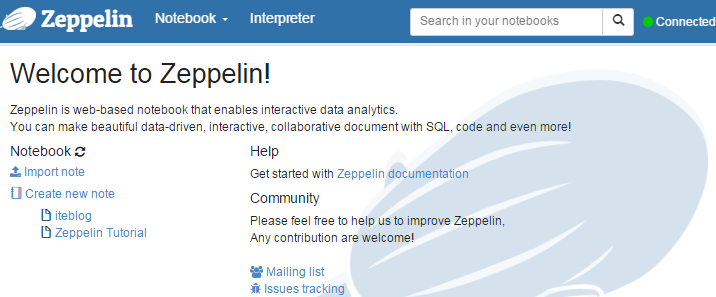
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析。原生就支持Spark、Scala、SQL 、shell, markdown等。而且它是完全开源的,目前还处于Apache孵化阶段。本文所有的操作都是基于Apache Zeppelin w397090770 8年前 (2016-02-02) 20494℃ 9评论20喜欢














![[电子书]Machine Learning Algorithms PDF下载](https://www.iteblog.com/pic/books/Machine_Learning_Algorithms_iteblog.png)

![Spark Summit North America 201806 全部PPT下载[共147个]](https://www.iteblog.com/pic/spark/spark-summit-north-america-2018-06_iteblog.png)