哎哟~404了~休息一下,下面的文章你可能很感兴趣:
Spark Summit 2017 Europe 于2017-10-24 至 26在柏林进行,本次会议议题超过了70多个,会议的全部日程请参见:https://spark-summit.org/eu-2017/schedule/。本次议题主要包括:开发、研究、机器学习、流计算等领域。从这次会议可以看出,当前 Spark 发展两大方向:深度学习(Deep Learning)提升流系统的性能( Streaming Performance)如果想及时了解Spar w397090770 7年前 (2017-11-02) 3513℃ 0评论13喜欢
本课程是Scala语言的入门课程,面向没有或仅有少量编程语言基础的同学,当然,具有一定的Java或C、C++语言基础将有助于本课程的学习。在本课程内,将更注重scala的各种语言规则与简单直接的应用,而不在于其是如何具体实现,通过学习本课程能具备初步的Scala语言实际编程能力。 此视频保证可以全部浏览,百度网盘 w397090770 9年前 (2015-03-21) 21881℃ 6评论46喜欢
Wordpress的功能很强大,可以根据自己的需求来修改自己的网站。在Wordpress 3.5.1的中提供了默认的主题Twenty Twelve,很不错,但是首页显示的是全文信息,这不仅使得页面太长,也使得加载速度变的很慢,只有在搜索的时候才会显示摘要,那么怎么去让首页显示文章的摘要呢?到wordpress后台,依次选择 外观-->编辑-->选择右边的 w397090770 11年前 (2013-03-31) 27071℃ 9评论23喜欢
2017年已然来临,大数据技术仍然保持着飞速发展。无论是物联网、云计算领域乃至企业技术都开始将其引入自身并作为新的变革方向。众多企业已经在积极接纳大数据技术,并作为提升自身市场竞争力的核心因素。在今天的文章中,我们将基于甲骨文给出的预测结论,总结2017年十项大数据变化趋势。如果想及时了解Spark、H w397090770 7年前 (2017-02-17) 1026℃ 0评论3喜欢
在 Spark 或 Hive 中,我们可以使用 LATERAL VIEW + EXPLODE 或 POSEXPLODE 将 array 或者 map 里面的数据由行转成列,这个操作在数据分析里面很常见。比如我们有以下表:[code lang="sql"]CREATE TABLE `default`.`iteblog_explode` ( `id` INT, `items` ARRAY<STRING>)[/code]表里面的数据如下:[code lang="sql"]spark-sql> SELECT * FROM iteblog_explode;1 ["iteblog.co w397090770 2年前 (2022-08-08) 1614℃ 0评论6喜欢
如果你对Hadoop有基本的了解,并希望将您的知识用于企业的大数据解决方案,那你就来阅读本书吧。本书提供了六个使用Hadoop生态系统解决实际问题的例子,使得您的Hadoop知识提升到一个新的水平。本书作者:Anurag Shrivastava,由Packt出版社于2016年9月出版,全书共316页。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关 zz~~ 7年前 (2016-12-20) 3220℃ 1评论6喜欢
多年以来,社区一直在努力改进 Spark SQL 的查询优化器和规划器,以生成高质量的查询执行计划。最大的改进之一是基于成本的优化(CBO,cost-based optimization)框架,该框架收集并利用各种数据统计信息(如行数,不同值的数量,NULL 值,最大/最小值等)来帮助 Spark 选择更好的计划。这些基于成本的优化技术很好的例子就是选择正确 w397090770 4年前 (2020-05-30) 1590℃ 0评论4喜欢
本程序实际上是构建了一颗二叉排序树,程序最后输出构建数的中序遍历。代码实现:[code lang="CPP"]#include <stdio.h>#include <stdlib.h>// Author: 过往记忆// Email: wyphao.2007@163.com// Blog: typedef int DataType; typedef struct BTree{ DataType data; struct BTree *Tleft; struct BTree *Tright; }*BTree;BTree CreateTree(); BTree insert(BTree root, DataTy w397090770 11年前 (2013-04-04) 3037℃ 0评论1喜欢
建议用Spark 1.3.0提供的写关系型数据库的方法,参见《Spark RDD写入RMDB(Mysql)方法二》。 在《Spark与Mysql(JdbcRDD)整合开发》文章中我们介绍了如何通过Spark读取Mysql中的数据,当时写那篇文章的时候,Spark还未提供通过Java来使用JdbcRDD的API,不过目前的Spark提供了Java使用JdbcRDD的API。 今天主要来谈谈如果将Spark计算的结果 w397090770 9年前 (2015-03-10) 36811℃ 5评论33喜欢
点击试试使用Github登录我博客。 随着使用Github的人越来越多,为自己的网站添加Github登录功能也越来越有必要了。Github开放了登录API,第三方网站可以通过调用Github的OAuth相关API读取到登录用户的基本信息,从而使得用户可以通过Github登录到我们的网站。今天来介绍一下如何使用Github的OAuth相关API登录到Wordpress。 w397090770 9年前 (2015-04-12) 11804℃ 9评论12喜欢
ElasticSearch是一个基于Lucene构建的开源的分布式搜索和分析引擎,具备高可靠性和扩展性。它允许你快速准实时存储,搜索和分析海量数据。它通常作为底层引擎/计算来驱动企业级复杂搜索特性和需求。 下面列举一些使用ElasticSearch的应用场景: 1、运行一个在线的网店,你允许客户能够去搜索你销售的商品。在这 w397090770 8年前 (2016-08-09) 2173℃ 0评论3喜欢
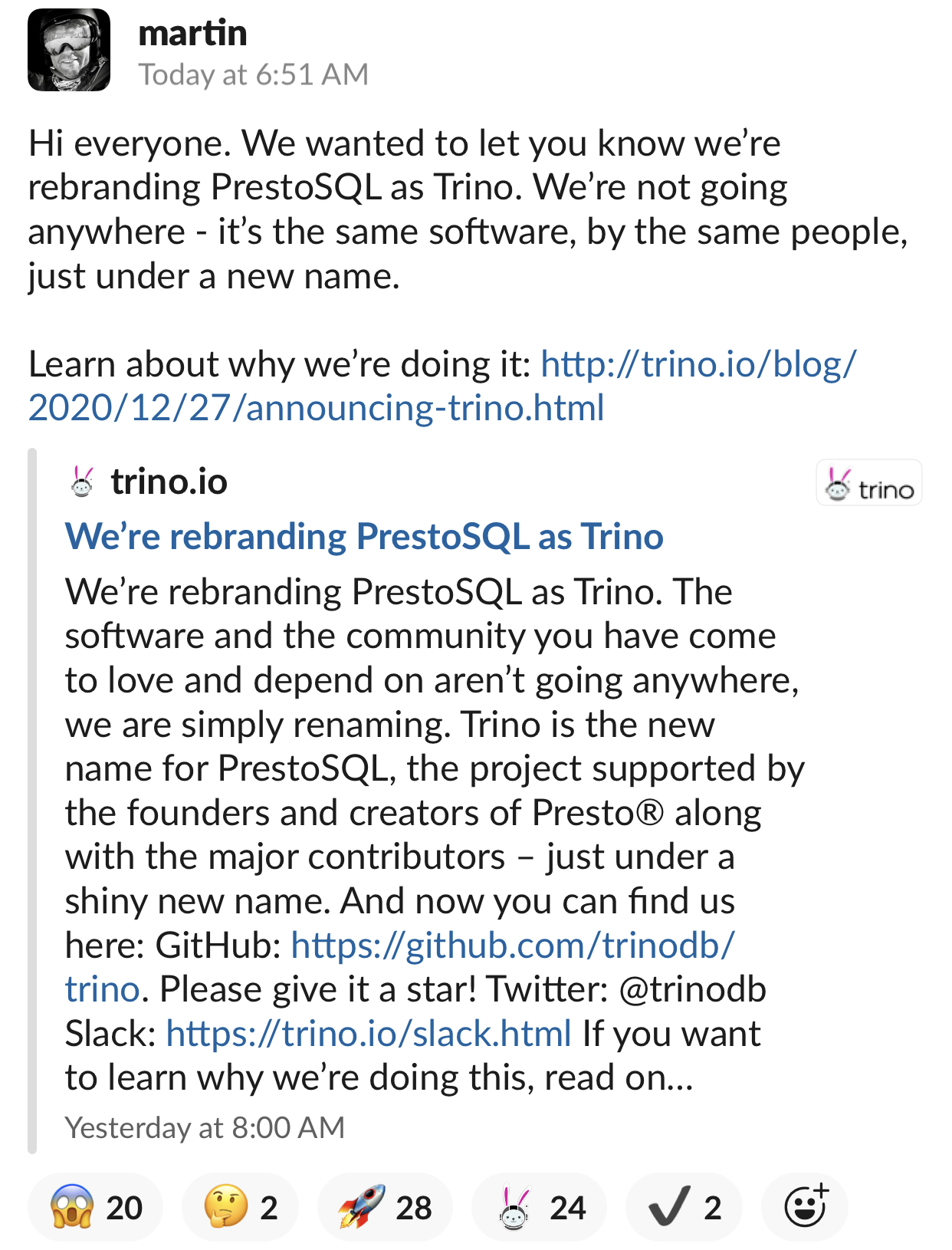
2020年12月27日,Martin Traverso、 Dain Sundstrom 以及 David Phillips 大佬们宣布将 PrestoSQL 项目的名字更名为 Trino。新的项目地址为 https://trino.io/。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop正如上图的描述,这个仅仅是更改名字,之前的社区和软件都还在那的,这个项目还是由 Presto 的创始人和创 w397090770 3年前 (2020-12-28) 1872℃ 0评论1喜欢
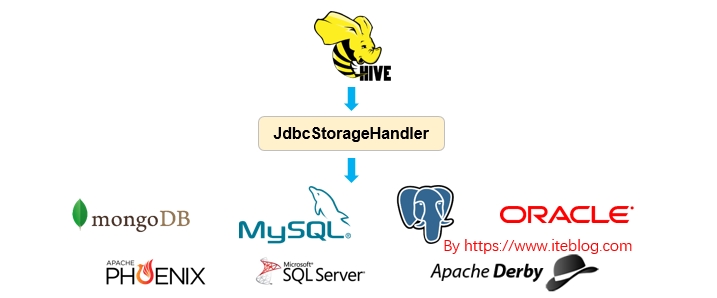
如今,很多公司可能会在内部使用多种数据存储和处理系统。这些不同的系统解决了对应的使用案例。除了传统的 RDBMS (比如 Oracle DB,Teradata或PostgreSQL) 之外,我们还会使用 Apache Kafka 来获取流和事件数据。使用 Apache Druid 处理实时系列数据(real-time series data),使用 Apache Phoenix 进行快速索引查找。 此外,我们还可能使用云存储 w397090770 5年前 (2019-03-16) 4998℃ 1评论7喜欢
数据分析中将两个数据集进行 Join 操作是很常见的场景。在 Spark 的物理计划(physical plan)阶段,Spark 的 JoinSelection 类会根据 Join hints 策略、Join 表的大小、 Join 是等值 Join(equi-join) 还是不等值(non-equi-joins)以及参与 Join 的 key 是否可以排序等条件来选择最终的 Join 策略(join strategies),最后 Spark 会利用选择好的 Join 策略执行最 w397090770 4年前 (2020-09-13) 4687℃ 0评论13喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-01-04) 181921℃ 9评论307喜欢
这本书是市面上第一本系统介绍Apache Flink的图书,书中介绍了为什么选择Apache Flink、流系统架构设计、Flink能做些什么、Flink中是怎么处理时间的、Flink的状态计算等。全书共6章,一共110页。由O'Reilly出版社于2016年10月出版。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节[c w397090770 8年前 (2016-11-03) 7815℃ 0评论4喜欢
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。详情参见《CarbonData:华为开发并支持Hadoop的列式文件格式》,本文是单机模式下使用CarbonData的,如果你需要集群模 w397090770 8年前 (2016-07-01) 8319℃ 3评论6喜欢
从本质上说,fold函数将一种格式的输入数据转化成另外一种格式返回。fold, foldLeft和foldRight这三个函数除了有一点点不同外,做的事情差不多。我将在下文解释它们的共同点并解释它们的不同点。 我将从一个简单的例子开始,用fold计算一系列整型的和。[code lang="scala"]val numbers = List(5, 4, 8, 6, 2)numbers.fold(0) { (z, i) => w397090770 9年前 (2014-12-17) 36050℃ 0评论42喜欢
在Spark 1.x版本,我们收到了很多询问SparkContext, SQLContext和HiveContext之间关系的问题。当人们想使用DataFrame API的时候把HiveContext当做切入点的确有点奇怪。在Spark 2.0,引入了SparkSession,作为一个新的切入点并且包含了SQLContext和HiveContext的功能。为了向后兼容,SQLContext和HiveContext被保存下来。SparkSession拥有许多特性,下面将展示SparkS w397090770 8年前 (2016-05-26) 13987℃ 0评论13喜欢
rest 接口 现在我们已经有一个正常运行的节点(和集群),下一步就是要去理解怎样与其通信。幸运的是,Elasticsearch提供了非常全面和强大的REST API,利用这个REST API你可以同你的集群交互。下面是利用这个API,可以做的几件事情: 1、查你的集群、节点和索引的健康状态和各种统计信息 2、管理你的集群、节点、 zz~~ 8年前 (2016-08-31) 1414℃ 0评论2喜欢
本文将介绍使用Spark batch作业处理存储于Hive中Twitter数据的一些实用技巧。首先我们需要引入一些依赖包,参考如下:[code lang="scala"]name := "Sentiment"version := "1.0"scalaVersion := "2.10.6"assemblyJarName in assembly := "sentiment.jar"libraryDependencies += "org.apache.spark" % "spark-core_2.10" % "1.6.0&qu zz~~ 8年前 (2016-08-31) 3318℃ 0评论5喜欢
Few months ago, I introduced a simple algorithm that allow users to implement their own short URL into their system. Today, I have some spare time so I decided to write the short URL algorithm's implementation in PHP.At first, we define a function called shorturl() that receives a URL as the input and returns an array that contains 4 hashed values (each 6 characters).[php]function shorturl($input) { ... // return array of w397090770 11年前 (2013-04-14) 3826℃ 0评论1喜欢
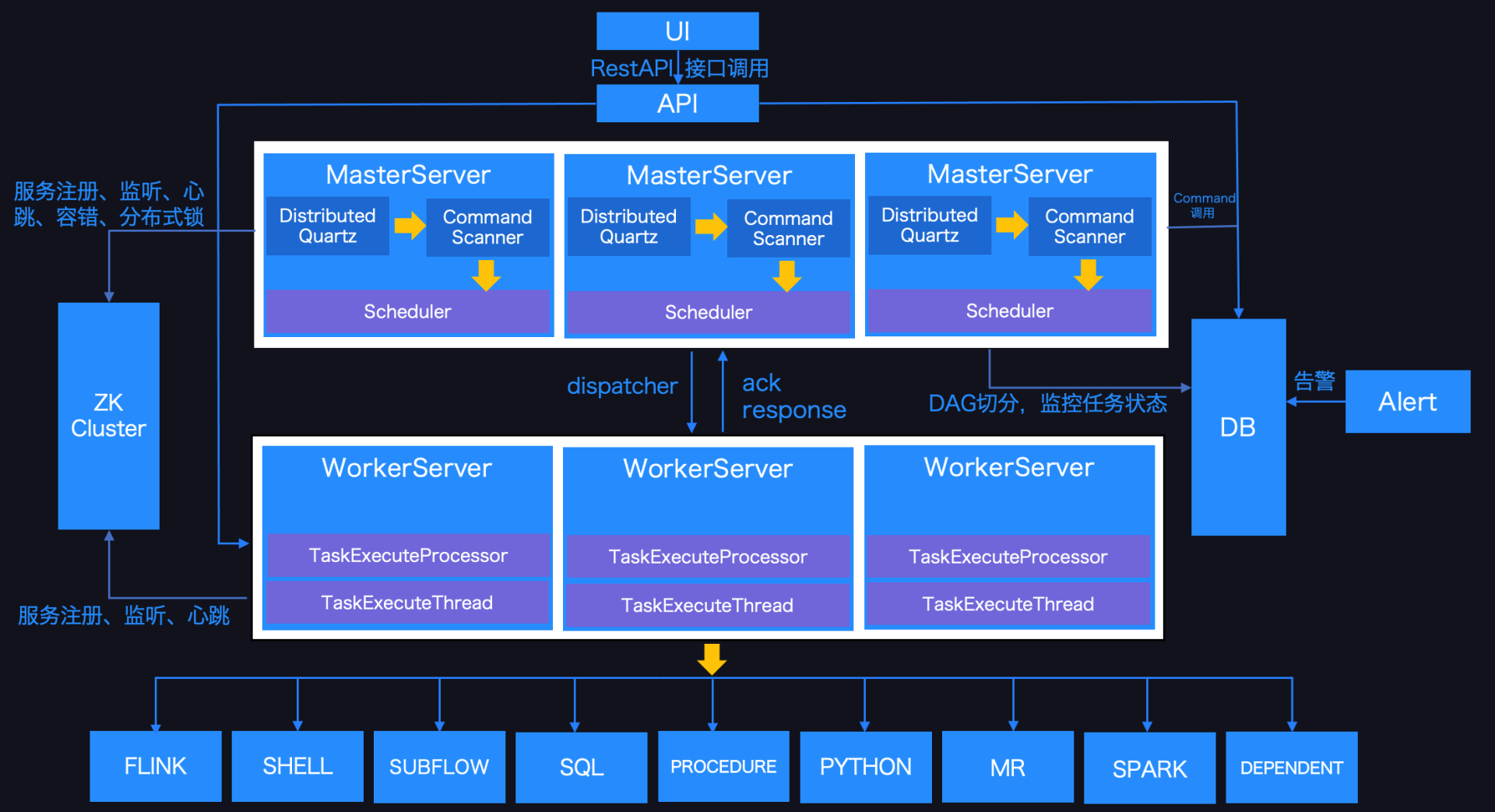
全球最大的开源软件基金会 Apache 软件基金会(以下简称 Apache)于北京时间 2021年4月9日在官方渠道宣布Apache DolphinScheduler 毕业成为Apache顶级项目。这是首个由国人主导并贡献到 Apache 的大数据工作流调度领域的顶级项目。DolphinScheduler™ 已经是联通、IDG、IBM、京东物流、联想、新东方、诺基亚、360、顺丰和腾讯等 400+ 公司在使用 w397090770 3年前 (2021-04-09) 1725℃ 0评论3喜欢
XML(可扩展标记语言,英语:eXtensible Markup Language,简称: XML)是一种标记语言,也是行业标准数据交换交换格式,它很适合在系统之间进行数据存储和交换(话说Hadoop、Hive等的配置文件就是XML格式的)。本文将介绍如何使用MapReduce来读取XML文件。但是Hadoop内部是无法直接解析XML文件;而且XML格式中没有同步标记,所以并行地处 w397090770 8年前 (2016-03-07) 5718℃ 1评论7喜欢
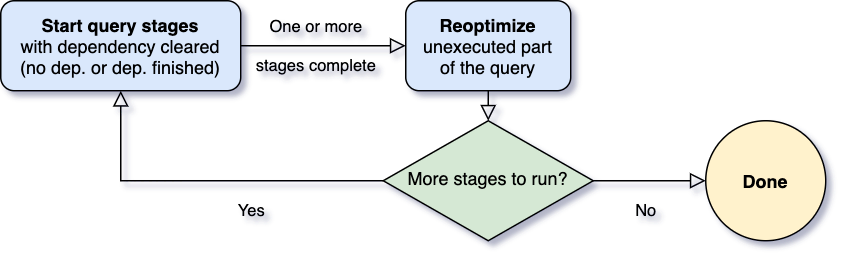
现象大家在使用 Apache Spark 2.x 的时候可能会遇到这种现象:虽然我们的 Spark Jobs 已经全部完成了,但是我们的程序却还在执行。比如我们使用 Spark SQL 去执行一些 SQL,这个 SQL 在最后生成了大量的文件。然后我们可以看到,这个 SQL 所有的 Spark Jobs 其实已经运行完成了,但是这个查询语句还在运行。通过日志,我们可以看到 driver w397090770 5年前 (2019-01-14) 4136℃ 0评论18喜欢
直到目前,我们看到的所有Mapreduce作业都输出一组文件。但是,在一些场合下,经常要求我们将输出多组文件或者把一个数据集分为多个数据集更为方便;比如将一个log里面属于不同业务线的日志分开来输出,并交给相关的业务线。 用过旧API的人应该知道,旧API中有 org.apache.hadoop.mapred.lib.MultipleOutputFormat和org.apache.hadoop.mapr w397090770 11年前 (2013-11-26) 14993℃ 1评论10喜欢
问题的定义装箱问题(Bin packing problem),又称集装优化,是一个利用运筹学去解决实际生活的的经典问题。在维基百科的定义如下:In the bin packing problem, items of different volumes must be packed into a finite number of bins or containers each of a fixed given volume in a way that minimizes the number of bins used. In computational complexity theory, it is a combinatorial NP-hard w397090770 4年前 (2020-10-27) 6534℃ 0评论2喜欢
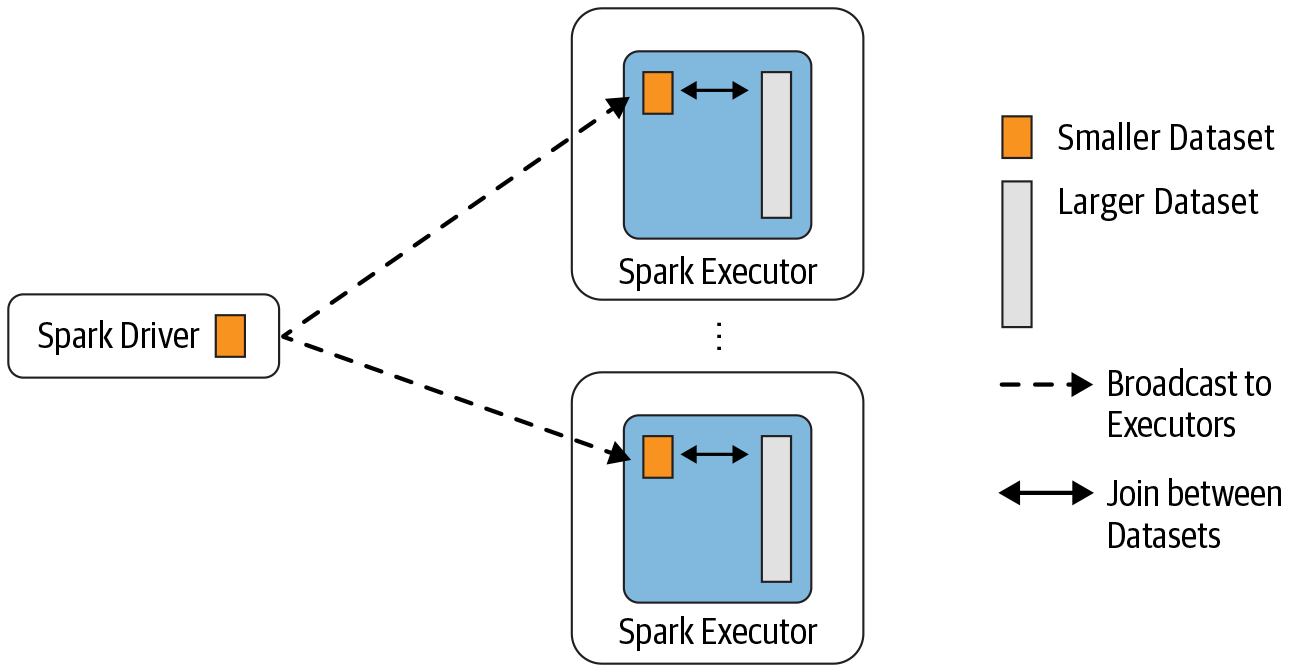
本资料来自 Workday 的软件开发工程师 Jianneng Li 在 Spark Summit North America 2020 的 《On Improving Broadcast Joins in Spark SQL》议题的分享。背景相信使用 Apache Spark 进行数据分析的同学对 Spark 中的 Broadcast Join 比较熟悉,其在 Join 之前会把一端比较小的表广播到参与 Join 的 worker 端,具体如下:如果想及时了解Spark、Hadoop或者HBase相关的文 w397090770 4年前 (2020-07-05) 1845℃ 0评论4喜欢
Delta Lake 写数据是其最基本的功能,而且其使用和现有的 Spark 写 Parquet 文件基本一致,在介绍 Delta Lake 实现原理之前先来看看如何使用它,具体使用如下:[code lang="scala"]df.write.format("delta").save("/data/iteblog/delta/test/")//数据按照 dt 分区df.write.format("delta").partitionBy("dt").save("/data/iteblog/delta/test/" w397090770 5年前 (2019-09-10) 2107℃ 0评论2喜欢
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据。我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等。但是这些方式不是慢就是在导入的过程的占用Region资源导致效率低下,所以很不适合一次性导入大量数据。本文将针对这个问题介绍如何通过Hbase的BulkLoad方法来快速将海量数据导入到Hbas w397090770 7年前 (2016-11-28) 17615℃ 2评论52喜欢

![Spark Summit 2017 Europe全部PPT及视频下载[共69个]](https://www.iteblog.com/pic/spark/spark-summit-2017-europe-iteblog.png)
![练数成金—Scala语言入门视频百度网盘下载[全五课]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/3.jpg)


![[电子书]Hadoop Blueprints pdf下载](https://www.iteblog.com/pic/Hadoop_Blueprints-iteblog.jpg)



![Hadoop入门视频分享[共44集]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/7.jpg)
![[电子书]Introduction to Apache Flink PDF下载](https://www.iteblog.com/pic/books/Introduction_to_Apache_Flink_iteblog.jpg)



![通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]](https://www.iteblog.com/pic/hbase_Bulkload_iteblog.png)