哎哟~404了~休息一下,下面的文章你可能很感兴趣:
我们知道,电脑里面的10000的数阶乘结果肯定是不能用int类型存储的,也就是说,平常的方法是不能来求得这个结果的。下面,我介绍一些用向量来模拟这个算法,其中向量里面的每一位都是代表一个数。[code lang="CPP"]#include <iostream>#include <vector>using namespace std;//就是n的阶乘void calculate(int n){ vector<int> v w397090770 11年前 (2013-03-31) 3824℃ 0评论3喜欢
课程讲师:Cloudy 课程分类:Java 适合人群:初级 课时数量:8课时 用到技术:Zookeeper、Web界面监控 涉及项目:案例实战 此视频百度网盘免费下载。本站所有下载资源收集于网络,只做学习和交流使用,版权归原作者所有,若为付费视频,请在下载后24小时之内自觉删除,若作商业用途,请购 w397090770 9年前 (2015-04-18) 34721℃ 2评论57喜欢
Apache Kafka 0.10.2.0正式发布,此版本供修复超过200个bugs,合并超过500个 PR。本版本添加了一下的新功能: 1、支持session windows,参见KAFKA-3452 2、提供ProcessorContext中低层次Metrics的访问,参见KAFKA-3537 3、不用配置文件的情况下支持为 Kafka clients JAAS配置,参见KAFKA-4259 4、为Kafka Streams提供全局Table支持,参见KAFKA-4490 w397090770 7年前 (2017-02-23) 2450℃ 0评论1喜欢
《Apache Kafka编程入门指南:Producer篇》 《Apache Kafka编程入门指南:设置分区数和复制因子》 Apache Kafka编程入门指南:Consumer篇 在前面的例子(《Apache Kafka编程入门指南:Producer篇》)中,我们学习了如何编写简单的Kafka Producer程序。在那个例子中,在如果需要发送的topic不存在,Producer将会创建它。我们都知 w397090770 8年前 (2016-02-06) 7473℃ 0评论6喜欢
导读:本文的主题是Presto高性能引擎在美图的实践,首先将介绍美图在处理ad-hoc场景下为何选择Presto,其次我们如何通过外部组件对Presto高可用与稳定性的增强。然后介绍在美图业务中如何做到合理与高效的利用集群资源,最后如何利用Presto应用于部分离线计算场景中。使大家了解Presto引擎的优缺点,适合的使用场景,以及在美图 w397090770 3年前 (2021-09-01) 660℃ 0评论1喜欢
Spark Release 1.0.2于2014年8月5日发布,Spark 1.0.2 is a maintenance release with bug fixes. This release is based on the branch-1.0 maintenance branch of Spark. We recommend all 1.0.x users to upgrade to this stable release. Contributions to this release came from 30 developers.如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopYou can download Spark 1.0.2 as w397090770 10年前 (2014-08-06) 5791℃ 2评论4喜欢
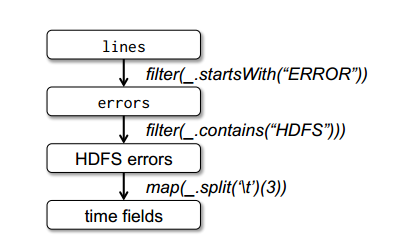
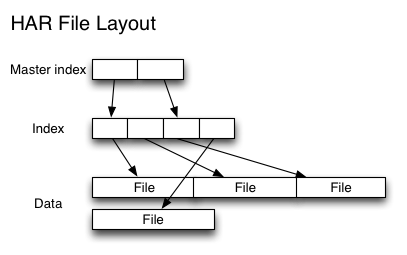
先来了解一下Hadoop中何为小文件:小文件指的是那些文件大小要比HDFS的块大小(在Hadoop1.x的时候默认块大小64M,可以通过dfs.blocksize来设置;但是到了Hadoop 2.x的时候默认块大小为128MB了,可以通过dfs.block.size设置)小的多的文件。如果在HDFS中存储小文件,那么在HDFS中肯定会含有许许多多这样的小文件(不然就不会用hadoop了)。而HDFS的 w397090770 10年前 (2014-03-17) 15261℃ 1评论10喜欢
2016中国架构师大会大数据专场于10月27日在京进行,大数据专场有来自搜狐、优酷介绍其视频个性化推荐架构设计;也有来自饿了么的实时架构演变;有来自Qunar、宜信以及广发证券再金融中应用大数据的架构设计;也有华为CarbonData的介绍,干货十足!值得一看。主要涉及如下主题: 10月27 w397090770 8年前 (2016-11-03) 4630℃ 0评论9喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第五篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 zz~~ 8年前 (2016-10-01) 3816℃ 0评论6喜欢
基于社区开发者们的观察,绝大多数的Spark应用程序的瓶颈不在于I/O或者网络,而在于CPU和内存。基于这个事实,开发者们发起了Tungsten项目,而Spark 1.5是Tungsten项目的第一阶段。Tungsten项目主要集中在三个方面,于此来提高Spark应用程序的内存和CPU的效率,使得性能能够接近硬件的限制。Tungsten项目的三个阶段内存管理和二 w397090770 9年前 (2015-09-09) 7291℃ 0评论5喜欢
假设现在的分支名称为 oldName,想要修改为 newName如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本地分支重命名这种情况是你的代码还没有推送到远程,分支只是在本地存在,那直接执行下面的命令即可:[code lang="bash"]git branch -m oldName newName[/code]远程分支重命名 如果你的分支已经推 w397090770 7年前 (2017-03-02) 675℃ 0评论1喜欢
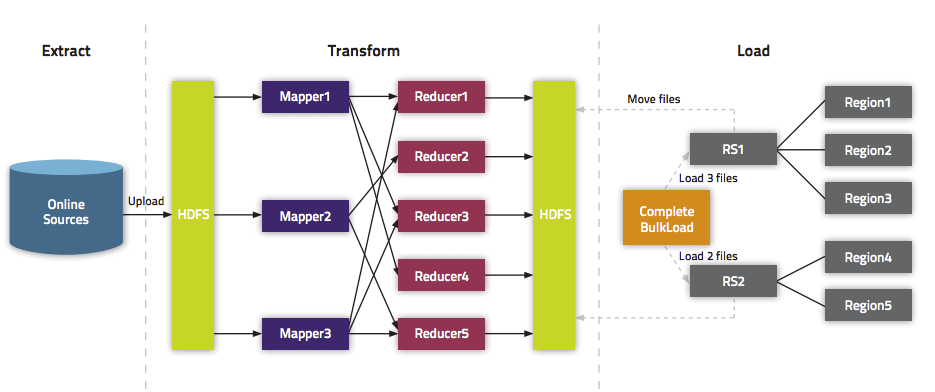
我们在《通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]》文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入数据到Hbase中的方法。这里将介绍两种方式:第一种使用Put普通的方法来倒数;第二种使用Bulk Load API。关于为啥需要使用Bulk Load本文就不介绍,更多的请参见《通过BulkLoad快 w397090770 7年前 (2017-02-28) 14980℃ 1评论40喜欢
就在前几天,Apache Hadoop 3.0.0-beta1 正式发布了,这是3.0.0的第一个 beta 版本。本版本基于 3.0.0-alpha4 版本进行了Bug修复、性能提升以及其他一些加强。好消息是,这个版本之后会正式发行 Apache Hadoop 3.3.0 GA(General Availability,正式发布的版本)版本,这意味着我们就可以正式在线上使用 Hadoop 3.0.0 了!目前预计 Apache Hadoop 3.3.0 GA 将会在 201 w397090770 7年前 (2017-10-11) 2194℃ 0评论15喜欢
7.1 TF-IDF TF-IDF是一种特征向量化方法,这种方法多用于文本挖掘,通过算法可以反应出词在语料库中某个文档中的重要性。文档中词记为t,文档记为d , 语料库记为D . 词频TF(t,d) 是词t 在文档d 中出现的次数。文档频次DF(t,D) 是语料库中包括词t的文档数。如果使用词在文档中出现的频次表示词的重要程度,那么很容易取出反例, w397090770 8年前 (2016-03-27) 6022℃ 0评论6喜欢
如果你需要将RDD写入到Mysql等关系型数据库,请参见《Spark RDD写入RMDB(Mysql)方法二》和《Spark将计算结果写入到Mysql中》文章。 Spark的功能是非常强大,在本博客的文章中,我们讨论了《Spark和Hbase整合》、《Spark和Flume-ng整合》以及《和Hive的整合》。今天我们的主题是聊聊Spark和Mysql的组合开发。如果想及时了解Spark、Had w397090770 10年前 (2014-09-10) 38581℃ 7评论32喜欢
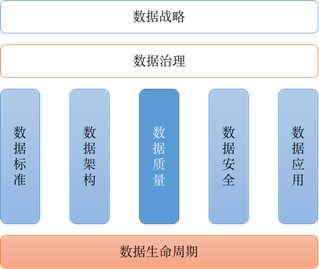
大数据平台的核心理念是构建于业务之上,用数据为业务创造价值。大数据平台的搭建之初,优先满足业务的使用需求,数据质量往往是被忽视的一环。但随着业务的逐渐稳定,数据质量越来越被人们所重视。千里之堤,溃于蚁穴,糟糕的数据质量往往就会带来低效的数据开发,不准确的数据分析,最终导致错误的业务决策。而 zz~~ 3年前 (2021-09-24) 176℃ 0评论2喜欢
这几天由于项目的需要,需要将Flume收集到的日志插入到Hbase中,有人说,这不很简单么?Flume里面自带了Hbase sink,可以直接调用啊,还用说么?是的,我在本博客的《Flume-1.4.0和Hbase-0.96.0整合》文章中就提到如何用Flume和Hbase整合,从文章中就看出整个过程不太复杂,直接做相应的配置就行了。那么为什么今天还要特意提一下Flum w397090770 10年前 (2014-01-27) 5122℃ 1评论1喜欢
如果我们需要通过编程的方式来获取到Kafka中某个Topic的所有分区、副本、每个分区的Leader(所在机器及其端口等信息),所有分区副本所在机器的信息和ISR机器的信息等(特别是在使用Kafka的Simple API来编写SimpleConsumer的情况)。这一切可以通过发送TopicMetadataRequest请求到Kafka Server中获取。代码片段如下所示:[code lang="scala"]de w397090770 8年前 (2016-05-09) 8155℃ 0评论4喜欢
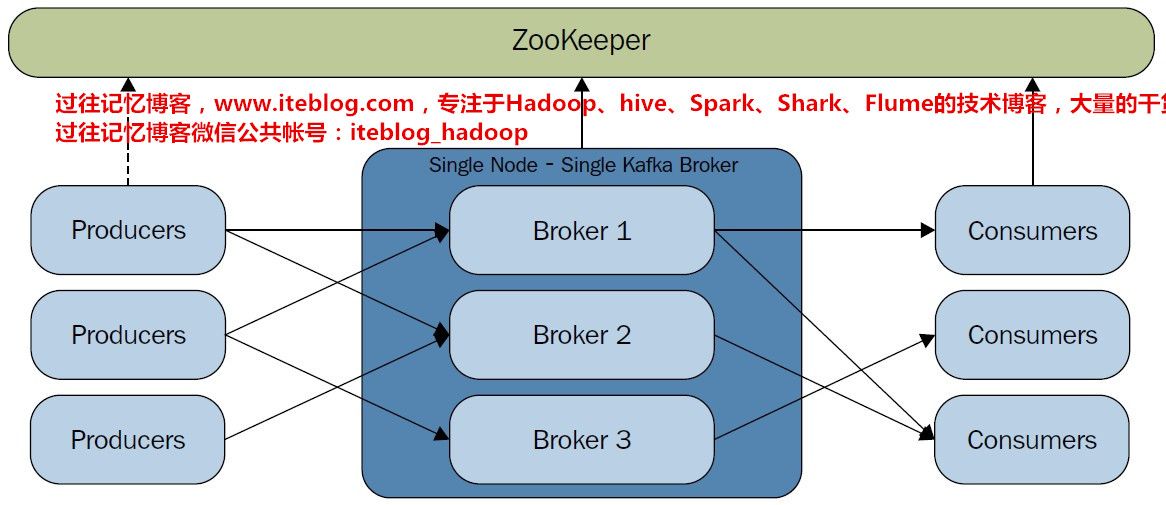
Kafka Cluster模式最大的优点:可扩展性和容错性,下图是关于Kafka集群的结构图:Kafka Broker个数决定因素 磁盘容量:首先考虑的是所需保存的消息所占用的总磁盘容量和每个broker所能提供的磁盘空间。如果Kafka集群需要保留 10 TB数据,单个broker能存储 2 TB,那么我们需要的最小Kafka集群大小 5 个broker。此外,如果启用副 w397090770 8年前 (2016-11-18) 13540℃ 0评论28喜欢
Apache CarbonData 是一种新的融合存储解决方案,利用先进的列式存储,索引,压缩和编码技术提高计算效率,从而加快查询速度,其查询速度比 PetaBytes 数据快一个数量级。 鉴于目前使用 Apache CarbonData 用户越来越多,其中就包含了大量的中国用户,这些中国用户可能有很多人英文不是特别好,或者没那么多时间去看英文文档。基于 w397090770 6年前 (2018-05-09) 10774℃ 0评论22喜欢
大家期待已久的Apache Flink 1.2.0今天终于正式发布了。本版本一共解决了650个issues,详细的列表参见这里。Apache Flink 1.2.0是1.x.y系列的第三个主要版本;其API和其他1.x.y版本使用@Public标注的API是兼容的,推荐所有用户升级到此版本。更多关于Apache Flink 1.2.0新功能可以参见Apache Flink 1.2.0新功能概述如果想及时了解Spark、Hadoop或者H w397090770 7年前 (2017-02-07) 1766℃ 6喜欢
Spark Summit East 2016:视频,PPT Spark Summit East 2016会议于2016年2月16日至2月18日在美国纽约进行。总体来说,Spark Summit一年比一年火,单看纽约的峰会中,规模已从900人增加到500个公司的1300人,更吸引到更多大型公司的分享,包括Bloomberg、Capital One、Novartis、Comcast等公司。而在这次会议上,Databricks还发布了两款产品——Commu w397090770 8年前 (2016-02-27) 6144℃ 0评论9喜欢
本书于2017-08由Packt Publishing出版,作者David Blomquist, Tomasz Janiszewski,全书546页。通过本书你将学到以下知识Set up Mesos on different operating systemsUse the Marathon and Chronos frameworks to manage multiple applicationsWork with Mesos and DockerIntegrate Mesos with Spark and other big data frameworksUse networking features in Mesos for effective communication between containersConfig zz~~ 7年前 (2017-08-17) 2356℃ 0评论8喜欢
本文转载自:http://shiyanjun.cn/archives/744.html 该论文来自Berkeley实验室,英文标题为:Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing。摘要 本文提出了分布式内存抽象的概念——弹性分布式数据集(RDD,Resilient Distributed Datasets),它具备像MapReduce等数据流模型的容错特性,并且允许开发人员 w397090770 10年前 (2014-10-30) 13650℃ 0评论7喜欢
有多个地方需要使用Java client: 1、在存在的集群中执行标准的index, get, delete和search 2、在集群中执行管理任务 3、当你要运行嵌套在你的应用程序中的Elasticsearch的时候或者当你要运行单元测试或者集合测试的时候,启动所有节点获得一个Client是非常容易的,最通用的步骤如下所示: 1、创建一个嵌套的 zz~~ 8年前 (2016-10-02) 1113℃ 0评论7喜欢
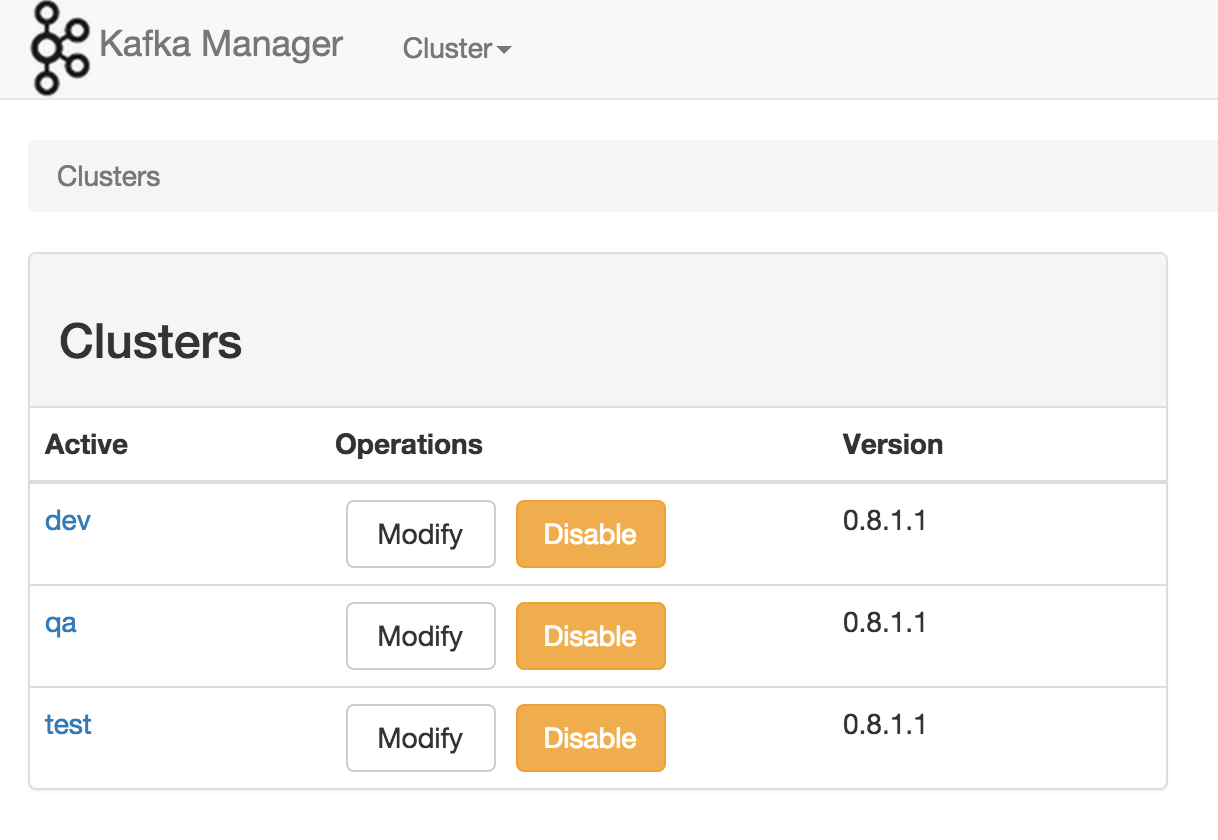
《Apache Kafka监控之Kafka Web Console》《Apache Kafka监控之KafkaOffsetMonitor》《雅虎开源的Kafka集群管理器(Kafka Manager)》Kafka在雅虎内部被很多团队使用,媒体团队用它做实时分析流水线,可以处理高达20Gbps(压缩数据)的峰值带宽。为了简化开发者和服务工程师维护Kafka集群的工作,构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka M w397090770 9年前 (2015-02-04) 22065℃ 0评论14喜欢
终于到最后一篇了,我们在前面两篇文章中《一条 SQL 在 Apache Spark 之旅(上)》 和 《一条 SQL 在 Apache Spark 之旅(中)》 介绍了 Spark SQL 之旅的 SQL 解析、逻辑计划绑定、逻辑计划优化以及物理计划生成阶段,本文我们将继续接上文,介绍 Spark SQL 的全阶段代码生成以及最后的执行过程。全阶段代码生成阶段 - WholeStageCodegen前面 w397090770 5年前 (2019-06-19) 8669℃ 0评论17喜欢
关于如何编译Flume-ng 1.4.0可以参见本博客的《基于Hadoop-2.2.0编译flume-ng 1.4.0及错误解决》 在编译Flume-0.9.4源码的时候出现了以下的错误信息:[code lang="JAVA"][INFO] ------------------------------------------------------------------------[INFO] Reactor Summary:[INFO][INFO] Flume ............................................. SUCCESS [0.003s][INFO] Flume Core ............ w397090770 10年前 (2014-01-22) 10675℃ 2评论2喜欢
题目描述:将一个长度超过100位数字的十进制非负整数转换为二进制数输出。输入:多组数据,每行为一个长度不超过30位的十进制非负整数。(注意是10进制数字的个数可能有30个,而非30bits的整数)输出:每行输出对应的二进制数。样例输入:0138样例输出:01111000分析:这个数不应该存储到一个int类型变量里面去 w397090770 11年前 (2013-04-03) 5825℃ 0评论5喜欢
引言:十年沉淀、全球宽表排名第一、阿里云首发云Cassandra服务ApsaraDB for Cassandra是基于开源Apache Cassandra,融合阿里云数据库DBaaS能力的分布式NoSQL数据库。Cassandra已有10年+的沉淀,基于Amazon DynamoDB的分布式设计和 Google Bigtable 的数据模型。具备诸多优异特性:采用分布式架构、无中心、支持多活、弹性可扩展、高可用、容错、一 w397090770 5年前 (2019-09-05) 2111℃ 0评论4喜欢













![[电子书]Apache Mesos Cookbook PDF下载](https://www.iteblog.com/pic/books/Apache_Mesos_Cookbook_iteblog.png)