哎哟~404了~休息一下,下面的文章你可能很感兴趣:
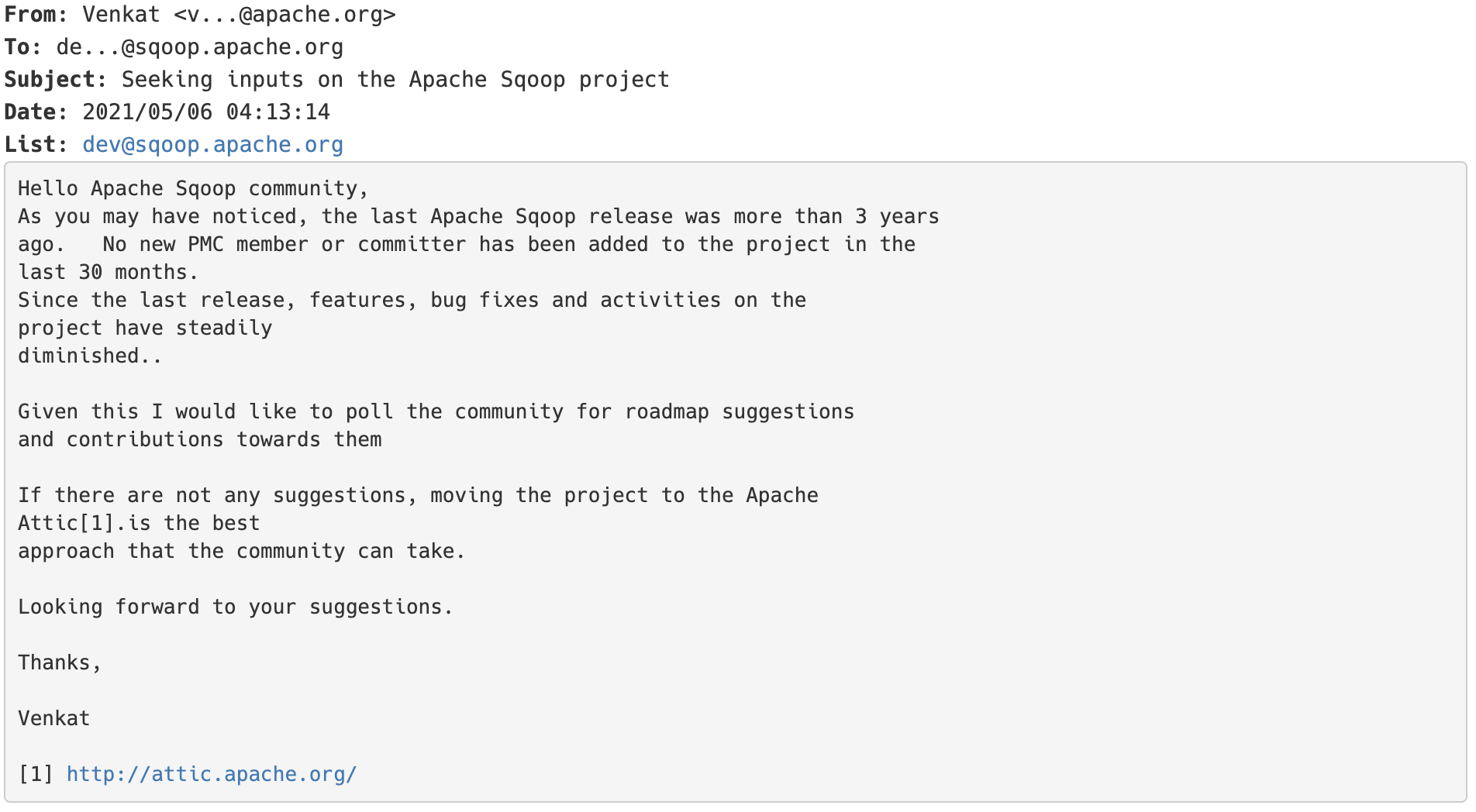
2021年05月06日,Apache Sqoop 的 PMC venkatrangan 给 Sqoop 项目的 dev 邮件列表发送了一篇名为《Seeking inputs on the Apache Sqoop project》的邮件:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据从邮件内容可以看出,Apache Sqoop 最后一次 release 的时间是三年前,最近30个月没有任何新的 PMC 和 committer 加入到 w397090770 3年前 (2021-06-27) 727℃ 0评论2喜欢
背景相信经常使用 Spark 的同学肯定知道 Spark 支持将作业的 event log 保存到持久化设备。默认这个功能是关闭的,不过我们可以通过 spark.eventLog.enabled 参数来启用这个功能,并且通过 spark.eventLog.dir 参数来指定 event log 保存的地方,可以是本地目录或者 HDFS 上的目录,不过一般我们都会将它设置成 HDFS 上的一个目录。但是这个功能 w397090770 4年前 (2020-03-09) 2188℃ 0评论8喜欢
当前 Spark 计算引擎能够利用一些统计信息选择合适的 Join 策略(关于 Spark 支持的 Join 策略可以参见每个 Spark 工程师都应该知道的五种 Join 策略),但是由于各种原因,比如统计信息缺失、统计信息不准确等原因,Spark 给我们选择的 Join 策略不是正确的,这时候我们就可以人为“干涉”,Spark 从 2.2.0 版本开始(参见SPARK-16475),支 w397090770 4年前 (2020-09-15) 3196℃ 0评论3喜欢
随着我们使用 Docker 的次数越来越多,我们电脑里面可能已经存在很多 Docker 镜像,大量的镜像会占据大量的存储空间,所有很有必要清理一些不需要的镜像。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop镜像的删除在删除镜像之前,我们可以看下系统里面都有哪些镜像:[code lang="bash"][ite w397090770 4年前 (2020-04-14) 464℃ 0评论1喜欢
ClickHouse作为一款开源列式数据库管理系统(DBMS)近年来备受关注,主要用于数据分析(OLAP)领域。作者根据以往经验和遇到的问题,总结出一些基本的开发和使用规范,以供使用者参考。随着公司业务数据量日益增长,数据处理场景日趋复杂,急需一种具有高可用性和高性能的数据库来支持业务发展,ClickHouse是俄罗斯的搜索公 w397090770 2年前 (2022-03-10) 1496℃ 0评论0喜欢
越来越多的公司采用流处理,并将现有的批处理应用迁移到流处理,或者对新的用例采用流处理实现的解决方案。其中许多应用集中在流数据分析上,分析的数据流来自各种源,例如数据库事务、点击、传感器测量或 IoT 设备。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Flink 非常 w397090770 7年前 (2017-07-20) 3475℃ 0评论16喜欢
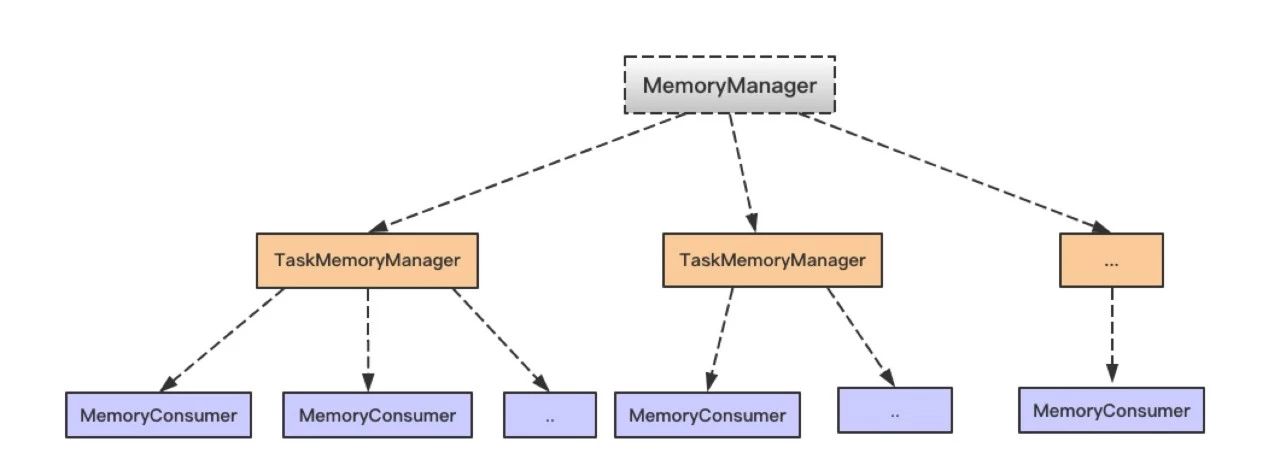
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段。那么在 Spark Shuffle 中具体是哪些地方会使用比较多的内存而有可能导致 OOM 呢? 为此,本文将围绕以上问题梳理 Spark 内存管理和 Shuffle 过程中与内存使用相关的知识;然后,简要分析下在 Spark Shuffle 中有可能导致 OOM w397090770 7年前 (2017-01-17) 778℃ 0评论1喜欢
桔妹导读:滴滴ElasticSearch平台承接了公司内部所有使用ElasticSearch的业务,包括核心搜索、RDS从库、日志检索、安全数据分析、指标数据分析等等。平台规模达到了3000+节点,5PB 的数据存储,超过万亿条数据。平台写入的峰值写入TPS达到了2000w/s,每天近 10 亿次检索查询。为了承接这么大的体量和丰富的使用场景,滴滴ElasticSearch需要 w397090770 4年前 (2020-08-19) 1324℃ 0评论6喜欢
就在前几天,Apache Hadoop 3.0.0-beta1 正式发布了,这是3.0.0的第一个 beta 版本。本版本基于 3.0.0-alpha4 版本进行了Bug修复、性能提升以及其他一些加强。好消息是,这个版本之后会正式发行 Apache Hadoop 3.3.0 GA(General Availability,正式发布的版本)版本,这意味着我们就可以正式在线上使用 Hadoop 3.0.0 了!目前预计 Apache Hadoop 3.3.0 GA 将会在 201 w397090770 7年前 (2017-10-11) 2194℃ 0评论15喜欢
ZooKeeper: Distributed Process Coordination于2013年11月出版,全书共238页。 self.location='http://books.iteblog.com/zookeeper'; w397090770 9年前 (2015-08-25) 1425℃ 1评论4喜欢
我们在 前面的文章文章中介绍了 Docker 默认是从 https://hub.docker.com/仓库下载镜像的,由于这个网址是国外的,所以在下载镜像的时候很可能会非常慢,所以大家应该想到 Docker 是否像 Maven 仓库一样也有一些国内的 Docker 镜像库呢?答案是肯定的。截止到本文撰写的时候,下面几个国内 Docker 镜像地址是可用的:网易 Docker 镜像库:h w397090770 4年前 (2020-02-03) 10546℃ 0评论4喜欢
我们在这篇文章简单介绍了 Apache Cassandra 是什么,以及有什么值得关注的特性。本文将简单介绍 Apache Cassandra 的安装以及简单使用,可以帮助大家快速了解 Apache Cassandra。我们到 Apache Cassandra 的官方网站下载最新版本的 Cassandra,在本文写作时最新版本的 Cassandra 为 3.11.4。Apache Cassandra 可以在 Linux、Unix、Mac OS 以及 Windows 上进行安装 w397090770 5年前 (2019-04-07) 5007℃ 0评论8喜欢
Spark 1.6.1于2016年3月11日正式发布,此版本主要是维护版本,主要涉及稳定性修复,并不涉及到大的修改。推荐所有使用1.6.0的用户升级到此版本。 Spark 1.6.1主要修复的bug包括: 1、当写入数据到含有大量分区表时出现的OOM:SPARK-12546 2、实验性Dataset API的许多bug修复:SPARK-12478, SPARK-12696, SPARK-13101, SPARK-12932 w397090770 8年前 (2016-03-11) 3818℃ 0评论5喜欢
CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号。在本文中的CSV格式的数据就不是简单的逗号分割的),其文件以纯文本形式存储表格数据(数字和文本)。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字 w397090770 9年前 (2015-01-26) 9529℃ 0评论12喜欢
本文将介绍如何在Google Compute Engine(https://cloud.google.com/compute/)平台上基于 Hadoop 1 或者 Hadoop 2 自动部署 Flink 。借助 Google 的 bdutil(https://cloud.google.com/hadoop/bdutil) 工具可以启动一个集群并基于 Hadoop 部署 Flink 。根据下列步骤开始我们的Flink部署吧。要求(Prerequisites)安装(Google Cloud SDK) 请根据该指南了解如何安装 Google Cl w397090770 8年前 (2016-04-21) 1745℃ 0评论3喜欢
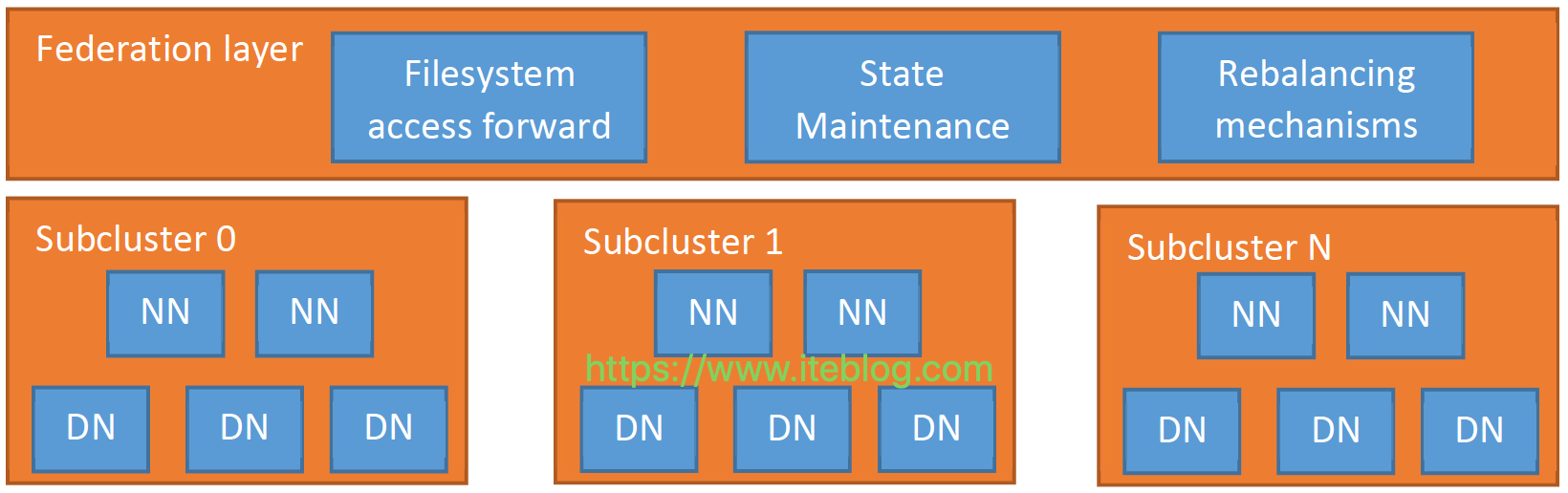
在 《Apache Hadoop 的 HDFS federation 前世今生(上)》 已经介绍了 Hadoop 2.9.0 版本之前 HDFS federation 存在的问题,那么为了解决这个问题,社区采取了什么措施呢?HDFS Router-based FederationViewFs 方案虽然可以很好的解决文件命名空间问题,但是它的实现有以下几个问题:ViewFS 是基于客户端实现的,需要用户在客户端进行相关的配置,那 w397090770 5年前 (2019-07-26) 1883℃ 0评论2喜欢
Spark Summit 2016 Europe会议于2016年10月25日至10月27日在布鲁塞尔进行。本次会议有上百位Speaker,来自业界顶级的公司。官方日程:https://spark-summit.org/eu-2016/schedule/。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料 w397090770 8年前 (2016-11-06) 3031℃ 0评论1喜欢
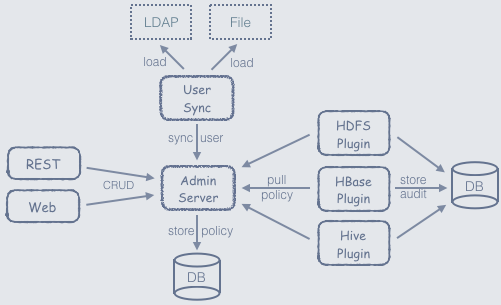
Apache Ranger 是一个用在 Hadoop 平台上并提供操作、监控、管理综合数据安全的框架。Ranger 的愿景是在 Apache Hadoop 生态系统中提供全面的安全性。 目前,Apache Ranger 支持以下 Apache 项目的细粒度授权和审计:Apache HadoopApache HiveApache HBaseApache StormApache KnoxApache SolrApache KafkaYARN对于上面那些受支持的 Hadoop 组件,Ranger 通过访 w397090770 6年前 (2018-01-07) 8795℃ 2评论15喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-07-15) 92341℃ 0评论162喜欢
Apache Flume 1.5.0 发布于5月22日正式发布(可以在http://flume.apache.org/download.html下载)。Flume是一个分布式、可靠和高可用的服务,用于收集、聚合以及移动大量日志数据,使用一个简单灵活的架构,就流数据模型。这是一个可靠、容错的服务。下面是Apache Flume-ng 1.5.0的Changelog:What's new in Apache Flume 1.5.0:May 22nd, 2014New Feature: Int w397090770 10年前 (2014-05-27) 6956℃ 1评论4喜欢
Apache Spark 和 Apache HBase 是两个使用比较广泛的大数据组件。很多场景需要使用 Spark 分析/查询 HBase 中的数据,而目前 Spark 内置是支持很多数据源的,其中就包括了 HBase,但是内置的读取数据源还是使用了 TableInputFormat 来读取 HBase 中的数据。这个 TableInputFormat 有一些缺点:一个 Task 里面只能启动一个 Scan 去 HBase 中读取数据;TableIn w397090770 5年前 (2019-04-02) 12900℃ 5评论17喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据过往记忆大数据备注:以下的我们均代表 Uber 的 Hadoop 运维团队。介绍随着 Uber 业务的增长,Uber 公司在 5 年内将 Apache Hadoop(本文简称为“Hadoop”)部署扩展到 21000 台以上的节点,以支持各种分析和机器学习用例。我们组建了一支拥有各 w397090770 3年前 (2021-08-22) 700℃ 0评论2喜欢
一、 问答题1、简单描述如何安装配置一个apache开源版hadoop,只描述即可,无需列出完整步骤,能列出步骤更好。1) 安装JDK并配置环境变量(/etc/profile)2) 关闭防火墙3) 配置hosts文件,方便hadoop通过主机名访问(/etc/hosts)4) 设置ssh免密码登录5) 解压缩hadoop安装包,并配置环境变量6) 修改配置文件($HADOOP_HOME/conf)hadoop-e w397090770 8年前 (2016-08-26) 7927℃ 0评论14喜欢
有赞数据平台从2017年上半年开始,逐步使用 SparkSQL 替代 Hive 执行离线任务,目前 SparkSQL 每天的运行作业数量5000个,占离线作业数目的55%,消耗的 cpu 资源占集群总资源的50%左右。本文介绍由 SparkSQL 替换 Hive 过程中碰到的问题以及处理经验和优化建议,包括以下方面的内容:有赞数据平台的整体架构。SparkSQL 在有赞的技术演进 w397090770 5年前 (2019-03-20) 8166℃ 5评论28喜欢
这个问题可能很多面试的人都遇到过,很多人可能想利用循环来判断,代码可能如下所示:[code lang="JAVA"] public static boolean isPowOfTwo(int n) { int temp = 0; for (int i = 1; ; i++) { temp = (int) Math.pow(2, i); if (temp >= n) break; } if (temp == n) return true; else return false; }[/code] w397090770 11年前 (2013-09-17) 11493℃ 6评论14喜欢
我博客服务器使用的OpenSSL是1.0.1e版本,之所以需要升级到OpenSSL 1.0.1t版本是因为1.0.1t版本以下存在一个严重的Bug:Padding oracle in AES-NI CBC MAC check (CVE-2016-2107),我们可以到这里查看我们的网站是否有这个问题。官方对这个漏洞的描述是:[code lang="bash"]Padding oracle in AES-NI CBC MAC check (CVE-2016-2107)=============================================== w397090770 8年前 (2016-08-06) 2801℃ 0评论2喜欢
上海Spark meetup第七次聚会将于2016年1月23日(周六)在上海市长宁区金钟路968号凌空SOHO 8号楼 进行。此次聚会由Intel联合携程举办。大会主题 1、开场/Opening Keynote: 张翼,携程大数据平台的负责人 个人介绍:本科和研究生都是浙江大学;2015年加入携程,推动携程大数据平台的演进;对大数据底层框架Hadoop,HIVE,Spark w397090770 8年前 (2016-01-28) 2491℃ 0评论6喜欢
众所周知,Kafka自己实现了一套二进制协议(binary protocol)用于各种功能的实现,比如发送消息,获取消息,提交位移以及创建topic等。具体协议规范参见:Kafka协议 这套协议的具体使用流程为:客户端创建对应协议的请求客户端发送请求给对应的brokerbroker处理请求,并发送response给客户端如果想及时了解Spark、Hadoop或者HBase w397090770 7年前 (2017-07-27) 361℃ 0评论0喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-15) 19316℃ 5评论10喜欢
最近使用ElasticSearch的时候遇到以下的异常[code land="bash"]2017-07-27 16:06:48.482 MessageHandler - message process error: java.lang.NoClassDefFoundError: Could not initialize class org.elasticsearch.common.xcontent.smile.SmileXContent at org.elasticsearch.common.xcontent.XContentFactory.contentBuilder(XContentFactory.java:124) ~[elasticsearch-2.3.4.jar:2.3.4] at org.elasticsearch.action.support.ToX w397090770 7年前 (2017-07-27) 8536℃ 0评论13喜欢











![Spark Summit 2016 Europe全部PPT下载[共75个]](https://www.iteblog.com/pic/iteblog.png)