哎哟~404了~休息一下,下面的文章你可能很感兴趣:
本书作者Venkat Ankam,由Packt Publishing出版社在2016年09月发行,全书供326页。本书基于Spark 2.0和Hadoop 2.7版本介绍,是适合数据分析师和数据科学家的参考手册,当然也适合那些想入门的人。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节[code lang="bash"]Chapter 1: Big Data Analytics at a 10 zz~~ 8年前 (2016-11-21) 4575℃ 0评论6喜欢
这个文档只是简单的介绍如何快速地使用Spark。在下面的介绍中我将介绍如何通过Spark的交互式shell来使用API。Basics Spark shell提供一种简单的方式来学习它的API,同时也提供强大的方式来交互式地分析数据。Spark shell支持Scala和Python。可以通过以下方式进入到Spark shell中。[code lang="JAVA"]# 本文原文地址:https://www.iteblog.com/ar w397090770 10年前 (2014-06-10) 77031℃ 26评论156喜欢
导读:本文的主题是Presto高性能引擎在美图的实践,首先将介绍美图在处理ad-hoc场景下为何选择Presto,其次我们如何通过外部组件对Presto高可用与稳定性的增强。然后介绍在美图业务中如何做到合理与高效的利用集群资源,最后如何利用Presto应用于部分离线计算场景中。使大家了解Presto引擎的优缺点,适合的使用场景,以及在美图 w397090770 3年前 (2021-09-01) 660℃ 0评论1喜欢
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。详情参见《CarbonData:华为开发并支持Hadoop的列式文件格式》,本文是单机模式下使用CarbonData的,如果你需要集群模 w397090770 8年前 (2016-07-01) 8319℃ 3评论6喜欢
大年初二Apache CarbonData迎来了第四个稳定版本CarbonData 1.0.0。CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。CarbonData 1.0.0版本,一共带来了80+ 个新特性,并且有100+ 个bugfi w397090770 7年前 (2017-01-29) 2701℃ 0评论6喜欢
在 HDFS 中,DataNode 将数据块存储到本地文件系统目录中,具体的目录可以通过配置 hdfs-site.xml 里面的 dfs.datanode.data.dir 参数。在典型的安装配置中,一般都会配置多个目录,并且把这些目录分别配置到不同的设备上,比如分别配置到不同的HDD(HDD的全称是Hard Disk Drive)和SSD(全称Solid State Drives,就是我们熟悉的固态硬盘)上。当 w397090770 6年前 (2018-03-28) 5137℃ 3评论24喜欢
Flink 是一种非常复杂的框架,它提供了多种调整其执行的方法。本文将介绍四种不同的方法来提升你的 Flink 应用程序的性能。使用 Flink Tuples当你使用类似于 groupBy, join, 或者 keyBy 算子时,Flink 提供了多种用于在你的数据集上选择 key 的方法。你可以使用 key 选择函数,如下:[code lang="java"]// Join movies and ratings datasetsmovies.join w397090770 6年前 (2017-12-10) 5306℃ 0评论16喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop尽管 IntelliJ IDEA 2020.2 版本发布不久,但我们已经带着一个改进版 IntelliJ IDEA 回来了。这个版本主要对 2020.2 版本进行了一些的调整,帮助您更加专注和高效。重要更新如下: 修复了 Lombok 插件被异常阻止的问题 经调试后,MacBook Touch Bar 不再 w397090770 4年前 (2020-08-25) 637℃ 0评论1喜欢
本书将为您简要介绍ElasticSearch的基础知识以及Elasticsearch 5的新功能。通过本书将学习到Elasticsearch的基本功能和高级功能,例如查询,索引,搜索和修改数据。本书还介绍了一些高级知识,包括聚合,索引控制,分片,复制和聚类。中间部分介绍了ElasticSearch集群相关的知识,包括备份、监控、恢复等。读完本书,您将掌握Elastics zz~~ 7年前 (2017-02-28) 4936℃ 0评论13喜欢
在编写程序的时候,很多时候都需要检查输入的参数是否符合我们的需要,比如人的年龄需要大于0,名字不能为空;如果不符合这两个要求,我们将认为这个对象是不合法的,这时候我们需要编写判断这些参数是否合法的函数,我们可能这样写:[code lang="JAVA"]package com.wyp;import java.util.ArrayList;import java.util.List;/** * Crea w397090770 11年前 (2013-07-24) 6004℃ 4评论2喜欢
Apache Hive 1.0.1 和 1.1.1两个版本同时发布,他们分别是基于Hive 1.0.0和Hive 1.1.0,这两个版本都同时修复可同一个Bug:LDAP授权provider的漏洞。如果用户在HiveServer2里面使用到LDAP授权模式(hive.server2.authentication=LDAP),并且LDAP使用简单地未认证模式,或者是匿名绑定(anonymous bind),在这种情况下未得到合理授权的用户将得到认证(authe w397090770 9年前 (2015-05-25) 4941℃ 0评论3喜欢
AbstractMapBasedMultimap源码分析:AbstractMapBasedMultimap是Multimap接口的基础实现类,实现了Multimap中的绝大部分方法,其中有许多的方法还是靠实现类的具体实现,比如size()方法,其计算方法在不同实现是不一样的。同时,AbstractMapBasedMultimap类也定义了自己的一些方法,比如createCollection()。AbstractMapBasedMultimap类中主要存在以下两个成员 w397090770 11年前 (2013-09-13) 3992℃ 1喜欢
Hadoop分布式文件系统实现了一个和POSIX系统类似的文件和目录的权限模型。每个文件和目录有一个所有者(owner)和一个组(group)。文件或目录对其所有者、同组的其他用户以及所有其他用户分别有着不同的权限。对文件而言,当读取这个文件时需要有r权限,当写入或者追加到文件时需要有w权限。对目录而言,当列出目录内容 w397090770 8年前 (2016-03-21) 7788℃ 9喜欢
2010年,Facebook 的工程师在 ICDC(IEEE International Conference on Data Engineering) 发表了一篇 《RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems》 的论文,介绍了其为基于 MapReduce 的数据仓库设计的高效存储结构,这就是我们熟知的 RCFile(Record Columnar File)。下面介绍 RCFile 的一些诞生背景和设计。背景早在2010 w397090770 4年前 (2020-06-16) 1221℃ 0评论7喜欢
Databricks 开源的 Apache Spark 对于分布式数据处理来说是一个伟大的进步。我们在使用 Spark 时发现了很多可圈可点之处,我们在此与大家分享一下我们在简化Spark使用和编程以及加快Spark在生产环境落地上做的一些努力。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop一个Spark Streaming读取Kafka w397090770 6年前 (2018-02-28) 6569℃ 0评论13喜欢
本博客近日将对Spark 1.2.1 RDD中所有的函数进行讲解,主要包括函数的解释,实例以及注意事项,每日一篇请关注。以下是将要介绍的函数,按照字母的先后顺序进行介绍,可以点的说明已经发布了。 aggregate、aggregateByKey、cache、cartesian、checkpoint、coalesce、cogroup groupWith collect, toArraycollectAsMap combineByKey computecontext, spar w397090770 9年前 (2015-03-08) 7233℃ 0评论6喜欢
在 《如何在Spark、MapReduce和Flink程序里面指定JAVA_HOME》文章中我简单地介绍了如何自己指定 JAVA_HOME 。有些人可能注意到了,上面设置的方法有个前提就是要求集群的所有节点的同一路径下都安装部署好了 JDK,这样才没问题。但是在现实情况下,我们需要的 JDK 版本可能并没有在集群上安装,这个时候咋办?是不是就没办法呢?答案 w397090770 6年前 (2017-12-05) 2950℃ 0评论18喜欢
本书作者:Hari Shreedharan,由O'Reilly Media出版社于2014年09月出版,全书共238页。 如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节[code lang="bash"]Chapter 1: Apache Hadoop and Apache HBase:An IntroductionChapter 2: Streaming Data Using Apache FlumeChapter 3:SourcesChapter 4: ChannelsChapter 5: SinksChapter 6: Inter w397090770 9年前 (2015-08-25) 4084℃ 0评论8喜欢
Splitter:在Guava官方的解释为:Extracts non-overlapping substrings from an input string, typically by recognizing appearances of a separator sequence. This separator can be specified as a single character, fixed string, regular expression or CharMatcher instance. Or, instead of using a separator at all, a splitter can extract adjacent substrings of a given fixed length. w397090770 11年前 (2013-09-09) 6920℃ 1评论0喜欢
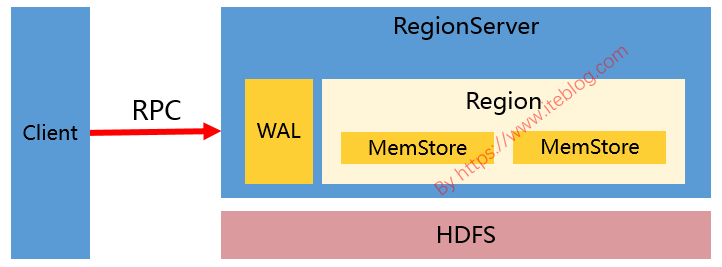
接触过 HBase 的同学应该对 HBase 写数据的过程比较熟悉(不熟悉也没关系)。HBase 写数据(比如 put、delete)的时候,都是写 WAL(假设 WAL 没有被关闭) ,然后将数据写到一个称为 MemStore 的内存结构里面的,如下图:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop但是,MemStore 毕竟是内存里 w397090770 5年前 (2019-01-13) 7045℃ 4评论32喜欢
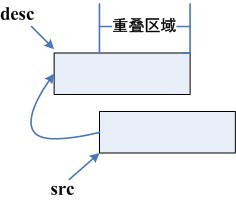
在/archives/227主要介绍了memcpy函数的实现,并说明了memcpy函数的局限性。今天来介绍一下和memcpy函数功能类似的函数memmove。memmove函数和memcpy函数的原型为[code lang="CPP"]#include <string.h>void *memcpy(void *dest, const void *src, size_t n);void *memmove(void *dest, const void *src, size_t n);[/code]memmove英文介绍,里面很详细的介绍了memmove函数的 w397090770 11年前 (2013-04-08) 4518℃ 0评论0喜欢
默认情况下,Flume中的PollingPropertiesFileConfigurationProvider会每隔30秒去重新加载Flume agent的配置文件,如果监听到配置文件变化了,Flume会试图重新加载变化的配置文件。判断配置文件是否变化主要是基于文件的最后修改时间来的,代码片段如下:[code lang="java"]///////////////////////////////////////////////////////////////////// User: 过往记忆 w397090770 9年前 (2015-08-20) 6584℃ 0评论11喜欢
今天谈谈Guava类库中的Multisets数据结构,虽然它不怎么经常用,但是还是有必要对它进行探讨。我们知道Java类库中的Set不能存放相同的元素,且里面的元素是无顺序的;而List是能存放相同的元素,而且是有顺序的。而今天要谈的Multisets是能存放相同的元素,但是元素之间的顺序是无序的。从这里也可以看出,Multisets肯定不是实 w397090770 11年前 (2013-07-11) 4641℃ 0评论1喜欢
ElasticSearch是一个基于Lucene构建的开源的分布式搜索和分析引擎,具备高可靠性和扩展性。它允许你快速准实时存储,搜索和分析海量数据。它通常作为底层引擎/计算来驱动企业级复杂搜索特性和需求。 下面列举一些使用ElasticSearch的应用场景: 1、运行一个在线的网店,你允许客户能够去搜索你销售的商品。在这 w397090770 8年前 (2016-08-09) 2173℃ 0评论3喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 8月31日(13:30-17:30),杭州第 w397090770 10年前 (2014-09-01) 26251℃ 230评论16喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive的设计目的是为了那 w397090770 10年前 (2014-01-06) 15979℃ 2评论8喜欢
ZooKeeper 支持某些特定的四字命令(The Four Letter Words)与其进行交互。它们大多是查询命令,用来获取 ZooKeeper 服务的当前状态及相关信息。用户在客户端可以通过 telnet 或 nc 向 ZooKeeper 提交相应的命令。 ZooKeeper 常用四字命令主要如下: ZooKeeper四字命令功能描述conf3.3.0版本引入的。打印出服务相关配置的详细信息。cons3.3.0 w397090770 8年前 (2016-05-18) 4066℃ 0评论5喜欢
数据分析中将两个数据集进行 Join 操作是很常见的场景。我在 这篇 文章中介绍了 Spark 支持的五种 Join 策略,本文我将给大家介绍一下 Apache Spark 中支持的 Join 类型(Join Type)。目前 Apache Spark 3.0 版本中,一共支持以下七种 Join 类型:INNER JOINCROSS JOINLEFT OUTER JOINRIGHT OUTER JOINFULL OUTER JOINLEFT SEMI JOINLEFT ANTI JOIN在实现上 w397090770 4年前 (2020-10-25) 1409℃ 0评论6喜欢
本书书名全名:Learning Spark Streaming:Best Practices for Scaling and Optimizing Apache Spark,于2017-06由 O'Reilly Media出版,作者 Francois Garillot, Gerard Maas,全书300页。本文提供的是本书的预览版。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Understand how Spark Streaming fits in the big pictureLearn c zz~~ 7年前 (2017-10-18) 6359℃ 0评论20喜欢
通过使用易于理解的实例,本书将教你如何使用Spark Streaming构建实时应用程序。从安装和设置所需的环境开始,您将编写并执行第一个程序Spark Streaming。接下来将探讨Spark Streaming的架构和组件以及概述Spark公开的库/函数的。接下来,您将通过处理分布式日志文件的用例来了解有关Spark中的各种客户端API编码。然后,您将学习到各 w397090770 7年前 (2017-02-12) 3080℃ 0评论6喜欢

![[电子书]Big Data Analytics pdf下载](https://www.iteblog.com/pic/big-data-analytics-iteblog.jpg)





![[电子书]Mastering Elasticsearch 5.x - Third Edition PDF下载](https://www.iteblog.com/pic/elastic/Mastering_Elasticsearch_5.x-Third_Edition_iteblog.jpg)










![[电子书]Learning Spark Streaming PDF下载](https://www.iteblog.com/pic/books/Learning_Spark_Streaming_iteblog.jpg)
![[电子书]Learning Real-time Processing with Spark Streaming PDF下载](https://www.iteblog.com/pic/books/Learning_Real-time_Processing_with_Spark_Streaming-iteblog.jpg)