哎哟~404了~休息一下,下面的文章你可能很感兴趣:
Spark和Flume-ng整合,可以参见本博客:《Spark和Flume-ng整合》《使用Spark读取HBase中的数据》如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 大家可能都知道很熟悉Spark的两种常见的数据读取方式(存放到RDD中):(1)、调用parallelize函数直接从集合中获取数据,并存入RDD中;Java版本如 w397090770 10年前 (2014-06-29) 74819℃ 47评论58喜欢
iceberg 详细设计Apache iceberg 是Netflix开源的全新的存储格式,我们已经有了parquet、orc、arvo等非常优秀的存储格式以后,Netfix为什么还要设计出iceberg呢?和parquet、orc等文件格式不同, iceberg在业界被称之为Table Foramt,parquet、orc、avro等文件等格式帮助我们高效的修改、读取单个文件;同样Table Foramt帮助我们高效的修改和读取一类文件 w397090770 3年前 (2021-04-15) 2135℃ 0评论6喜欢
本文主要讲解 Kafka 是什么、Kafka 的架构包括工作流程和存储机制,以及生产者和消费者,最终大家会掌握 Kafka 中最重要的概念,分别是 broker、producer、consumer、consumer group、topic、partition、replica、leader、follower,这是学会和理解 Kafka 的基础和必备内容。1. 定义Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主 w397090770 4年前 (2020-03-14) 1574℃ 0评论10喜欢
一、定义位图法就是bitmap的缩写。所谓bitmap,就是用每一位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况。通常是用来判断某个数据存不存在的。在STL中有一个bitset容器,其实就是位图法,引用bitset介绍:A bitset is a special container class that is designed to store bits (elements with only two possible values: 0 or 1,true or false, . w397090770 11年前 (2013-04-03) 8592℃ 0评论8喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-13) 15720℃ 2评论17喜欢
使用过 Chrome 浏览器的用户都应该安装过插件,但是我们从 Google 的应用商店下载插件是无法直接获取到下载地址的。不过我们总是有些需求需要获取到这些插件的地址,比如朋友想安装某个插件,但是因为某些原因无法访问 Google 应用商店,而我可以访问,这时候我们就想如果能获取到插件的下载地址,直接下载好然后发送给朋友 w397090770 7年前 (2017-08-23) 4259℃ 0评论10喜欢
下面的操作会影响到Spark输出RDD分区(partitioner)的: cogroup, groupWith, join, leftOuterJoin, rightOuterJoin, groupByKey, reduceByKey, combineByKey, partitionBy, sort, mapValues (如果父RDD存在partitioner), flatMapValues(如果父RDD存在partitioner), 和 filter (如果父RDD存在partitioner)。其他的transform操作不会影响到输出RDD的partitioner,一般来说是None,也就是没 w397090770 9年前 (2014-12-29) 16494℃ 0评论5喜欢
关于 HBase 的 MOB 具体使用可以参见 《HBase MOB(Medium Object)使用入门指南》介绍Apache HBase 中等对象存储(Medium Object Storage, 下面简称 MOB)的特性是由 HBASE-11339 引入的。该功能可以提高 HBase 对中等尺寸文件的低延迟读写访问(理想情况下,文件大小为 100K 到 10MB),这个功能使得 HBase 非常适合存储文档,图片和其他中等尺寸的对 w397090770 6年前 (2018-08-27) 2272℃ 0评论2喜欢
前言当开发人员通过我们提供的 API 使用公开的 Twitter 数据时,他们需要可靠性、高效的性能以及稳定性。因此,在前一段时间,我们为 Account Activity API 启动了 Account Activity Replay API ,让开发人员将稳定性融入到他们的系统中。Account Activity Replay API 是一个数据恢复工具,它允许开发人员检索5天前的事件。并且提供了恢复由于各种 w397090770 3年前 (2020-12-17) 535℃ 0评论0喜欢
Spark SQL小文件是指文件大小显著小于hdfs block块大小的的文件。过于繁多的小文件会给HDFS带来很严重的性能瓶颈,对任务的稳定和集群的维护会带来极大的挑战。一般来说,通过Hive调度的MR任务都可以简单设置如下几个小文件合并的参数来解决任务产生的小文件问题:[code lang="sql"]set hive.merge.mapfiles=true;set hive.merge.mapredfiles=true w397090770 4年前 (2020-07-03) 2258℃ 0评论3喜欢
Spark Summit 2016 Europe会议于2016年10月25日至10月27日在布鲁塞尔进行。本次会议有上百位Speaker,来自业界顶级的公司。官方日程:https://spark-summit.org/eu-2016/schedule/。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料 w397090770 8年前 (2016-11-06) 3031℃ 0评论1喜欢
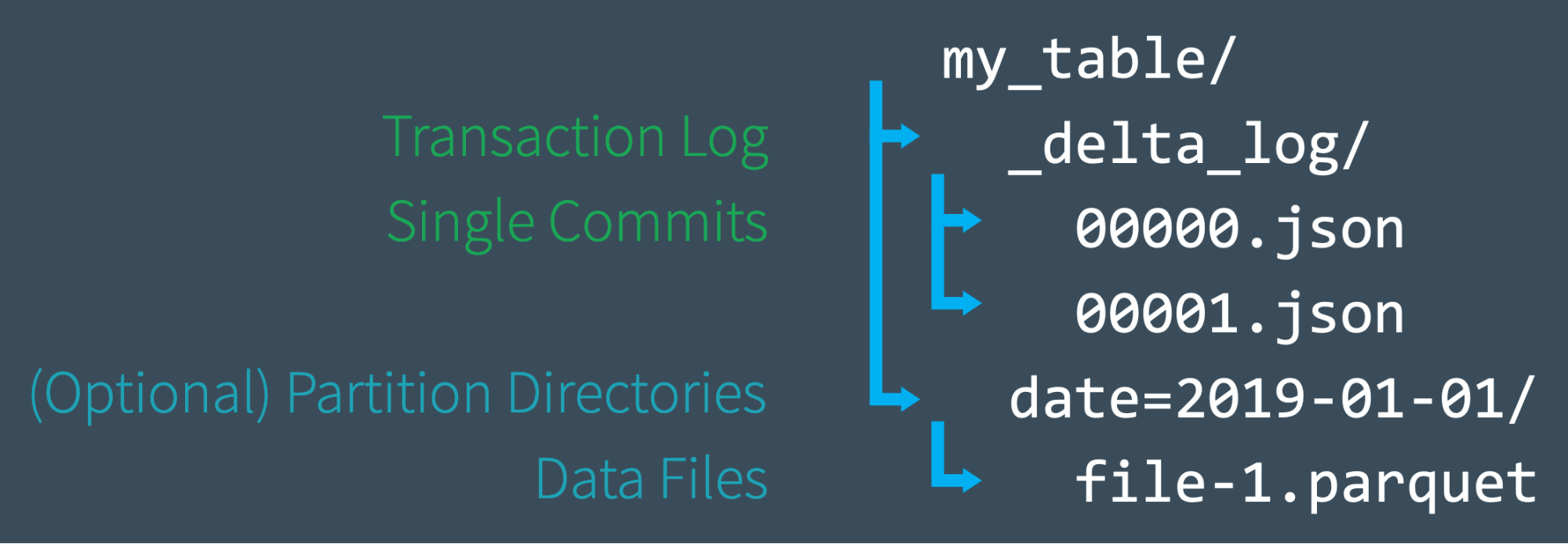
事务日志是理解 Delta Lake 的关键,因为它是贯穿许多最重要功能的通用模块,包括 ACID 事务、可扩展的元数据处理、时间旅行(time travel)等。本文我们将探讨事务日志(Transaction Log)是什么,它在文件级别是如何工作的,以及它如何为多个并发读取和写入问题提供优雅的解决方案。事务日志(Transaction Log)是什么Delta Lake 事务日 w397090770 5年前 (2019-08-22) 1737℃ 0评论6喜欢
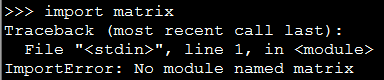
有时候我们会自己编写一些 Python 内置中没有的 module ,比如下面我自定义了一个名为 matrix 的 module ,然后直接在命令行中引入则会出现下面的错误:[code lang="python"][iteblog@www.iteblog.com ~]$ pythonPython 2.7.3 (default, Aug 4 2016, 21:49:57) [GCC 4.4.7 20120313 (Red Hat 4.4.7-16)] on linux2Type "help", "copyright", "credits" or "license& w397090770 7年前 (2017-06-25) 56631℃ 0评论14喜欢
一、前提条件 1、安装好Java JDK 1.6或以上版本; 2、安装好Apache Maven。 如果上述条件准备好之后,下面开始用Maven编译Mahout源码二、git一份Mahout源码 用下面的命令从 Mahout GitHub 仓库Git(如果你电脑没有安装Git软件,可以参照这个安装《Git安装》)一份代码到本地[code lang="JAVA"]git clone git@github.com:apache/mahout.git w397090770 10年前 (2014-09-16) 6151℃ 0评论3喜欢
Suffusion 是一款功能十分强大的免费WordPress主题,可以对样式模板、整体框架、内容调用进行自定义设置。本文主要来分享一下如何给文章添加统计次数。 安装WP-PostViews插件,这个是用来统计文章浏览次数的。 依次选择 外观-->编辑-->post-header.php 在里面找到[code lang="CPP"]<span class="comments">[/code] 可以 w397090770 11年前 (2013-04-20) 3465℃ 0评论4喜欢
Monarch 是 Pinterest 的批处理平台,由30多个 Hadoop YARN 集群组成,其中17k+节点完全建立在 AWS EC2 之上。2021年初,Monarch 还在使用五年前的 Hadoop 2.7.1。由于同步社区分支(特性和bug修复)的复杂性不断增加,我们决定是时候进行版本升级了。我们最终选择了Hadoop 2.10.0,这是当时 Hadoop 2 的最新版本。本文分享 Pinterest 将 Monarch 升级到 Ha w397090770 2年前 (2022-08-12) 523℃ 0评论0喜欢
Apache Hudi 对个人和组织何时有用如果你希望将数据快速提取到HDFS或云存储中,Hudi可以提供帮助。另外,如果你的ETL /hive/spark作业很慢或占用大量资源,那么Hudi可以通过提供一种增量式读取和写入数据的方法来提供帮助。作为一个组织,Hudi可以帮助你构建高效的数据湖,解决一些最复杂的底层存储管理问题,同时将数据更快 w397090770 4年前 (2019-12-23) 1805℃ 0评论2喜欢
Hadoop Streaming 是 Hadoop 提供的一个 MapReduce 编程工具,它允许用户使用任何可执行文件、脚本语言或其他编程语言来实现 Mapper 和 Reducer,从而充分利用 Hadoop 并行计算框架的优势和能力,来处理大数据。而我们在官方文档或者是Hadoop权威指南看到的Hadoop Streaming例子都是使用 Ruby 或者 Python 编写的,官方说可以使用任何可执行文件 w397090770 7年前 (2017-03-14) 2629℃ 0评论2喜欢
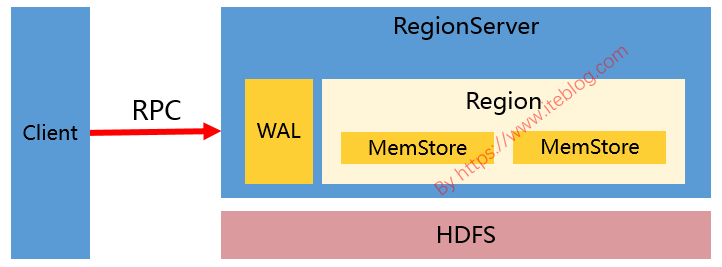
接触过 HBase 的同学应该对 HBase 写数据的过程比较熟悉(不熟悉也没关系)。HBase 写数据(比如 put、delete)的时候,都是写 WAL(假设 WAL 没有被关闭) ,然后将数据写到一个称为 MemStore 的内存结构里面的,如下图:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop但是,MemStore 毕竟是内存里 w397090770 5年前 (2019-01-13) 7045℃ 4评论32喜欢
在本博客的《Spark将计算结果写入到Mysql中》文章介绍了如果将Spark计算后的RDD最终 写入到Mysql等关系型数据库中,但是这些写操作都是自己实现的,弄起来有点麻烦。不过值得高兴的是,前几天发布的Spark 1.3.0已经内置了读写关系型数据库的方法,我们可以直接在代码里面调用。 Spark 1.3.0中对数据库写操作是通过DataFrame类 w397090770 9年前 (2015-03-17) 13493℃ 6评论16喜欢
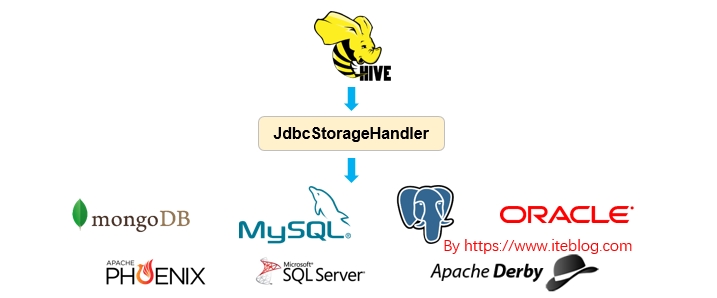
Apache Hive 从 HIVE-1555 开始引入了 JdbcStorageHandler ,这个使得 Hive 能够读取 JDBC 数据源,关于 Apache Hive 引入 JdbcStorageHandler 的背景可以参见 《Apache Hive 联邦查询(Query Federation)》。本文主要简单介绍 JdbcStorageHandler 的使用。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop语法JdbcStorageHandler 使 w397090770 5年前 (2019-04-01) 3242℃ 0评论7喜欢
先说明一下,这里说的Hive on Spark是Hive跑在Spark上,用的是Spark执行引擎,而不是MapReduce,和Hive on Tez的道理一样。 从Hive 1.1版本开始,Hive on Spark已经成为Hive代码的一部分了,并且在spark分支上面,可以看这里https://github.com/apache/hive/tree/spark,并会定期的移到master分支上面去。关于Hive on Spark的讨论和进度,可以看这里https:// w397090770 9年前 (2015-08-31) 41663℃ 30评论43喜欢
Resources提供提供操作classpath路径下所有资源的方法。除非另有说明,否则类中所有方法的参数都不能为null。虽然有些方法的参数是URL类型的,但是这些方法实现通常不是以HTTP完成的;同时这些资源也非classpath路径下的。 下面两个函数都是根据资源的名称得到其绝对路径,从函数里面可以看出,Resources类中的getResource函数 w397090770 11年前 (2013-09-25) 6414℃ 0评论4喜欢
金山云-企业云团队(赵侃、李金辉)在交互查询场景下对Presto与Alluxio相结合进行了一系列测试,并总结了一些Presto搭配Alluxio使用的建议。本次测试未使用对象存储,计算引擎与存储间的网络延时也比较低。如果存储IO耗时和网络耗时较大时,Alluxio加速收益应会更明显。测试目的验证影响Alluxio加速收益的各种因素记录Alluxio w397090770 2年前 (2022-03-29) 674℃ 0评论1喜欢
Elasticsearch 5.0.0在2016年10月26日发布,该版本基于Lucene 6.2.0,这是最新的稳定版本,并且已经在Elastic Cloud上完成了部署。Elasticsearch 5.0.0是目前最快、最安全、最具弹性、最易用的版本,此版本带来了一系列的新功能和性能优化。ElasticSearch 5.0.0 release Note点击下载ElasticSearch 5.0.0阅读最新文档如果想及时了解Spark、Hadoop或者Hbase w397090770 8年前 (2016-11-02) 4932℃ 0评论10喜欢
2014年7月11日,Spark 1.0.1已经发布了,原文如下:We are happy to announce the availability of Spark 1.0.1! This release includes contributions from 70 developers. Spark 1.0.0 includes fixes across several areas of Spark, including the core API, PySpark, and MLlib. It also includes new features in Spark’s (alpha) SQL library, including support for JSON data and performance and stability fixes.Visit the relea w397090770 10年前 (2014-07-13) 6851℃ 0评论4喜欢
Apache Flume 1.7.0是自Flume成为Apache顶级项目的第十个版本。Apache Flume 1.7.0可以在生产环境下使用。Flume 1.7.0 User Guide下载Flume 1.7.0Flume 1.7.0 Developer GuideChanges[code lang="bash"]** New Feature[FLUME-2498] - Implement Taildir Source** Improvement[FLUME-1899] - Make SpoolDir work with Sub-Directories[FLUME-2526] - Build flume by jdk 7 in default[FLUME-2628] - Add an optiona w397090770 8年前 (2016-10-19) 3604℃ 0评论9喜欢
ZooKeeper 支持某些特定的四字命令(The Four Letter Words)与其进行交互。它们大多是查询命令,用来获取 ZooKeeper 服务的当前状态及相关信息。用户在客户端可以通过 telnet 或 nc 向 ZooKeeper 提交相应的命令。 ZooKeeper 常用四字命令主要如下: ZooKeeper四字命令功能描述conf3.3.0版本引入的。打印出服务相关配置的详细信息。cons3.3.0 w397090770 8年前 (2016-05-18) 4066℃ 0评论5喜欢
Learning Apache Kafka, 2nd Edition于2015年02月出版,全书共112页。 w397090770 9年前 (2015-08-25) 5477℃ 2评论10喜欢
活动时间 1月24日下午14:00活动地点 地址:海淀区中关村软件园二期,西北旺东路10号院东区,亚信大厦 一层会议室 地图:http://j.map.baidu.com/L_1hq 为了保证大家乘车方便,特提供活动大巴时间:13:20-13:40位置:http://j.map.baidu.com/SJOLy分享内容: 邵赛赛 Intel Spark Streaming driver high availability w397090770 9年前 (2015-01-22) 15580℃ 0评论2喜欢








![Spark Summit 2016 Europe全部PPT下载[共75个]](https://www.iteblog.com/pic/iteblog.png)