哎哟~404了~休息一下,下面的文章你可能很感兴趣:
到目前为止,Scala 环境下至少存在6种 Json 解析的类库,这里面不包括 Java 语言实现的 Json 类库。所有这些库都有一个非常相似的抽象语法树(AST)。而 json4s 项目旨在提供一个单一的 AST 树供其他 Scala 类库来使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopjson4s 的使用非常的简单,它可以将 w397090770 6年前 (2018-11-15) 1080℃ 0评论4喜欢
2022年01月10日,来自 Cloudera 的工程师、Apache Ambari PMC 主席 Jayush Luniya 给 Ambari 社区发送了一封名为《[VOTE] Move Apache Ambari to Attic》的邮件:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据邮件内容显示,在过去的两年里,Ambari 只发布了一个版本(2.7.6),大多数提交者(Committer)和 PMC 成员 w397090770 2年前 (2022-01-16) 315℃ 0评论1喜欢
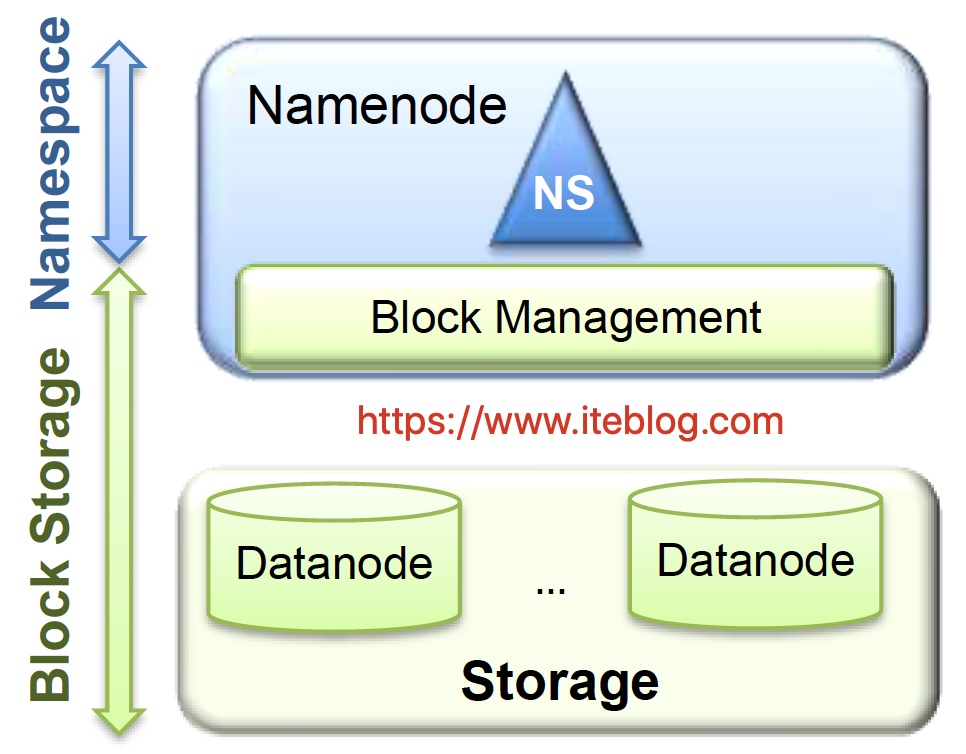
背景熟悉大数据的人应该都知道,HDFS 是一个分布式文件系统,它是基于谷歌的 GFS 思路实现的开源系统,它的设计目的就是提供一个高度容错性和高吞吐量的海量数据存储解决方案。在经典的 HDFS 架构中有2个 NameNode 和多个 DataNode 的,如下:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop从 w397090770 5年前 (2019-07-25) 2136℃ 0评论3喜欢
随着图像分类(image classification)和对象检测(object detection)的深度学习框架的最新进展,开发者对 Apache Spark 中标准图像处理的需求变得越来越大。图像处理和预处理有其特定的挑战 - 比如,图像有不同的格式(例如,jpeg,png等),大小和颜色,并且没有简单的方法来测试正确性。图像数据源通过给我们提供可以编码的标准表 w397090770 5年前 (2018-12-13) 2374℃ 0评论4喜欢
Flink内置提供了将DataStream中的数据写入到ElasticSearch中的Connector(flink-connector-elasticsearch2_2.10),但是并没有提供将DateSet的数据写入到ElasticSearch。本文介绍如何通过自定义OutputFormat将Flink DateSet里面的数据写入到ElasticSearch。 如果需要将DateSet中的数据写入到外部存储系统(比如HDFS),我们可以通过writeAsText、writeAsCsv、write等内 w397090770 8年前 (2016-10-11) 5679℃ 0评论8喜欢
Apache Hadoop 3.0.0-alpha1相对于hadoop-2.x来说包含了许多重要的改进。这里介绍的是Hadoop 3.0.0的alpha版本,主要是便于检测和收集应用开发人员和其他用户的使用反馈。因为是alpha版本,所以本版本的API稳定性和质量没有保证,如果需要在正式开发中使用,请耐心等待稳定版的发布吧。本文将对Hadoop 3.0.0重要的改进进行介绍。Java最低 zz~~ 8年前 (2016-09-22) 3344℃ 0评论7喜欢
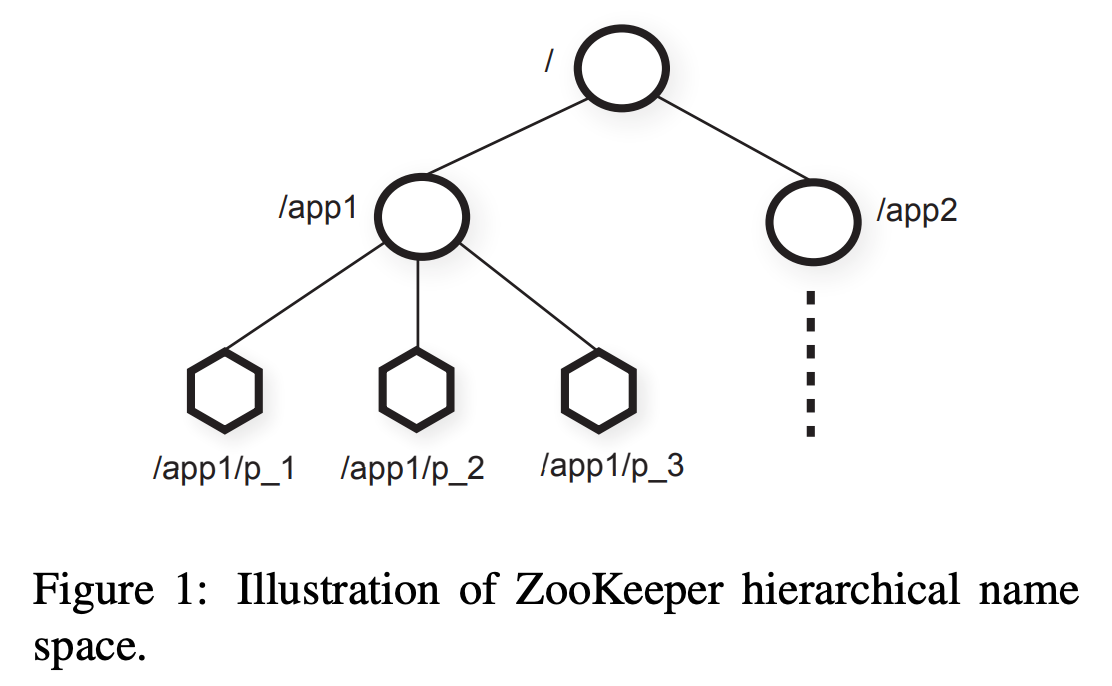
摘要本文描述分布式应用的协调服务:ZooKeeper。ZooKeeper是关键基础设施的一部分,其目标是给客户端提供简洁高性能内核用于构建复杂协调原语。在一个多副本、中心化服务中,结合了消息群发、共享注册和分布式锁等内容。ZooKeeper提供的接口有共享注册无等待的特点,与事件驱动的分布式系统缓存失效类似,还提供了强大的协调 w397090770 4年前 (2020-03-17) 509℃ 0评论1喜欢
据估计,到2017年底,90%的CPU cycles 将会致力于移动硬件,移动计算正在迅速上升到主导地位。Spark为此重新设计了Spark体系结构,允许Spark在移动设备上运行Spark。 Spark为现代化数据中心和大数据应用进行设计和优化,但是它目前不适合移动计算。在过去的几个月中,Spark社区正在调研第一个可以在移动设备上运行架构的可 w397090770 9年前 (2015-04-14) 8003℃ 0评论10喜欢
Protobuf (全称 Protocol Buffers)是 Google 开发的一种数据描述语言,能够将结构化数据序列化,可用于数据存储、通信协议等方面。在 HBase 里面用使用了 Protobuf 的类库,目前 Protobuf 最新版本是 3.6.1(参见这里),但是在目前最新的 HBase 3.0.0-SNAPSHOT 对 Protobuf 的依赖仍然是 2.5.0(参见 protobuf.version),但是这些版本的 Protobuf 是互补兼 w397090770 5年前 (2018-11-26) 5292℃ 0评论10喜欢
《Hadoop&Spark解决二次排序问题(Spark篇)》《Hadoop&Spark解决二次排序问题(Hadoop篇)》问题描述二次排序就是key之间有序,而且每个Key对应的value也是有序的;也就是对MapReduce的输出(KEY, Value(v1,v2,v3,......,vn))中的Value(v1,v2,v3,......,vn)值进行排序(升序或者降序),使得Value(s1,s2,s3,......,sn),si ∈ (v1,v2,v3,......,vn)且s1 < s2 < s3 < ..... w397090770 9年前 (2015-08-06) 11278℃ 6评论29喜欢
大家肯定都知道要想在国内下载一个项目到本地速度太慢了。可以试试下面方案,把原地址:https://github.com/xxx.git 替换为:https://github.com.cnpmjs.org/xxx.git 即可。比如我们要克隆下面项目到本地,可以操作如下:[code lang="bash"][root@iteblog.com ~]$ git clone https://github.com.cnpmjs.org/397090770/web正克隆到 'web'...Username for 'https://github.com.cnpmjs.org w397090770 5年前 (2019-06-14) 841℃ 0评论1喜欢
With MongoDB 3.6 the query language gains a new level of expressivity: you can now make use of aggregation expressions in a query using the $expr operator. This feature allows you to take full advantage of all expression operators within all queries, much of which previously had to be done within application logic or was restricted to the aggregation pipeline. $expr offers better performance than the $where operator, which while still a w397090770 3年前 (2021-04-27) 2243℃ 0评论2喜欢
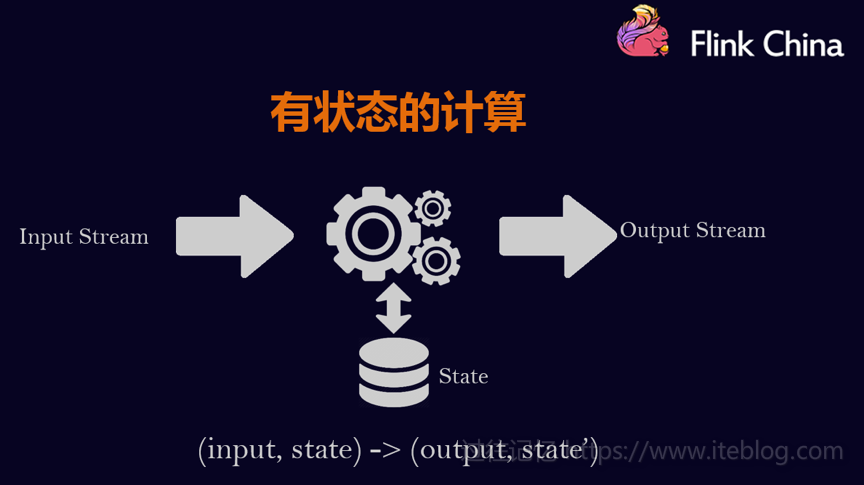
本文整理自8月11日在北京举行的 Flink Meetup 会议,分享嘉宾施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发。本文由韩非(Flink China社区志愿者)整理一、有状态的流数据处理1、什么是有状态的计算计算任务的结果不仅仅依赖于输入,还依赖于它的当前状态,其实大 w397090770 6年前 (2018-08-24) 9052℃ 0评论21喜欢
TreeMultimap类是Multimap接口的实现子类,其中的key和value都是根据默认的自然排序或者用户指定的排序规则排好序的。在任何情况下,如果你想判断TreeMultimap中两个元素是否相等,都不要使用equals方法去实现,而需要用compareTo或compare函数去判断。下面探讨一下TreeMultimap类的源码实现:[code lang="JAVA"] TreeMultimap里面一共有两 w397090770 11年前 (2013-10-09) 7258℃ 1评论2喜欢
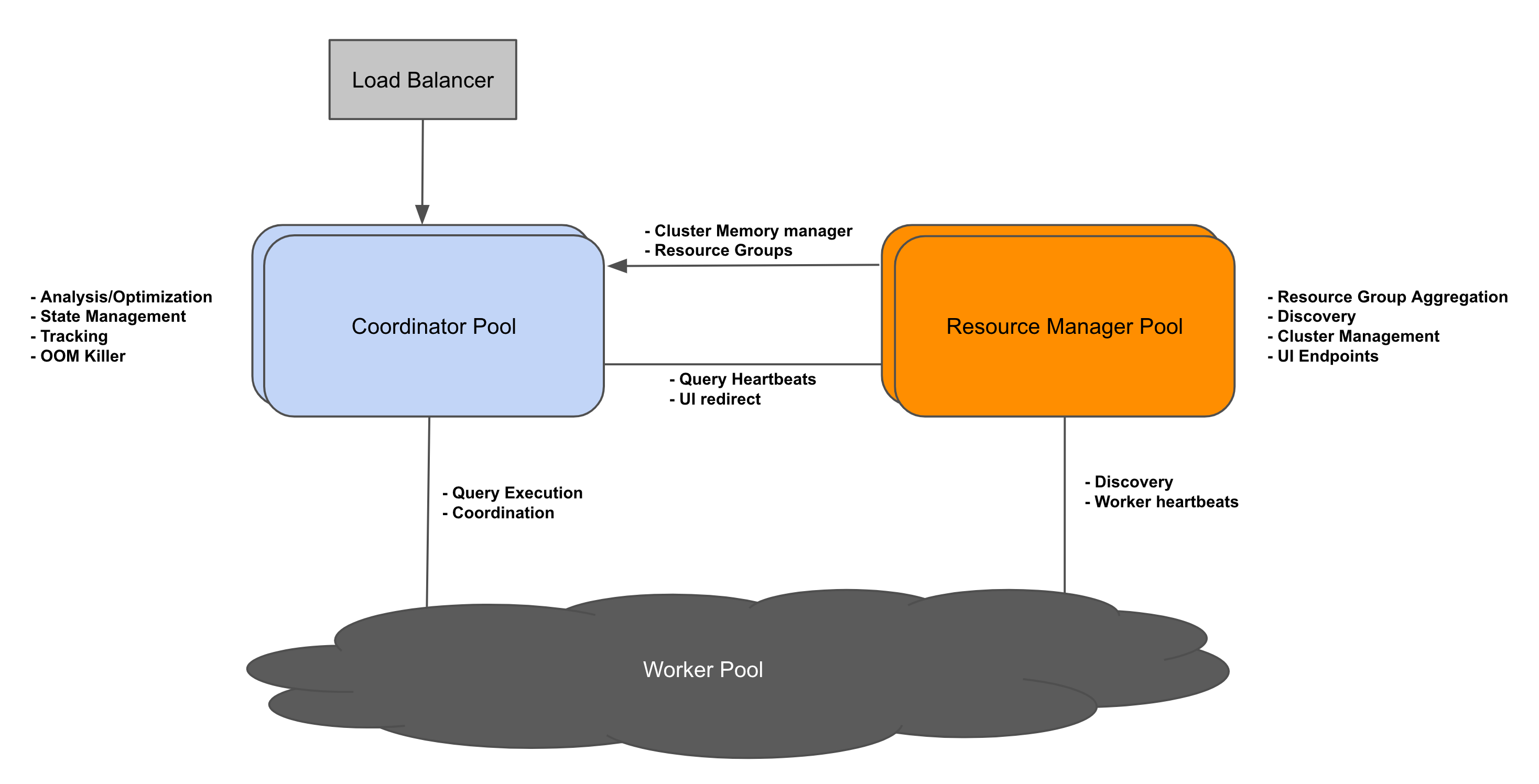
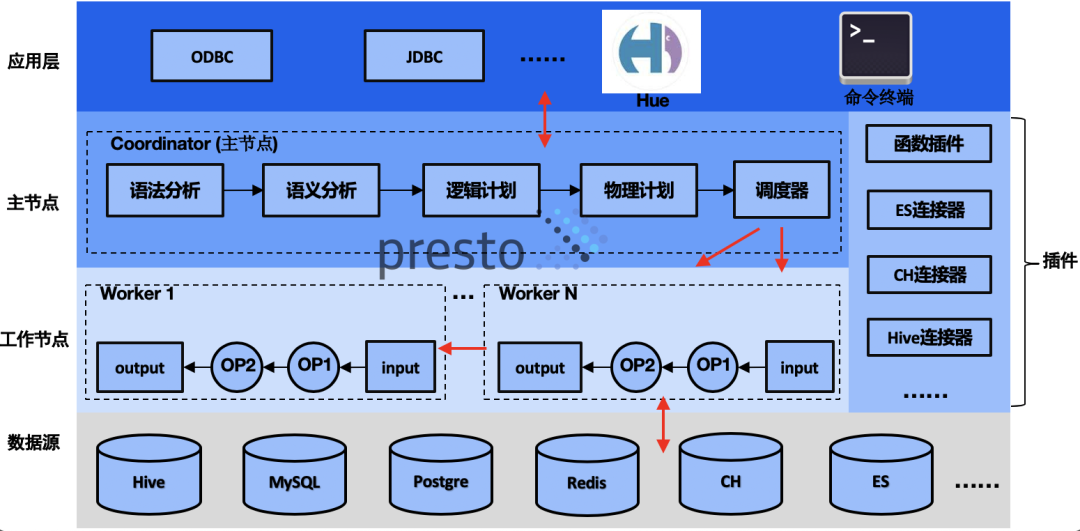
背景Presto 的架构最初只支持一个 coordinator 和多个 workers。多年来,这种方法一直很有效,但也带来了一些新挑战。使用单个 coordinator,集群可以可靠地扩展到一定数量的 worker。但是运行复杂、多阶段查询的大集群可能会使供应不足的 coordinator 不堪重负,因此需要升级硬件来支持工作负载的增加。单个 coordinator 存在单点故障 zz~~ 2年前 (2022-04-22) 804℃ 0评论1喜欢
在《Flink本地模式安装(Local Setup)》的文章中,我简单地介绍了如何本地模式安装(Local Setup)Flink,本文将介绍如何Flink集群模式安装,主要是Standalone方式。要求(Requirements)Flink可以在Linux, Mac OS X 以及Windows(通过Cygwin)等平台上运行。集群模式主要是由一个master节点和一个或者多个worker节点组成。在你启动集群的各个组件之前 w397090770 8年前 (2016-04-20) 11832℃ 0评论9喜欢
引言 在字节跳动内部,Presto 主要支撑了 Ad-hoc 查询、BI 可视化分析、近实时查询分析等场景,日查询量接近 100 万条。 功能性方面 完全兼容 SparkSQL 语法,可以实现用户从 SparkSQL 到 Presto 的无感迁移; 性能方面 实现 Join Reorder,Runtime Filter 等优化,在 TPCDS1T 数据集上性能相对社区版本提升 80.5%; 稳定性方面 首先,实 w397090770 2年前 (2021-12-30) 600℃ 0评论0喜欢
在 LinkedIn,我们使用 Hadoop 作为大数据分析和机器学习的基础组件。随着数据量呈指数级增长,并且公司在机器学习和数据科学方面进行了大量投资,我们的集群规模每年都在翻倍,以匹配计算工作负载的增长。我们最大的集群现在有大约 10,000 个节点,是全球最大(如果不是最大的)Hadoop 集群之一。多年来,扩展 Hadoop YARN 已成为 w397090770 3年前 (2021-09-18) 497℃ 0评论2喜欢
Data + AI Summit 2022 于2022年06月27日至30日举行。本次会议是在旧金山进行,中国的小伙伴是可以在线收听的,一共为期四天,第一天是培训,后面几天才是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,本次会议主要分为六大块:数据分析, BI 以及可视化:了解最新的数据分析、BI 和可视化技术以及 w397090770 2年前 (2022-07-10) 519℃ 0评论3喜欢
Kafka 从首次发布之日起,已经走过了七个年头。从最开始的大规模消息系统,发展成为功能完善的分布式流式处理平台,用于发布和订阅、存储及实时地处理大规模流数据。来自世界各地的数千家公司在使用 Kafka,包括三分之一的 500 强公司。Kafka 以稳健的步伐向前迈进,首先加入了复制功能和无边界的键值数据存储,接着推出了用 w397090770 7年前 (2017-11-05) 24934℃ 0评论17喜欢
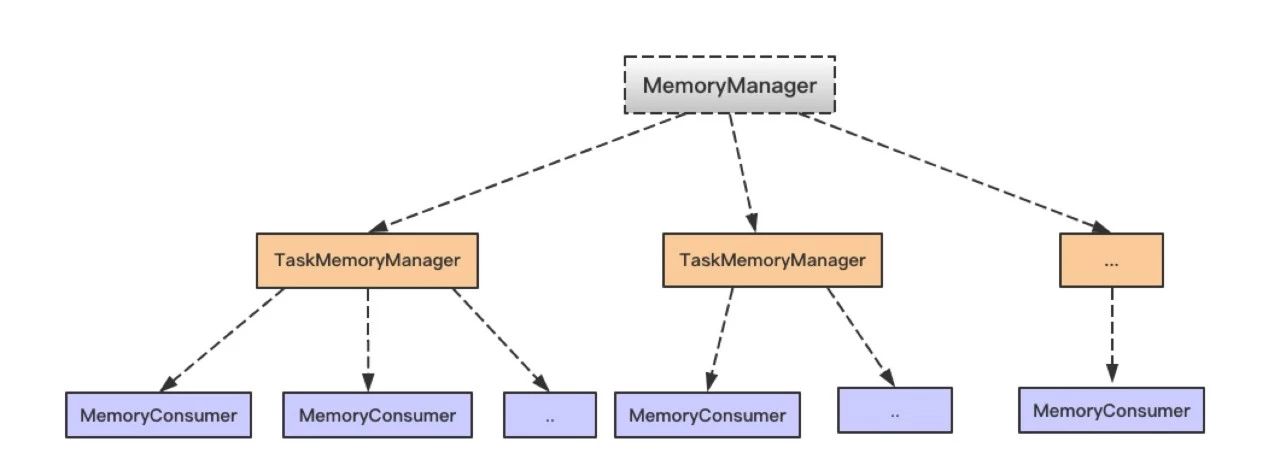
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段。那么在 Spark Shuffle 中具体是哪些地方会使用比较多的内存而有可能导致 OOM 呢? 为此,本文将围绕以上问题梳理 Spark 内存管理和 Shuffle 过程中与内存使用相关的知识;然后,简要分析下在 Spark Shuffle 中有可能导致 OOM w397090770 7年前 (2017-01-17) 778℃ 0评论1喜欢
Hadoop的一大基本原则是移动计算的开销要比移动数据的开销小。因此,Hadoop通常是尽量移动计算到拥有数据的节点上。这就使得Hadoop中读取数据的客户端DFSClient和提供数据的Datanode经常是在一个节点上,也就造成了很多“Local Reads”。最初设计的时候,这种Local Reads和Remote Reads(DFSClient和Datanode不在同一个节点)的处理方式都是一 w397090770 6年前 (2018-07-22) 57℃ 0评论0喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/好久没写Hive的那些事了,今 w397090770 10年前 (2014-02-19) 92325℃ 5评论128喜欢
文章来源团队:腾讯医疗资讯与服务部-技术研发中心 前言:随着产品矩阵和团队规模的扩张,跨业务、APP的数据处理、分析总是不可避免。一个显而易见的问题就是异构数据源的连通。我们基于PrestoDB构建了业务线内适应腾讯生态的联邦查询引擎,连通了部门内部20+数据源实例,涵盖了90%的查询场景。同时,我们参与公司级的Pre w397090770 3年前 (2021-09-08) 458℃ 0评论1喜欢
Resources提供提供操作classpath路径下所有资源的方法。除非另有说明,否则类中所有方法的参数都不能为null。虽然有些方法的参数是URL类型的,但是这些方法实现通常不是以HTTP完成的;同时这些资源也非classpath路径下的。 下面两个函数都是根据资源的名称得到其绝对路径,从函数里面可以看出,Resources类中的getResource函数 w397090770 11年前 (2013-09-25) 6414℃ 0评论4喜欢
前两篇文章,《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 和 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 分别介绍了两种方法读取加盐之后的 HBase 表。本文将介绍如何在 MapReduce 读取加盐之后的表。在 MapReduce 中也可以使用 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 文章里面的 SaltRangeTableInputForm w397090770 5年前 (2019-02-27) 2877℃ 0评论6喜欢
《Learning Spark, 2nd Edition》这本书是由 O'Reilly Media 出版社于2020年7月出版的,作者包括 Jules S. Damji, Brooke Wenig, Tathagata Das, Denny Lee。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书介绍第二版已更新包含了 Spark 3.0 的一些东西,本书向数据工程师和数据科学家展示了 Spark 中结构化和统一 w397090770 4年前 (2020-09-03) 2420℃ 0评论9喜欢
版本升级[code lang="bash"]//更新软件源,最后会读取软件包列表sudo apt-get update sudo update-manager -c -d[/code]然后选择 upgrade普通升级[code lang="bash"]sudo apt-get updatesudo apt-get upgrade[/code]升级单一软件[code lang="bash"]sudo apt-get updatesudo apt-get upgrade package_name_your_want_to_upgrade[/code]全部升级[code lang="bash"]//更新所 w397090770 11年前 (2013-07-03) 18675℃ 0评论1喜欢
《Get Programming with Scala》于2021年7月由 Manning 出版,ISBN 为 9781617295270 全书共 560 页。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop图书介绍The perfect starting point for your journey into Scala and functional programming.In Get Programming in Scala you will learn:Object-oriented principles in ScalaExpress program designs in fun w397090770 3年前 (2021-08-30) 313℃ 0评论3喜欢
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》 本文在上篇文章(《Kafka设计解析:Kafka High Availability(上)》)基础上,更加深入讲解了Kafka的HA机制,主要阐述了HA相关各种 w397090770 9年前 (2015-06-04) 4477℃ 0评论6喜欢