哎哟~404了~休息一下,下面的文章你可能很感兴趣:
本程序用来仿照linux中的ls -l命令来实现的,主要运用的函数有opendir,readdir, lstat等。代码如下:[code lang="CPP"]#include <iostream>#include <vector>#include <cstdlib>#include <dirent.h>#include <sys/types.h>#include <sys/stat.h>#include <unistd.h>#include <cstring>#include <algorithm>using namespace std;void getFileAndDir(vector w397090770 11年前 (2013-04-04) 2614℃ 0评论0喜欢
本书旨在通过教你如何扩展Spark的功能,将你对Spark的有限知识提升到一个新的水平。全书从Spark生态系统开始概述,您将学习如何使用MLlib创建一个完全的神经网络系统,然后您将了解如何调整流处理以获得最佳性能并确保并行处理。本书作者Mike Frampton,由Packt 于2015年09月出版,全书318页,通过本书你将学到以下知识: ( w397090770 7年前 (2016-12-04) 3669℃ 0评论9喜欢
一、先来先服务和短作业(进程)优先调度算法1.先来先服务调度算法先来先服务(FCFS)调度算法是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。当在作业调度中采用该算法时,每次调度都是从后备作业队列中选择一个或多个最先进入该队列的作业,将它们调入内存,为它们分配资源、创建进程,然后放入 w397090770 11年前 (2013-04-10) 14260℃ 0评论19喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive的数据分为表数据和元 w397090770 10年前 (2013-12-18) 14842℃ 0评论22喜欢
近日,被誉为最好的Java开发工具IntelliJ IDEA发布了IntelliJ IDEA 2016.2版本,这是本年度第二个发行版本。此版本带来了许多新功能,本文将列举部分比较好的功能。调试器Debugger新版本的Idea将Watches和Variables面板合在一起。此外多行表达式(multiline expressions)功能现在在断点设置中支持Condition、Evaluate和log fields,并且在Data Type w397090770 8年前 (2016-07-16) 6186℃ 0评论17喜欢
关系运算1、等值比较: =语法:A=B操作类型:所有基本类型描述: 如果表达式A与表达式B相等,则为TRUE;否则为FALSE[code lang="sql"]hive> select 1 from iteblog where 1=1;1[/code]2、不等值比较: 语法: A B操作类型: 所有基本类型描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A与表达式B不相等,则为TRUE;否则为 zz~~ 7年前 (2017-09-14) 92463℃ 3评论179喜欢
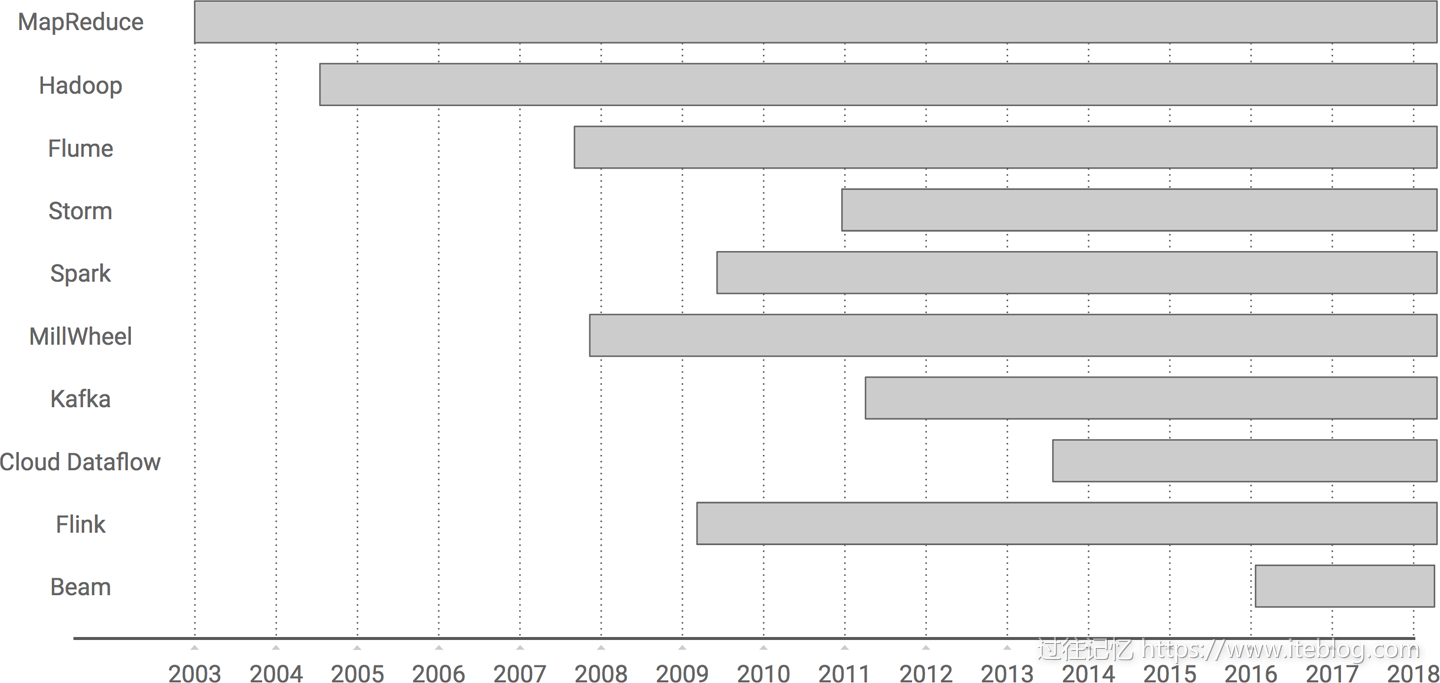
本文翻译自《Streaming System》最后一章《The Evolution of Large-Scale Data Processing》,在探讨流式系统方面本书是市面上难得一见的深度书籍,非常值得学习。大数据如果从 Google 对外发布 MapReduce 论文算起,已经前后跨越十五年,我打算在本文和你蜻蜓点水般一起浏览下大数据的发展史,我们从最开始 MapReduce 计算模型开始,一路走马观 w397090770 6年前 (2018-10-08) 10015℃ 2评论27喜欢
为什么禁止推酷网站收录本博客文章 近一段时间观察发现,推酷网站 在我发出文章不到几分钟内就收录了,由于我网站权重很低,导致从搜索引擎里面搜索到的文章很多直接链接到推酷网站,而不能显示到我博客,这严重影响我网站! 这就是为什么每次我发文章开始都会要求回复可见。已通知推酷网处理 本 w397090770 10年前 (2014-10-17) 14050℃ 15评论65喜欢
2017年已然来临,大数据技术仍然保持着飞速发展。无论是物联网、云计算领域乃至企业技术都开始将其引入自身并作为新的变革方向。众多企业已经在积极接纳大数据技术,并作为提升自身市场竞争力的核心因素。在今天的文章中,我们将基于甲骨文给出的预测结论,总结2017年十项大数据变化趋势。如果想及时了解Spark、H w397090770 7年前 (2017-02-17) 1026℃ 0评论3喜欢
流式处理是大数据应用中的非常重要的一环,在Spark中Spark Streaming利用Spark的高效框架提供了基于micro-batch的流式处理框架,并在RDD之上抽象了流式操作API DStream供用户使用。 随着流式处理需求的复杂化,用户希望在流式数据中引入较为复杂的查询和分析,传统的DStream API想要实现相应的功能就变得较为复杂,同时随着Spark w397090770 8年前 (2016-11-16) 6085℃ 0评论13喜欢
默认情况下,Flume中的PollingPropertiesFileConfigurationProvider会每隔30秒去重新加载Flume agent的配置文件,如果监听到配置文件变化了,Flume会试图重新加载变化的配置文件。判断配置文件是否变化主要是基于文件的最后修改时间来的,代码片段如下:[code lang="java"]///////////////////////////////////////////////////////////////////// User: 过往记忆 w397090770 9年前 (2015-08-20) 6584℃ 0评论11喜欢
我们在这篇文章简单介绍了 Apache Cassandra 是什么,以及有什么值得关注的特性。本文将简单介绍 Apache Cassandra 的安装以及简单使用,可以帮助大家快速了解 Apache Cassandra。我们到 Apache Cassandra 的官方网站下载最新版本的 Cassandra,在本文写作时最新版本的 Cassandra 为 3.11.4。Apache Cassandra 可以在 Linux、Unix、Mac OS 以及 Windows 上进行安装 w397090770 5年前 (2019-04-07) 5007℃ 0评论8喜欢
今天谈谈Guava类库中的Multisets数据结构,虽然它不怎么经常用,但是还是有必要对它进行探讨。我们知道Java类库中的Set不能存放相同的元素,且里面的元素是无顺序的;而List是能存放相同的元素,而且是有顺序的。而今天要谈的Multisets是能存放相同的元素,但是元素之间的顺序是无序的。从这里也可以看出,Multisets肯定不是实 w397090770 11年前 (2013-07-11) 4641℃ 0评论1喜欢
CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号。在本文中的CSV格式的数据就不是简单的逗号分割的),其文件以纯文本形式存储表格数据(数字和文本)。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字 w397090770 9年前 (2015-01-26) 9529℃ 0评论12喜欢
据估计,到2017年底,90%的CPU cycles 将会致力于移动硬件,移动计算正在迅速上升到主导地位。Spark为此重新设计了Spark体系结构,允许Spark在移动设备上运行Spark。 Spark为现代化数据中心和大数据应用进行设计和优化,但是它目前不适合移动计算。在过去的几个月中,Spark社区正在调研第一个可以在移动设备上运行架构的可 w397090770 9年前 (2015-04-14) 8003℃ 0评论10喜欢
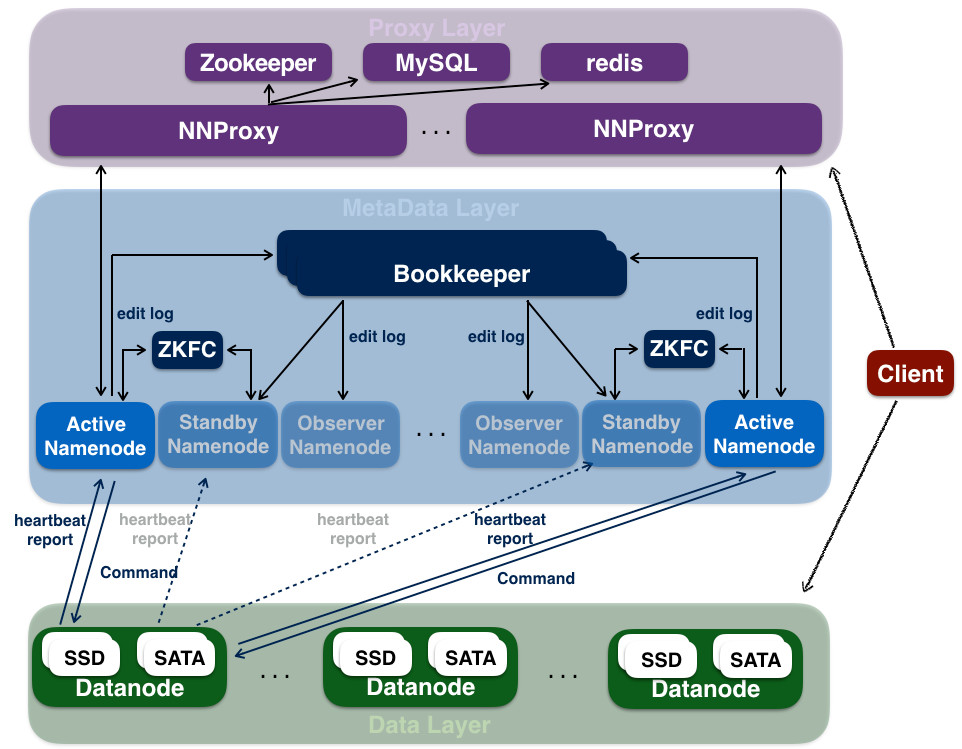
HDFS 简介因为 HDFS 这样一个系统已经存在了非常长的时间,应用的场景已经非常成熟了,所以这部分我们会比较简单地介绍。HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:和本地文件系统一样的目录树视图Append Only 的写入(不支持 w397090770 4年前 (2020-01-10) 2308℃ 0评论4喜欢
下面IP由于地区不同可能无法访问,请多试几个。 国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 218.204.143.87 8118 高匿名 HTTP w397090770 9年前 (2015-05-09) 25203℃ 0评论0喜欢
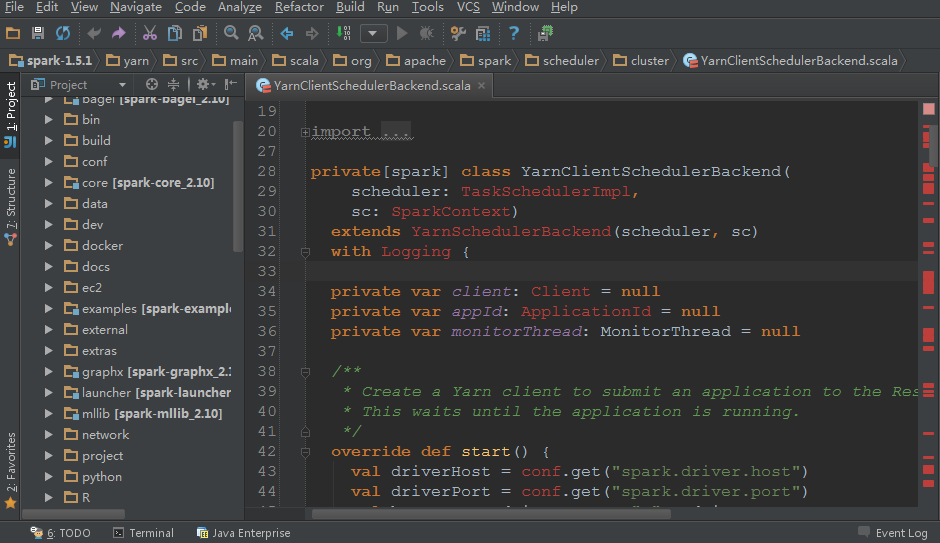
我们在学习或者使用Spark的时候都会选择下载Spark的源码包来加强Spark的学习。但是在导入Spark代码的时候,我们会发现yarn模块的相关代码总是有相关类依赖找不到的错误(如下图),而且搜索(快捷键Ctrl+N)里面的类时会搜索不到!这给我们带来了很多不遍。。 本文就是来解决这个问题的。我使用的是Idea IDE工具阅读代 w397090770 9年前 (2015-11-07) 8951℃ 4评论11喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 9年前 (2015-07-02) 3427℃ 0评论5喜欢
在过去一年有很多 Apache 孵化项目顺利毕业成顶级项目(Top-Level Project ,简称 TLP ),在这里我将给大家盘点 2020 年晋升为 Apache TLP 的大数据相关项目。在2020年一共有四个大数据相关项目顺利毕业成顶级项目,主要是 Apache® ShardingSphere™、Apache® Hudi™、Apache® Iceberg™ 以及 Apache® IoTDB™,这里以毕业的时间顺序依次介绍。关于过 w397090770 3年前 (2021-01-03) 1392℃ 0评论5喜欢
本书重点介绍如何分析大量而且复杂的数据集。本书开头介绍了如何在各种集群管理上安装和配置Apache Spark,其中也会涵盖开发环境的设置。然后介绍了如何通过Spark SQL和实时流对各种数据源进行交互式查询,其中的实时流包括了Twitter Stream 和 Apache Kafka。然后,本书将专注于机器学习,包括监督学习,无监督学习和推荐引擎算 w397090770 7年前 (2017-02-12) 3100℃ 0评论3喜欢
这几天由于项目的需要,需要将Flume收集到的日志插入到Hbase中,有人说,这不很简单么?Flume里面自带了Hbase sink,可以直接调用啊,还用说么?是的,我在本博客的《Flume-1.4.0和Hbase-0.96.0整合》文章中就提到如何用Flume和Hbase整合,从文章中就看出整个过程不太复杂,直接做相应的配置就行了。那么为什么今天还要特意提一下Flum w397090770 10年前 (2014-01-28) 7265℃ 2评论2喜欢
youtube-dl是一个精悍的命令程序,它可以从YouTube.com以及其他网站上下载视频。它是使用Python开发的,依赖于Python 2.6, 2.7, 或者3.2+解释器,而且这个视频下载命令是跨平台的,作者为我们带来了Windows执行文件(https://yt-dl.org/latest/youtube-dl.exe),其中就包含了Python。youtube-dl可以在Unix box,Windows或者是 Mac OS X平台上运行,支持众多视频网 w397090770 8年前 (2016-04-09) 6577℃ 0评论6喜欢
《Spark on YARN集群模式作业运行全过程分析》《Spark on YARN客户端模式作业运行全过程分析》《Spark:Yarn-cluster和Yarn-client区别与联系》《Spark和Hadoop作业之间的区别》《Spark Standalone模式作业运行全过程分析》(未发布) 在前篇文章中我介绍了Spark on YARN集群模式(yarn-cluster)作业从提交到运行整个过程的情况(详情见《Spar w397090770 10年前 (2014-11-04) 19473℃ 5评论12喜欢
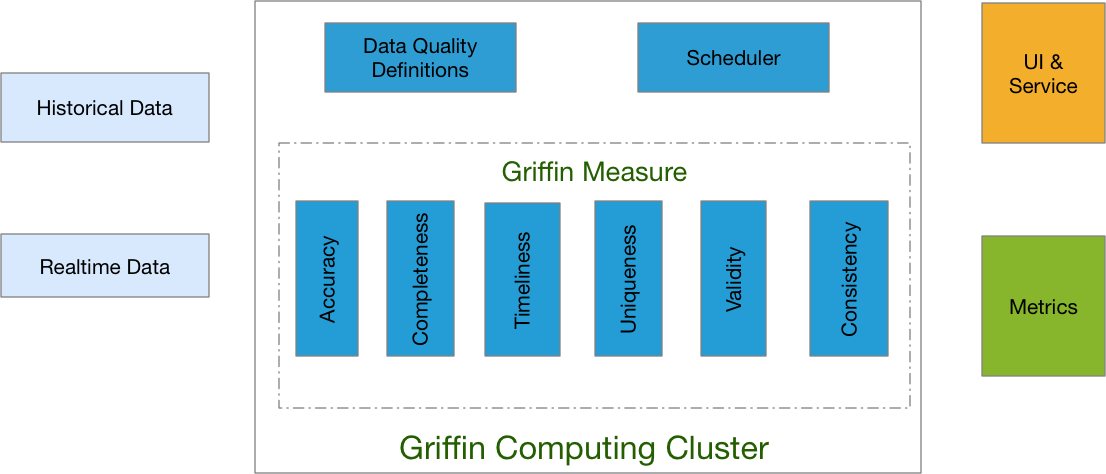
Apache Griffin 是开源的大数据数据质量解决方案,支持批处理和流模式,其是基于 Apache Hadoop 和 Apache Spark 构建,由 eBay 开发,并于 2016年12月07日进入 Apache 孵化。Griffin 提供了一个可以处理不同的任务,如定义数据质量模型,执行数据质量测量,自动化数据分析和验证,以及跨多个数据系统的统一数据质量可视化的全面的框架,旨在 w397090770 5年前 (2019-01-03) 9149℃ 3评论9喜欢
Elasticsearch提供了近乎实时的数据操作和搜索功能。默认情况下,从你索引/更新/删除你的数据动作开始到它出现在你的搜索结果中,大概会有1秒钟的延迟。这和其它的SQL平台不同,它们的数据在一个事务完成之后就会立即可用。索引/替换文档 我们先前看到,怎样索引一个文档。现在我们再次调用那个命令:[code lan zz~~ 8年前 (2016-09-03) 1564℃ 0评论4喜欢
下面所有的内容是针对Hadoop 2.x版本进行说明的,Hadoop 1.x和这里有点不一样。 在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘:[code lang="JAVA"][wyp@wyp hadoop-2.2.0]$ $HADOOP_HOME/bin/hdfs namenode -format[/code] 格式化完成之后,将会在$dfs.namenode.name.dir/current目录下如下的文件结构[code lang="JAVA"]c w397090770 10年前 (2014-03-04) 13236℃ 1评论17喜欢
下面论文均为大数据和分布式比较经典的论文,包括:CAP、BASE、2PC、一致性协议、一致性哈希、逻辑时钟、Leases 等。如果大家还有比较好的论文,欢迎在下面评论。分布式理论 Time, Clocks, and the Ordering of Events in a Distributed System Reaching Agreement in the Presence of Faults The Byzantine General Problem (CAP) Brewer's Conjecture and the Feasibility of w397090770 7年前 (2017-02-15) 3337℃ 0评论10喜欢
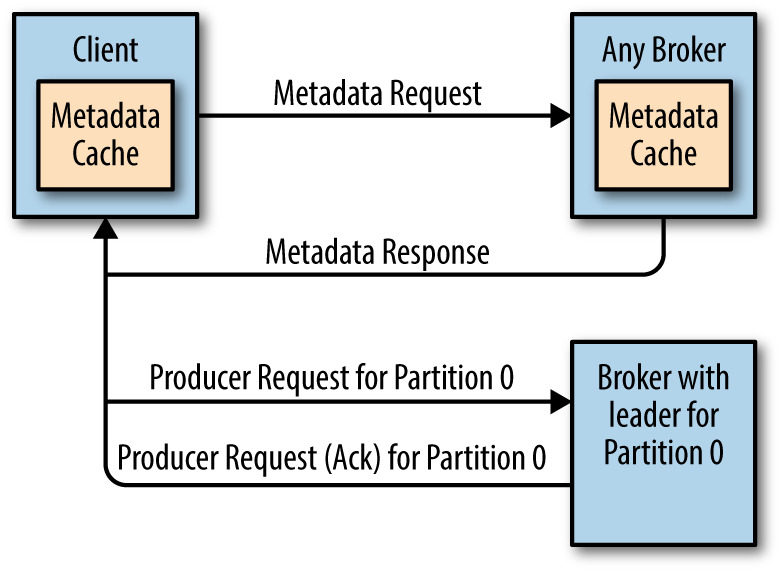
在正常情况下,Kafka中的每个Topic都会有很多个分区,每个分区又会存在多个副本。在这些副本中,存在一个leader分区,而剩下的分区叫做 follower,所有对分区的读写操作都是对leader分区进行的。所以当我们向Kafka写消息或者从Kafka读取消息的时候,必须先找到对应分区的Leader及其所在的Broker地址,这样才可以进行后续的操作。本文将 w397090770 7年前 (2017-07-28) 2027℃ 0评论6喜欢
相关图标矢量字库:《Font Awesome:图标字体》、《阿里巴巴矢量图标库:Iconfont》 Font Awesome是一种web font,它包含了几乎所有常用的图标,比如Twitter、facebook等等。用户可以自定义这些图标字体,包括大小、颜色、阴影效果以及其它可以通过CSS控制的属性。它有以下的优点: 1、像矢量图形一样,可以无限放大 2、只 w397090770 10年前 (2014-08-20) 44013℃ 1评论115喜欢

![[电子书]Mastering Apache Spark下载](https://www.iteblog.com/pic/books/Mastering_Apache_Spark.jpg)











![[电子书]Spark Cookbook PDF下载](https://www.iteblog.com/pic/books/spark_cookbook_iteblog.jpg)