哎哟~404了~休息一下,下面的文章你可能很感兴趣:
Delta Lake 是数砖公司在2017年10月推出来的一个项目,并于2019年4月24日在美国旧金山召开的 Spark+AI Summit 2019 会上开源的一个存储层。它是 Databricks Runtime 重要组成部分。为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构 w397090770 4年前 (2019-12-24) 4364℃ 0评论8喜欢
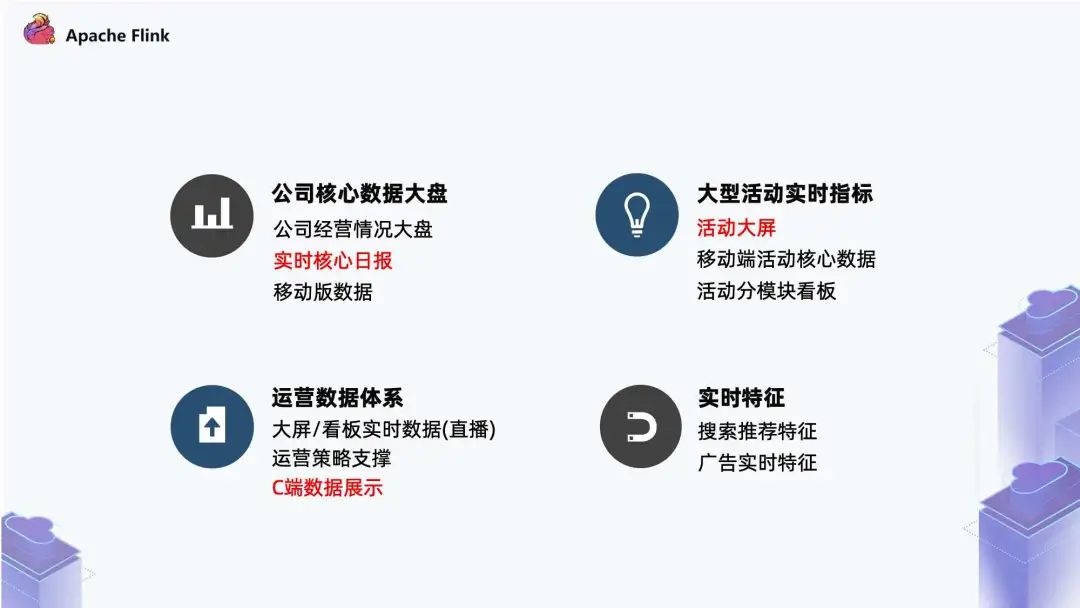
一、快手实时计算场景快手业务中的实时计算场景主要分为四块: 公司级别的核心数据:包括公司经营大盘,实时核心日报,以及移动版数据。相当于团队会有公司的大盘指标,以及各个业务线,比如视频相关、直播相关,都会有一个核心的实时看板; 大型活动实时指标:其中最核心的内容是实时大屏。例如快手的春晚 zz~~ 3年前 (2021-09-24) 713℃ 0评论3喜欢
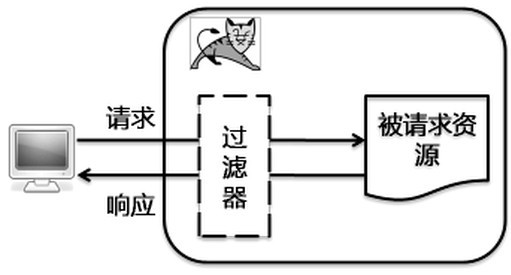
一、过滤器 从过滤器这个名字上可以得知就是在源数据和目标数据之间起到过滤作用的中间组件。例如家里用的纯净水过滤器,将自来水过滤为纯净水。过滤器是在Servlet2.3规范中引入的新功能,并在Servlet2.4规范中得到增强。它是在服务端运行的Web组件程序,可以截取客户端给服务器发的请求,也可以截取服务器给客户端的响应。 w397090770 11年前 (2013-08-01) 3637℃ 0评论5喜欢
Spark支持三种模式的部署:YARN、Standalone以及Mesos。本篇说到的Worker只有在Standalone模式下才有。Worker节点是Spark的工作节点,用于执行提交的作业。我们先从Worker节点的启动开始介绍。 Spark中Worker的启动有多种方式,但是最终调用的都是org.apache.spark.deploy.worker.Worker类,启动Worker节点的时候可以传很多的参数:内存、核、工作 w397090770 10年前 (2014-10-08) 11302℃ 3评论7喜欢
Elasticsearch 5.0.0在2016年10月26日发布,该版本基于Lucene 6.2.0,这是最新的稳定版本,并且已经在Elastic Cloud上完成了部署。Elasticsearch 5.0.0是目前最快、最安全、最具弹性、最易用的版本,此版本带来了一系列的新功能和性能优化。ElasticSearch 5.0.0 release Note点击下载ElasticSearch 5.0.0阅读最新文档如果想及时了解Spark、Hadoop或者Hbase w397090770 8年前 (2016-11-02) 4932℃ 0评论10喜欢
背景 B站的YARN以社区的2.8.4分支构建,采用CapacityScheduler作为调度器, 期间进行过多次核心功能改造,目前支撑了B站的离线业务、实时业务以及部分AI训练任务。2020年以来,随着B站业务规模的迅速增长,集群总规模达到8k左右,其中单集群规模已经达到4k+ ,日均Application(下文简称App)数量在20w到30w左右。当前最大单集群整体cpu w397090770 2年前 (2022-04-11) 672℃ 0评论1喜欢
Apache Hadoop 3.0.0-alpha1相对于hadoop-2.x来说包含了许多重要的改进。这里介绍的是Hadoop 3.0.0的alpha版本,主要是便于检测和收集应用开发人员和其他用户的使用反馈。因为是alpha版本,所以本版本的API稳定性和质量没有保证,如果需要在正式开发中使用,请耐心等待稳定版的发布吧。本文将对Hadoop 3.0.0重要的改进进行介绍。Java最低 zz~~ 8年前 (2016-09-22) 3344℃ 0评论7喜欢
本文将介绍如何在Google Compute Engine(https://cloud.google.com/compute/)平台上基于 Hadoop 1 或者 Hadoop 2 自动部署 Flink 。借助 Google 的 bdutil(https://cloud.google.com/hadoop/bdutil) 工具可以启动一个集群并基于 Hadoop 部署 Flink 。根据下列步骤开始我们的Flink部署吧。要求(Prerequisites)安装(Google Cloud SDK) 请根据该指南了解如何安装 Google Cl w397090770 8年前 (2016-04-21) 1745℃ 0评论3喜欢
Apache Hadoop 2.7.1于美国时间2015年07月06日正式发布,本版本属于稳定版本,是自Hadoop 2.6.0以来又一个稳定版,同时也是Hadoop 2.7.x版本线的第一个稳定版本,也是 2.7版本线的维护版本,变化不大,主要是修复了一些比较严重的Bug(其中修复了131个Bugs和patches)。比较重要的特性请参见《Hadoop 2.7.0发布:不适用于生产和不支持JDK1.6》 w397090770 9年前 (2015-07-08) 17832℃ 0评论23喜欢
虽然在运行Hadoop的时候可以打印出大量的运行日志,但是很多时候只通过打印这些日志是不能很好地跟踪Hadoop各个模块的运行状况。这时候编译与调试Hadoop源码就得派上场了。这也就是今天本文需要讨论的。编译Hadoop源码 先说说怎么编译Hadoop源码,本文主要介绍在Linux环境下用Maven来编译Hadoop。在编译Hadoop之前,我们 w397090770 10年前 (2014-01-09) 19820℃ 0评论10喜欢
Spark Streaming和Flink都能提供恰好一次的保证,即每条记录都仅处理一次。与其他处理系统(比如Storm)相比,它们都能提供一个非常高的吞吐量。它们的容错开销也都非常低。之前,Spark提供了可配置的内存管理,而Flink提供了自动内存管理,但从1.6版本开始,Spark也提供了自动内存管理。这两个流处理引擎确实有许多相似之处, w397090770 8年前 (2016-04-02) 4619℃ 0评论5喜欢
[caption id="attachment_751" align="aligncenter" width="536"] Guava学习之SetMultimap[/caption] SetMultimap及其子类的继承图如上所示。 SetMultimap是一个接口,继承自Multimap接口,同昨天说的ListMultimap接口类似,它也定义了所有继实现自SetMultimap的子类定义了一些共有的方法签名。SetMultimap接口并没有定义自己特有的方法签名,里面所 w397090770 11年前 (2013-09-25) 9048℃ 1评论4喜欢
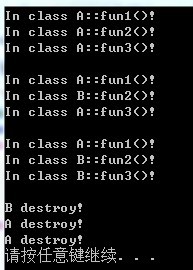
有虚函数的类内部有一个称为“虚表”的指针,这个就是用来指向这个类虚函数。也就是用它来确定调用该那个函数。例如:[code lang="CPP"]#include <iostream>using namespace std;class A{public: virtual void fun1(){ cout << "In class A::fun1()!" << endl; } virtual void fun2(){ cout << "In class A::fun2()!" << endl; w397090770 11年前 (2013-04-03) 2405℃ 0评论1喜欢
第一题,基础题: 1. 数据库及线程产生死锁的原理和必要条件,如何避免死锁。 2. 列举面向对象程序设计的三个要素和五项基本原则。 3.Windows内存管理的方式有哪些?各自的优缺点。第二题,算法与程序设计: 1.公司举行羽毛球比赛,采用淘汰赛,有1001个人参加,要决出“羽毛球最高选手”,应如何组织这 w397090770 11年前 (2013-04-20) 9097℃ 0评论9喜欢
我在《Apache Kafka消息格式的演变(0.7.x~0.10.x)》文章中介绍了 Kafka 几个版本的消息格式。仔细的同学肯定看到了在 MessageSet 中的 Message 都有一个 Offset 与之一一对应,本文将探讨 Kafka 各个版本对消息中偏移量的处理。同样是从 Kafka 0.7.x 开始介绍,并依次介绍到 Kafka 0.10.x,由于 Kafka 0.11.x 正在开发中,而且消息格式已经和之前版本大不 w397090770 7年前 (2017-08-16) 5026℃ 0评论16喜欢
最新Google IP地址请到《Google最新IP》里面获取。 最新的Google访问方法请查看《最新Google翻墙办法》 根据Google透明度报告显示,从5月27日开始,Google的部分服务开始被屏蔽,其中最主要的是HTTPS搜索服务和Google登录服务,所有版本的Google都受到影响,包括Google.hk和Google.com等。 此次屏蔽的方法主要屏蔽Google w397090770 10年前 (2014-06-09) 31208℃ 4评论32喜欢
在即将发布的 Apache Spark™ 3.2 版本中 pandas API 将会成为其中的一部分。Pandas 是一个强大、灵活的库,并已迅速发展成为标准的数据科学库之一。现在,pandas 的用户将能够在他们现有的 Spark 集群上利用 pandas API。几年前,我们启动了 Koalas 这个开源项目,它在 Spark 之上实现了 Pandas DataFrame API,并被数据科学家广泛采用。最近,Koala w397090770 3年前 (2021-10-13) 720℃ 0评论3喜欢
用 Kafka 这么久,从来都没去了解 Kafka 消息的格式。今天特意去网上搜索了以下,发现这方面的资料真少,很多资料都是官方文档的翻译;而且 Kafka 消息支持压缩,对于压缩消息的格式的介绍更少。基于此,本文将以图文模式介绍 Kafka 0.7.x、0.8.x 以及 0.10.x 等版本 Message 格式,因为 Kafka 0.9.x 版本的消息格式和 0.8.x 一样,我就不单独 w397090770 7年前 (2017-08-11) 3553℃ 0评论16喜欢
Flink可以在单台机器上运行,甚至是单个Java虚拟机(Java Virtual Machine)。这种机制使得用户可以在本地测试或者调试Flink程序。本节主要概述Flink本地模式的运行机制。 本地环境和执行器(executors)运行你在本地的Java虚拟机上运行Flink程序,或者是在属于正在运行程序的如何Java虚拟机上。对于大部分示例程序而言,你只需简单 w397090770 8年前 (2016-04-27) 16308℃ 0评论19喜欢
昨天我提到了如何在《Flink Streaming中实现多路文件输出(MultipleTextOutputFormat)》,里面我们实现了一个MultipleTextOutputFormatSinkFunction类,其中封装了mutable.Map[String, TextOutputFormat[String]],然后根据key的不一样选择不同的TextOutputFormat从而实现了文件的多路输出。本文将介绍如何在Flink batch模式下实现文件的多路输出,这种模式下比较简单 w397090770 8年前 (2016-05-11) 3982℃ 3评论6喜欢
Spark目前被越来越多的企业使用,和Hadoop一样,Spark也是以作业的形式向集群提交任务,那么在内部实现Spark和Hadoop作业模型都一样吗?答案是不对的。 熟悉Hadoop的人应该都知道,用户先编写好一个程序,我们称为Mapreduce程序,一个Mapreduce程序就是一个Job,而一个Job里面可以有一个或多个Task,Task又可以区分为Map Task和Reduce T w397090770 10年前 (2014-11-11) 21075℃ 1评论34喜欢
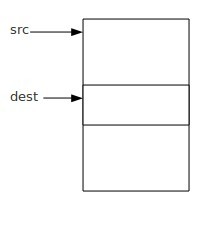
memcpy函数在面试中很容易被问到如何去实现。memcpy函数是内存拷贝函数,用于将一段内存空间数据拷贝到另一段内存空间中,但是它和memmove函数不同的是,它对内存空间有要求的,dest和src所指向的内存空间不能重叠,否则的数据是错误的。例如:src所指向的内存空间后面部分数据被新拷贝的数据给覆盖了,所以拷贝到最后,数 w397090770 11年前 (2013-04-05) 20187℃ 8喜欢
在Scala中一个很强大的功能就是模式匹配,本文并不打算介绍模式匹配的概念以及如何使用。本文的主要内容是讨论Scala模式匹配泛型类型擦除问题。先来看看泛型类型擦除是什么情况:scala> def test(a:Any) = a match { | case a :List[String] => println("iteblog is ok"); | case _ => |} 按照代码的意思应该是匹配L w397090770 9年前 (2015-10-28) 6327℃ 0评论11喜欢
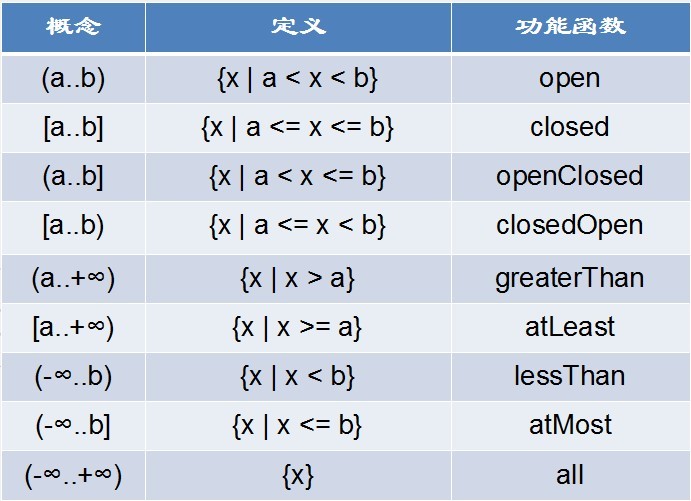
在Guava中新增了一个新的类型Range,从名字就可以了解到,这个是和区间有关的数据结构。从Google官方文档可以得到定义:Range定义了连续跨度的范围边界,这个连续跨度是一个可以比较的类型(Comparable type)。比如1到100之间的整型数据。不过我们无法遍历出这个区间里面的值。如果需要达到这个目的,我们可以将这个范围传给Conti w397090770 11年前 (2013-07-15) 5232℃ 0评论4喜欢
本文节选自《大数据之路:阿里巴巴大数据实践》,关注 iteblog_hadoop 公众号并在这篇文章里面文末评论区留言(认真写评论,增加上榜的机会)。留言点赞数排名前5名的粉丝,各免费赠送一本《大数据之路:阿里巴巴大数据实践》,活动截止至08月11日18:00。这篇文章评论区留言才有资格参加送书活动:https://mp.weixin.qq.com/s/BR7M8Rty w397090770 7年前 (2017-08-03) 1655℃ 0评论11喜欢
使用过 Chrome 浏览器的用户都应该安装过插件,但是我们从 Google 的应用商店下载插件是无法直接获取到下载地址的。不过我们总是有些需求需要获取到这些插件的地址,比如朋友想安装某个插件,但是因为某些原因无法访问 Google 应用商店,而我可以访问,这时候我们就想如果能获取到插件的下载地址,直接下载好然后发送给朋友 w397090770 7年前 (2017-08-23) 4259℃ 0评论10喜欢
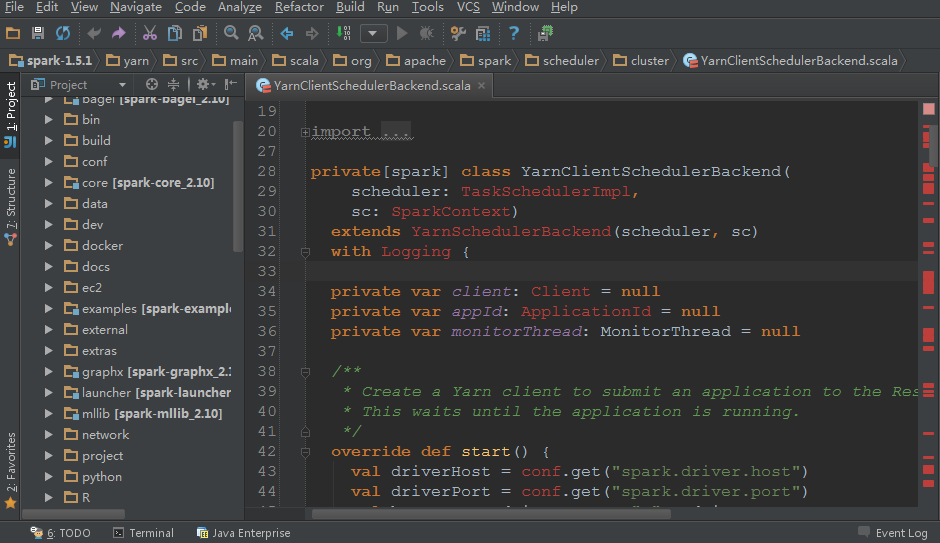
我们在学习或者使用Spark的时候都会选择下载Spark的源码包来加强Spark的学习。但是在导入Spark代码的时候,我们会发现yarn模块的相关代码总是有相关类依赖找不到的错误(如下图),而且搜索(快捷键Ctrl+N)里面的类时会搜索不到!这给我们带来了很多不遍。。 本文就是来解决这个问题的。我使用的是Idea IDE工具阅读代 w397090770 9年前 (2015-11-07) 8951℃ 4评论11喜欢
Linux(vi/vim)一般模式语法功能描述yy复制光标当前一行y数字y复制一段(从第几行到第几行)p箭头移动到目的行粘贴u撤销上一步dd删除光标当前行d数字d删除光标(含)后多少行x删除一个字母,相当于delX删除一个字母,相当于Backspaceyw复制一个词dw删除一个词 zz~~ 2年前 (2021-12-01) 145℃ 0评论0喜欢
本书由Packt出版,2016年10月发行,全书共332页。从标题可以看出这本书是适用于初学者的,全书的例子有Scala和Python两个版本,涵盖了Spark基础、编程模型、SQL、Streaming、机器学习以及图计算等知识。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节如下:[code lang="bash"]Chapter 1: w397090770 8年前 (2016-10-24) 5870℃ 0评论8喜欢
在Spark 1.4中引入了REST API,这样我们可以像Hadoop中REST API一样,很方便地获取一些信息。这个ISSUE在https://issues.apache.org/jira/browse/SPARK-3644里面首先被提出,已经在Spark 1.4加入。 Spark的REST API返回的信息是JSON格式的,开发者们可以很方便地通过这个API来创建可视化的Spark监控工具。目前这个API支持正在运行的应用程序,也支持 w397090770 9年前 (2015-06-10) 15640℃ 0评论8喜欢














![[电子书]Apache Spark 2 for Beginners pdf下载](https://www.iteblog.com/pic/Apache_Spark_2_for_Beginners.jpg)
