哎哟~404了~休息一下,下面的文章你可能很感兴趣:
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 112.19.121.141 8123 高匿名 HTTP w397090770 9年前 (2015-05-15) 23772℃ 0评论5喜欢
在 Spark 或 Hive 中,我们可以使用 LATERAL VIEW + EXPLODE 或 POSEXPLODE 将 array 或者 map 里面的数据由行转成列,这个操作在数据分析里面很常见。比如我们有以下表:[code lang="sql"]CREATE TABLE `default`.`iteblog_explode` ( `id` INT, `items` ARRAY<STRING>)[/code]表里面的数据如下:[code lang="sql"]spark-sql> SELECT * FROM iteblog_explode;1 ["iteblog.co w397090770 2年前 (2022-08-08) 1614℃ 0评论6喜欢
一、首先到oracle的官网下载Berkeley db数据库源文件下载地址http://download.oracle.com/otn/berkeley-db/db-5.3.15.tar.gz二、下载之后的文件是一个打包好的文件,需要在命令行里面利用tar来解压(当然你也可以利用一些可视化工具来解压),步骤如下在命令行里面输入[code lang="CPP"] tar -zxvf db-5.3.15.tar.gz[/code]解压之后进入db-5.3.15目录有以下 w397090770 11年前 (2013-04-04) 3884℃ 0评论0喜欢
最近发现离线任务对一个增量Hive表的查询越来越慢,这引起了我的注意,我在cmd窗口手动执行count操作查询发现,速度确实很慢,才不到五千万的数据,居然需要300s,这显然是有问题的,我推测可能是有小文件。我去hdfs目录查看了一下该目录:发现确实有很多小文件,有480个小文件,我觉得我找到了问题所在,那么合并一 zz~~ 3年前 (2021-08-20) 1070℃ 0评论3喜欢
如果你经常写MapReduce作业,你肯定看到过以下的异常信息:[code lang="bash"]Application application_1409135750325_48141 failed 2 times due to AM Container forappattempt_1409135750325_48141_000002 exited with exitCode: 143 due to: Container[pid=4733,containerID=container_1409135750325_48141_02_000001] is running beyond physical memory limits.Current usage: 2.0 GB of 2 GB physical memory used; 6.0 GB of w397090770 7年前 (2016-12-29) 4046℃ 1评论11喜欢
本博客的《如何申请免费好用的HTTPS证书Let's Encrypt》和《在Nginx中使用Let's Encrypt免费证书配置HTTPS》文章分别介绍了如何申请Let's Encrypt的HTTPS证书和如何在nginx里面配置Let's Encrypt的HTTPS证书。但是Let's Encrypt HTTPS证书的有效期只有90天:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop到期之 w397090770 8年前 (2016-08-07) 1557℃ 0评论4喜欢
本资料来自2022年03月03日举办的 Alluxio Day 活动。分享议题 《Speed Up Uber’s Presto with Alluxio》,分享者 Liang Chen 和王北南。Uber 的 Liang Chen 和 Alluxio 的王北南将为大家呈现 Alluxio Local Cache 上线过程中遇到的实际问题和有趣的发现。他们的演讲涵盖了 Uber 的 Presto 团队如何解决 Alluxio 的本地缓存失效的问题。Liang Chen 还将分享他使用定 w397090770 2年前 (2022-03-07) 256℃ 0评论0喜欢
如果你想搭建伪分布式Hadoop平台,请参见本博客《在Fedora上部署Hadoop2.2.0伪分布式平台》 经过好多天的各种折腾,终于在几台电脑里面配置好了Hadoop2.2.0分布式系统,现在总结一下如何配置。 前提条件: (1)、首先在每台Linux电脑上面安装好JDK6或其以上版本,并设置好JAVA_HOME等,测试一下java、javac、jps等命令 w397090770 11年前 (2013-11-06) 21232℃ 6评论27喜欢
在Scala中存在case class,它其实就是一个普通的class。但是它又和普通的class略有区别,如下:1、初始化的时候可以不用new,当然你也可以加上,普通类一定需要加new;[code lang="scala"]scala> case class Iteblog(name:String)defined class Iteblogscala> val iteblog = Iteblog("iteblog_hadoop")iteblog: Iteblog = Iteblog(iteblog_hadoop)scala> val iteblog w397090770 9年前 (2015-09-18) 38360℃ 1评论71喜欢
2017 年初,我们开始探索 Presto 来解决 OLAP 用例,我们意识到了这个惊人的查询引擎的潜力。与 Apache Hive 相比,它最初是一种临时查询工具,供数据工程师和分析师以更快的方式运行 SQL 来构建查询原型。 当时很多内部仪表板都由 AWS-Redshift 提供支持,并将数据存储和计算耦合在一起。我们的数据呈指数级增长(每隔几天翻一番), w397090770 2年前 (2022-03-18) 298℃ 0评论0喜欢
一致性问题在介绍分布式系统一致性问题之前,我们先来了解一下副本概念。分布式系统会存在许多异常问题,比如机器宕机;为了提供高可用服务,一般会将数据或者服务部署到很多机器上,这些机器中的数据或服务可以称为副本。如果其中任何一台节点出现故障,用户可以访问其他机器上的数据或服务。由于副本的存在,如 w397090770 6年前 (2018-05-04) 4538℃ 0评论10喜欢
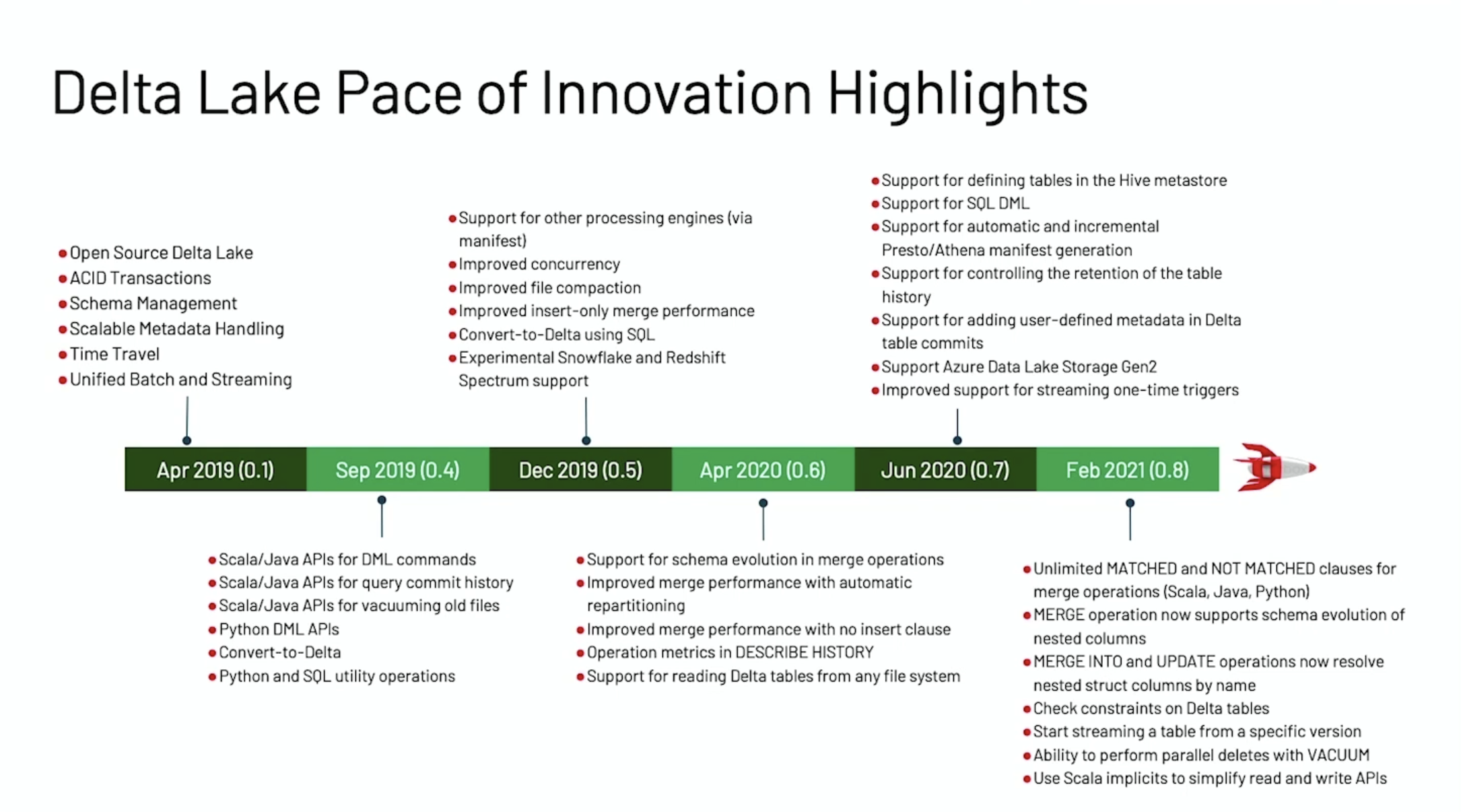
赶在 Data + AI Summit 2021 之前,Delta Lake 1.0.0 重磅发布,这个版本是基于 Spark 3.1 的,带来了许多新特性。本文将结合 Michael Armbrust 大牛在 Data + AI Summit 2021 的演讲《Announcing Delta Lake 1.0》来介绍 Delta Lake 1.0.0 版本的一些重要的新特性。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据Delta Lake 0.1 w397090770 3年前 (2021-05-27) 802℃ 0评论1喜欢
Spark 1.1.0中兼容大部分Hive特性,我们可以在Spark中使用Hive。但是默认的Spark发行版本并没有将Hive相关的依赖打包进spark-assembly-1.1.0-hadoop2.2.0.jar文件中,官方对此的说明是:Spark SQL also supports reading and writing data stored in Apache Hive. However, since Hive has a large number of dependencies, it is not included in the default Spark assembly 所以,如果你直 w397090770 10年前 (2014-09-26) 12675℃ 5评论9喜欢
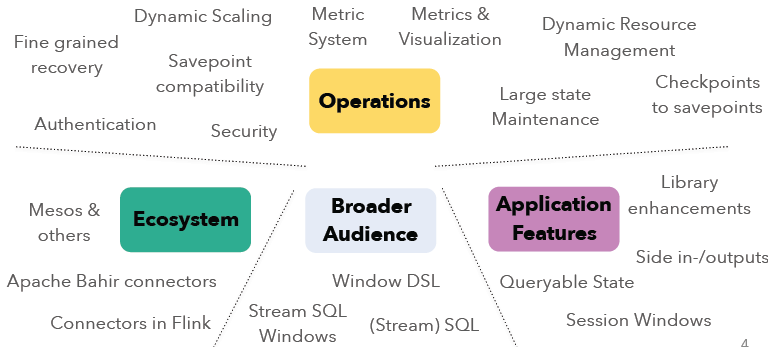
本文将概述即将发布的Apache Flink 1.2.0新功能。在Apache Flink 1.1+版本上,社区主要的集中点在操作性(Operations)、生态系统(Ecosystem)、更广泛的用户(Broader Audience)以及应用特性(Application Features)等方面的开发。各个模块的开发主要包括了如下的方向:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号 w397090770 7年前 (2016-12-18) 2724℃ 0评论4喜欢
2021年2月15日,Apache Flink 创建者、Ververica 公司(前身 DataArtisans)的联合创始人 Fabian Hueske 在 Twitter 宣布其已经从 Ververica 离职, 不过离职原因不得而知。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop另外,Ververica 公司原 COO Holger Temme 将接替 Kostas Tzoumas 成为新的 CEO。Kostas Tzoumas (原 CEO) w397090770 3年前 (2021-02-18) 991℃ 0评论3喜欢
2013年10月15号,Hadoop已经升级到2.2.0稳定版了,同时带来了很多新的特性,本人所在的公司经过一个月时间对Hadoop2.2.0的测试,在确保对业务没有影响的前提下将Hadoop集群顺利的升级到Hadoop2.2.0版本,本文主要介绍如何从Hadoop1.x(本博客用到的是hadoop-0.20.2-cdh3u4)版本的集群顺利地升级到Hadoop2.2.0。友情提示:请在读下文之间认真 w397090770 11年前 (2013-12-02) 12568℃ 2评论8喜欢
由于项目需要,需要在集群中安装好Zookeeper,这里我选择最新版本的Zookeeper3.4.5。 ZooKeeper是Hadoop的正式子项目,它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统 w397090770 10年前 (2014-01-20) 9425℃ 6评论8喜欢
本书于2017-07由Packt Publishing出版,作者Christopher Bourez,全书440页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Get familiar with Theano and deep learningProvide examples in supervised, unsupervised, generative, or reinforcement learning.Discover the main principles for designing efficient deep learning nets: convolut zz~~ 7年前 (2017-08-23) 2369℃ 0评论8喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive的数据分为表数据和元 w397090770 10年前 (2013-12-18) 14842℃ 0评论22喜欢
在 Apache 软件基金会近期发布的年度报告中,Apache Flink 再次跻身最活跃项目前 5 名!该项目最新发布的 1.14.0 版本同样体现了其非凡的活跃力,囊括了来自超过 200 名贡献者的 1000 余项贡献。整个社区为项目的推进付出了持之以恒的努力,我们引以为傲。新版本在 SQL API、更多连接器支持、Checkpoint 机制、PyFlink 等多个方面带来了大 zz~~ 3年前 (2021-10-09) 867℃ 0评论2喜欢
Flink Forward 是由 Apache 官方授权,Apache Flink China社区支持,有来自阿里巴巴,Ververica(Apache Flink 商业母公司)、腾讯、Google、Airbnb以及 Uber 等公司参加的国际型会议。旨在汇集大数据领域一流人才共同探讨新一代大数据计算引擎技术。通过参会不仅可以了解到Flink社区的最新动态和发展计划,还可以了解到国内外一线大厂围绕Flink生 w397090770 10年前 (2014-07-21) 44748℃ 55评论28喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事 Hive内部自带了许多的服务,我们可以 w397090770 10年前 (2014-02-24) 18886℃ 1评论10喜欢
什么是数据迁移Apache Kafka 对于数据迁移的官方说法是分区重分配。即重新分配分区在集群的分布情况。官方提供了kafka-reassign-partitions.sh脚本来执行分区重分配操作。其底层实现主要有如下三步: 通过副本复制的机制将老节点上的分区搬迁到新的节点上。 然后再将Leader切换到新的节点。 最后删除老节点上的分区。重分 zz~~ 3年前 (2021-09-24) 674℃ 0评论4喜欢
io.file.buffer.size hadoop访问文件的IO操作都需要通过代码库。因此,在很多情况下,io.file.buffer.size都被用来设置缓存的大小。不论是对硬盘或者是网络操作来讲,较大的缓存都可以提供更高的数据传输,但这也就意味着更大的内存消耗和延迟。这个参数要设置为系统页面大小的倍数,以byte为单位,默认值是4KB,一般情况下,可以 w397090770 10年前 (2014-04-01) 30122℃ 2评论14喜欢
一、介绍 FairScheduler是一个资源分配方式,在整个时间线上,所有的applications平均的获取资源。Hadoop NextGen能够调度多种类型的资源。默认情况下,FairScheduler只是对内存资源做公平的调度(分配)。当集群中只有一个application运行时,那么此application占用这个集群资源。当其他的applications提交后,那些释放的资源将会被分配给新的 w397090770 8年前 (2015-12-03) 11922℃ 12评论15喜欢
在 《HBase Rowkey 设计指南》 文章中,我们介绍了避免数据热点的三种比较常见方法:加盐 - Salting哈希 - Hashing反转 - Reversing其中在加盐(Salting)的方法里面是这么描述的:给 Rowkey 分配一个随机前缀以使得它和之前排序不同。但是在 Rowkey 前面加了随机前缀,那么我们怎么将这些数据读出来呢?我将分三篇文章来介绍如何 w397090770 5年前 (2019-02-24) 4591℃ 0评论10喜欢
首先非常感谢大家访问支持本博客,但是由于这些天访问人数的增加导致同一时刻访问本博客的人也增加,从而超过本博客服务器限制的并发数(100),这样使得本博客经常出现以下信息Bad Request (Invalid Hostname) 由于资金有限,所以选择了价格比较便宜的服务器,所以无法保证本博客100%在线。所以如果博客出现了Bad Requ w397090770 10年前 (2014-11-13) 3709℃ 3评论3喜欢
如果你正在按照 《将 MySQL 的全量数据导入到 Apache Solr 中》 文章介绍的步骤来将 MySQL 里面的数据导入到 Solr 中,但是在创建 Core/Collection 的时候出现了以下的异常[code lang="bash"]2018-08-02 07:56:17.527 INFO (qtp817348612-15) [ x:mysql2solr] o.a.s.m.r.SolrJmxReporter Closing reporter [org.apache.solr.metrics.reporters.SolrJmxReporter@47d9861c: rootName = null, domain = solr.cor w397090770 6年前 (2018-08-07) 1024℃ 0评论2喜欢
Apache CarbonData 是一种新的融合存储解决方案,利用先进的列式存储,索引,压缩和编码技术提高计算效率,从而加快查询速度,其查询速度比 PetaBytes 数据快一个数量级。 鉴于目前使用 Apache CarbonData 用户越来越多,其中就包含了大量的中国用户,这些中国用户可能有很多人英文不是特别好,或者没那么多时间去看英文文档。基于 w397090770 6年前 (2018-05-09) 10774℃ 0评论22喜欢
Apache Spark 1.3.0引入了Direct API,利用Kafka的低层次API从Kafka集群中读取数据,并且在Spark Streaming系统里面维护偏移量相关的信息,并且通过这种方式去实现零数据丢失(zero data loss)相比使用基于Receiver的方法要高效。但是因为是Spark Streaming系统自己维护Kafka的读偏移量,而Spark Streaming系统并没有将这个消费的偏移量发送到Zookeeper中, w397090770 9年前 (2015-06-02) 25585℃ 36评论22喜欢














![[电子书]Deep Learning with Theano PDF下载](https://www.iteblog.com/pic/books/Deep_Learning_with_Theano_iteblog.png)